Exploring the feasibility of conversational diagnostic AI in a real-world clinical study
March 11, 2026
Mike Schaekermann, Research Lead, Google Research, and Alan Karthikesalingam, Director/Principal Scientist, Google DeepMind
We present insights from a first-of-its-kind research study in partnership with Beth Israel Deaconess Medical Center towards prospective real-world assessment of AMIE, our conversational medical AI for clinical reasoning and dialogue.
Quick links
AI systems capable of clinical reasoning and dialogue have the potential to dramatically increase access to medical expertise and care while giving physicians back time with their patients. Yet, bringing these innovations to life demands a safety-centric, evidence-based approach. In recent years, our work with the Articulate Medical Intelligence Explorer (AMIE) has explored the possibilities of conversational medical AI, starting with demonstrations of its diagnostic capabilities in simulated settings when assisting clinicians in diagnostic challenges and interacting with patient actors. However, as underscored by a recent review of AI in clinical medicine, translating these systems into clinical practice requires assessment in real-world workflows.
In our new work, “A prospective clinical feasibility study of a conversational diagnostic AI in an ambulatory primary care clinic”, we are sharing the results of a crucial milestone in our evidence roadmap: a prospective, single-center feasibility study conducted in partnership with Beth Israel Deaconess Medical Center (BIDMC). In this pre-registered, IRB approved, prospective study, we specifically explored how AMIE can help gather information from a patient before a new ambulatory primary care visit and understand how both clinicians and patients perceive the use of an AI system within the care experience. This research represents our first step in moving beyond synthetic scenarios to rigorously evaluate AMIE's safety and practical feasibility when interacting with patients in a real-world clinical environment.
Testing AMIE in a real-world clinical workflow
Translating AI systems into clinical practice requires assessment in real-world care delivery settings with strict safety oversight. In this prospective, single-arm feasibility study, AMIE was deployed to conduct pre-visit clinical history taking with patients prior to their ambulatory primary care appointments at an academic medical center.
The clinical setting focused on patients booked to receive care for new, non-emergency, episodic complaints, either in person or via a telehealth platform. Patients were invited to participate in the study during their appointment booking process, where they were given ample time to review the study’s IRB-approved protocols and were assured that their decision on whether or not to participate would not impact their care.
Study participants interacted with the AMIE system via a secure web-link before their physical consultation. These AI-driven text-chats were overseen by a physician using a live video-call with screen-sharing. The overseeing physician (referred to as “AI supervisor” in the diagram below), was trained to be ready to intervene if required, based on a pre-defined set of structured safety criteria, providing a safeguard for clinical safety and protocol adherence.
Before the patient attended the urgent care appointment with their doctor, the system generated a transcript and summary to provide their clinician with a comprehensive overview of the pre-visit interaction. Oversight is a common tool for ensuring safety in clinical practice. For example, clinicians-in-training will have the opportunity to communicate with patients under close physician supervision and with patients’ consent so that they may obtain feedback from supervising doctors. Similarly, in this study, the AMIE system generated a transcript and summary before the participating patient attended their PCP appointment that, with patients’ consent, was provided to their clinician. The summary included an overview of the pre-visit interaction for the doctor to review.
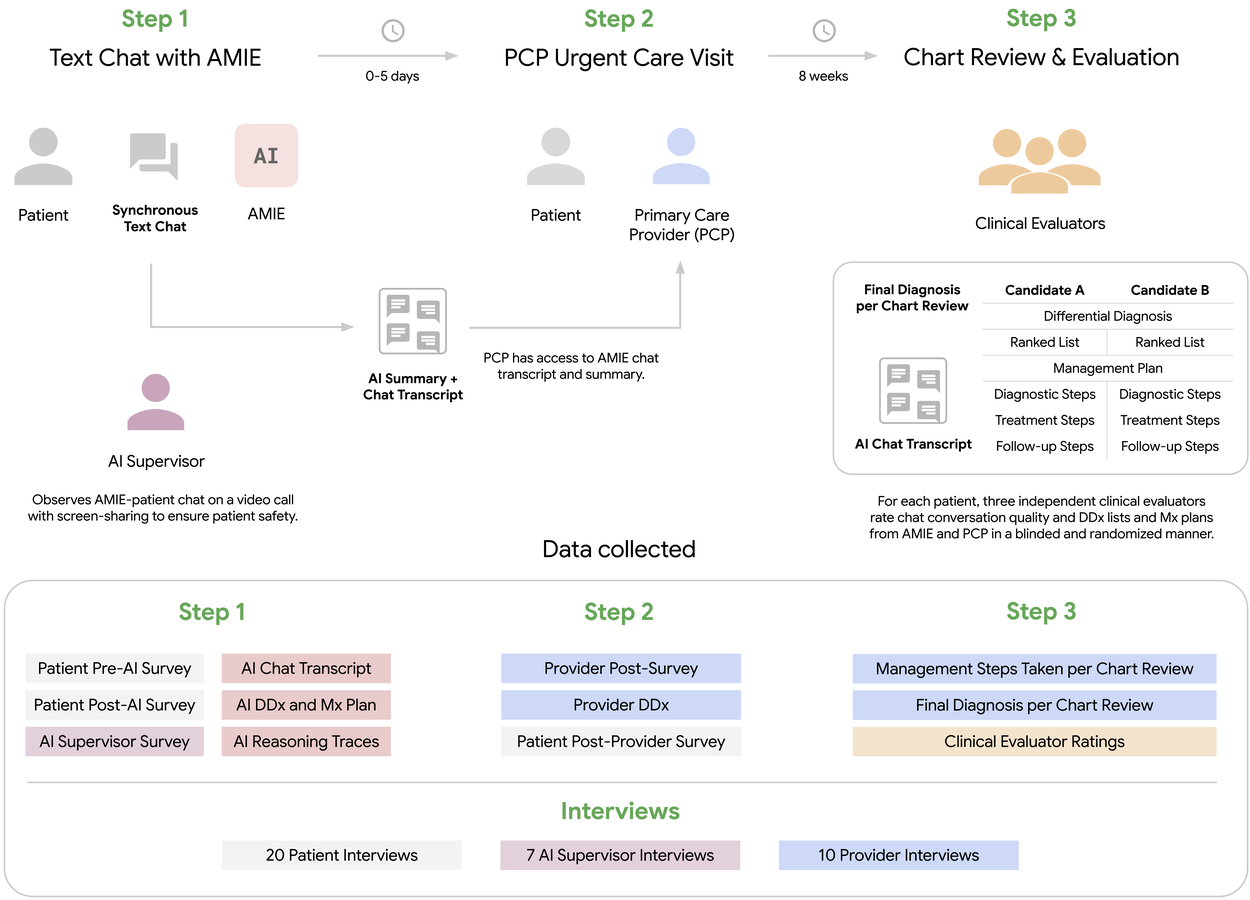
Patients in this study first interacted with AMIE before they saw their primary care provider (PCP). The AMIE chat transcript and summary were provided to the PCP prior to the urgent care visit. A separate group of clinical evaluators assessed the quality of the AMIE chat, as well as differential diagnoses and management plans from AMIE and PCPs.
Learnings on safety, performance, trust and experience
Evaluating a conversational medical AI system in a real-world clinical workflow requires assessing various criteria and involving perspectives from patients and clinicians alike. We assessed the system's performance across multiple dimensions, including its safety and feasibility in a real-world deployment, its clinical reasoning capabilities, and how the interaction was perceived by both patients and clinicians. The results demonstrate that supervised deployment of AMIE for this task is not only feasible, but also conversationally safe and well-received.

In our study, zero safety stops were required by human AI supervisors, patients’ trust in AI increased after interaction with AMIE, and AMIE and PCPs were rated to be on par with respect to their overall management plan (Mx plan) and differential diagnosis (DDx) quality by a panel of clinical evaluators. AMIE’s DDx accuracy was high, including for the subset of patient cases where the final diagnosis was confirmed by a diagnostic test.
Participation
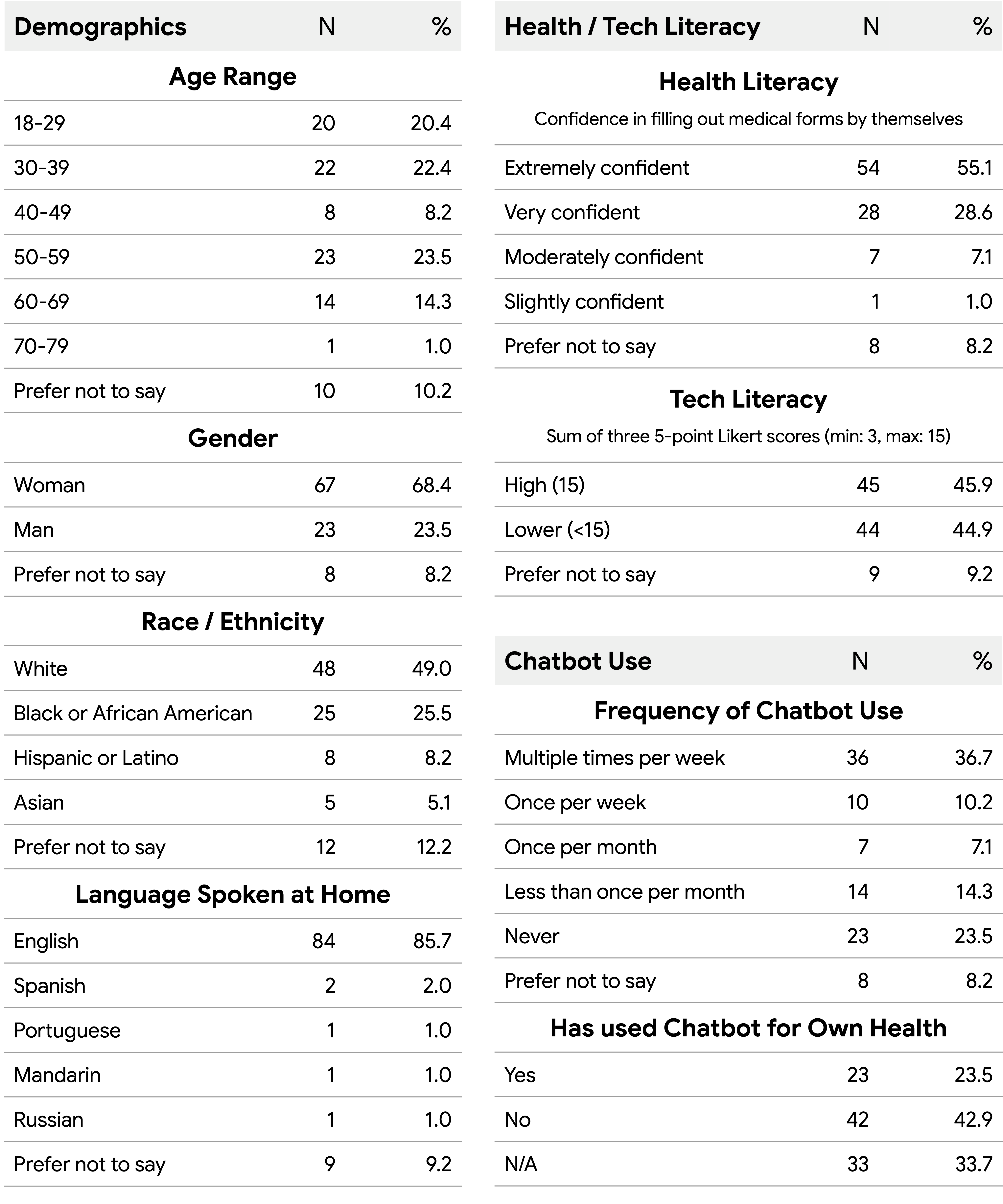
The study involved 100 adult patients who completed a pre-visit interaction with AMIE. Of these, 98 attended their scheduled ambulatory primary care appointment. The patient sample included diverse age and racial/ethnic groups, as well as people with varying levels of health and tech literacy. Compared to the total 1,452 urgent care visits during the study period, patients participating in this study tended to skew towards younger ages as over half of total urgent care visits at the clinic during the study period were over the age of 60. However, during the study period, the total urgent care visit population trended towards female and white populations, which was consistent with the patient sample in this study.

The patient sample in this prospective clinical study included various age and racial/ethnic groups, as well as people with varying levels of health and tech literacy, and differing pre-existing experience using chatbots.
Safety
Human AI supervisors overseeing AMIE–patient interactions were trained to trigger a safety stop if one of four pre-specified safety criteria were met:
- Immediate concern for harm to self or others
- Significant emotional distress exhibited by the patient related to the AI interaction
- Potential for clinical harm identified by the supervisor based on the conversation
- Explicit request from the patient to end the session
Across all AMIE-patient interactions in this study, zero safety stops were required by the human AI supervisors, providing evidence for the conversational safety of AMIE in this real-world deployment.
Clinical reasoning
To assess diagnostic and management capabilities, a panel of clinical evaluators who were not involved with urgent care consultations rated differential diagnoses and management plans from AMIE and PCPs in a blinded and randomized manner. Each patient case was reviewed and graded by a set of three clinical evaluators and results are based on aggregated gradings using the median across three evaluators per case.
Blinded assessment of differential diagnoses (DDx) and management (Mx) plans suggested similar overall DDx and Mx plan quality between AMIE and PCPs, without significant differences for DDx as well as the appropriateness and safety of Mx plans. However, PCPs outperformed AMIE in the practicality and cost effectiveness of Mx plans. AMIE’s DDx included the final diagnosis, per chart review 8 weeks post-encounter, in 90% of cases, with 75% top-3 accuracy, and remained high for the subset of 46 patients where the final diagnosis was confirmed by a diagnostic test (laboratory, microbiological, pathological, or imaging).
These gaps on the cost effectiveness and practicality of management plans are expected given the differing contexts in which AMIE and PCPs were reasoning. AMIE did not have access to the patient's EHR, did not have the ability to perform a physical exam, or integrate multimodal user input, such as the overall physical appearance of the patient. PCPs may have been able to use this rich context advantage and their experience working in the specific clinical environment to construct a more cost-effective and practical management plan.
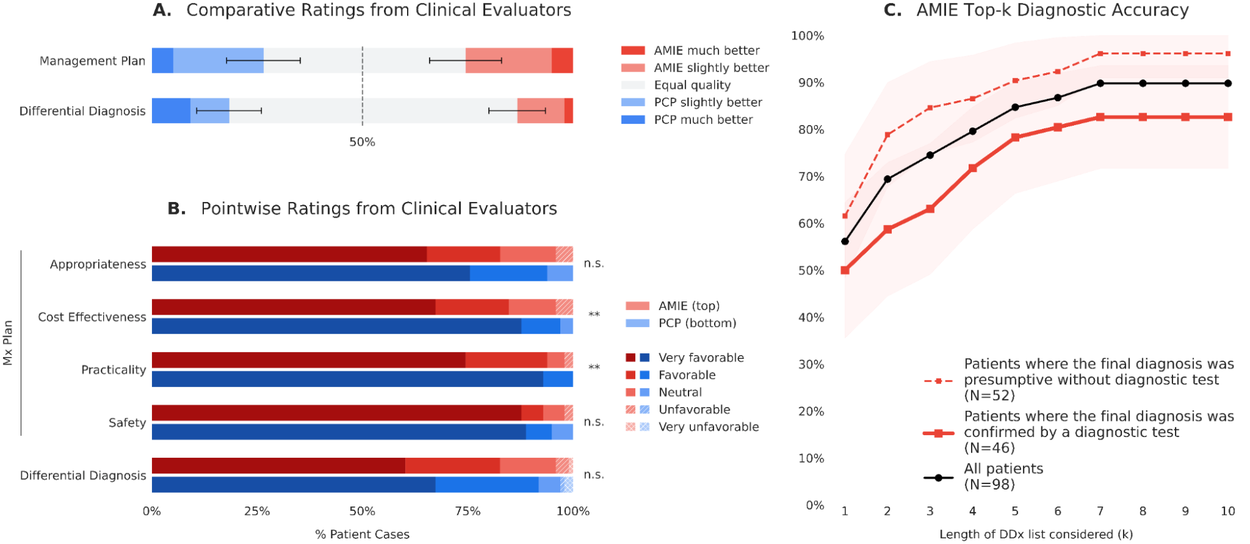
Clinical reasoning capabilities including the quality of differential diagnoses and management plans from AMIE and PCPs, rated by a panel of clinical evaluators (A and B), as well as AMIE’s diagnostic accuracy as compared to the final diagnosis per chart review 8 weeks post-encounter (C).
To further evaluate diagnostic performance, we compared AMIE's differential diagnoses to a final diagnosis, which was established through a chart review conducted eight weeks after the PCP urgent care visit. AMIE successfully matched the final diagnosis within its top 7 diagnostic possibilities in 90% of cases. Furthermore, the system accurately identified the final diagnosis as its single most likely diagnosis in 56% of all cases evaluated.
To better understand these diagnostic capabilities, we also performed a subgroup analysis based on how the final diagnosis was ultimately established. Cases were categorized by whether the final diagnosis was presumptive (made by the PCP without further testing) or more confirmatory (confirmed by a specialist referral or a diagnostic test, such as a laboratory, microbiological, pathological, or imaging result). While AMIE maintained strong diagnostic accuracy for cases requiring objective confirmation via tests or specialists, the system's overall accuracy tended even higher for cases where the final diagnosis was based purely on the PCP's presumptive diagnosis.
Trust and experience
Beyond demonstrating safety, we also probed patient and provider experiences with AMIE. Patients completed the General Attitudes towards AI Scale (GAAIS) prior to interacting with AMIE, after interacting with AMIE, and after the consultation with their provider. Attitudes shifted more positive after interacting with AMIE and remained at an elevated level after seeing the provider. This change was statistically significant for both sub-scales — perceived utility and concerns around AI — and the overall scale.
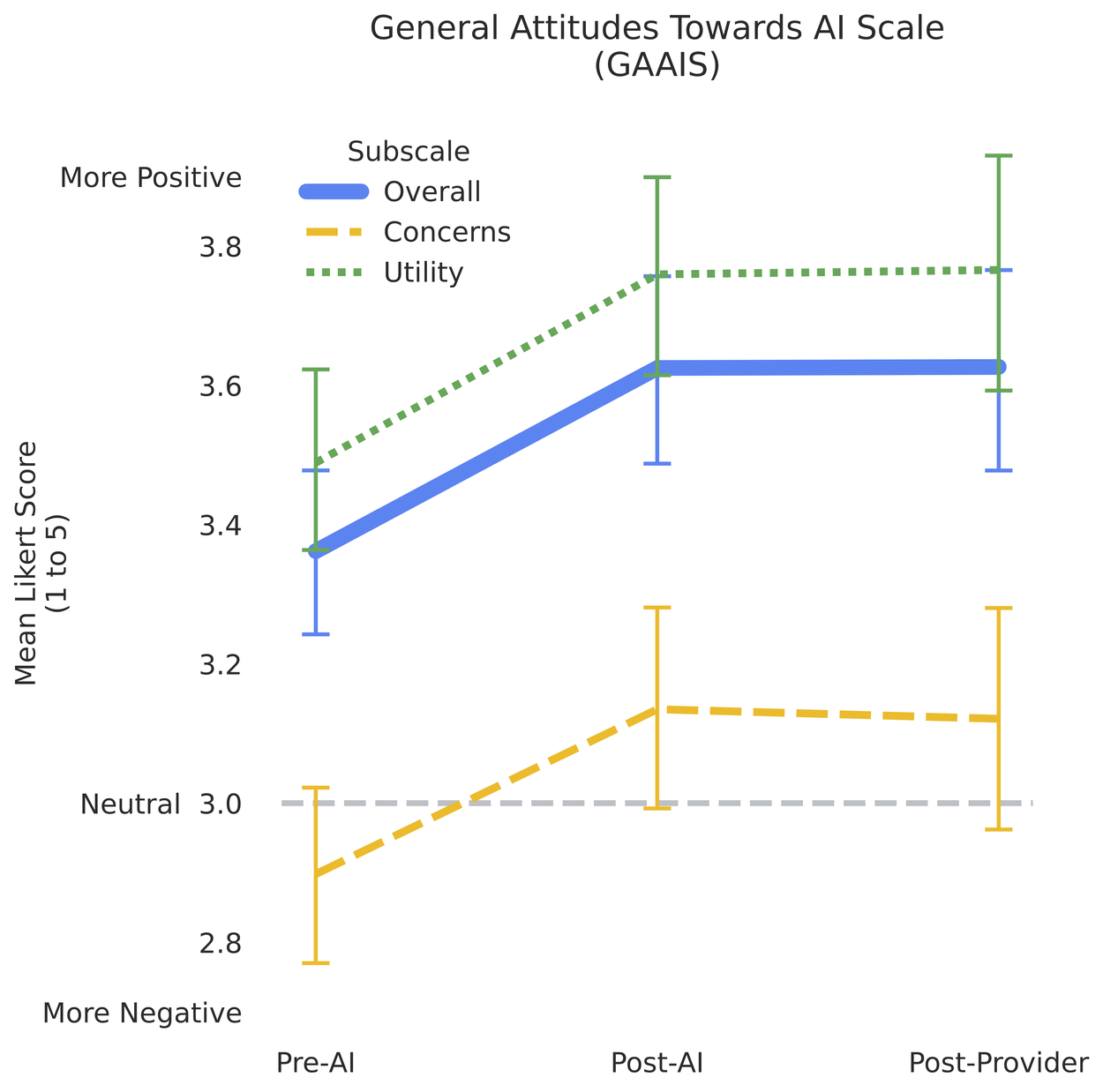
Patient attitudes towards AI improved significantly after interacting with AMIE and remained elevated after seeing the provider.
Patient surveys and interviews indicated high satisfaction, with patients generally finding AMIE to be polite and effective at explaining medical conditions.
Clinicians reviewing AMIE's pre-visit transcripts found them useful, noting a perceived positive impact on visit preparedness. In qualitative interviews, PCPs noted that AMIE helped shift the visit dynamic from simple data gathering to data verification, allowing for more collaborative conversations and shared decision-making.

Ratings of AMIE’s conversation quality from the patient perspective (pink) and the perspective of clinical evaluators (teal).
Limitations and future directions
This study provides evidence suggesting the initial feasibility, safety, and user acceptance of conversational medical AI as a helpful tool in a real-world setting, representing a crucial step towards potential clinical translation. This study was a single-center feasibility study, and it showed some nuanced limitations and areas for improvement highlighting the importance of our safe and responsible approach to real-world evidence generation.
First, the study's text-only chat interface does not fully capture the rich, multimodal nature of clinical care. Future systems could benefit from integrating voice or video interactions, or video capabilities to better capture non-verbal cues and physical findings. Second, this study did not include controlled comparisons and therefore does not support quantitative claims on the efficacy of this intervention compared to a baseline workflow. Future studies may build on the findings from this work to quantify impact of AI in healthcare systems with controlled comparisons. Finally, this study did not exhaustively explore how factors like pre-existing health literacy, tech literacy and familiarity with chatbots influence the interaction with AI systems in clinical settings; understanding how these systems are perceived by broader populations and how interaction is affected by such factors remains an essential area for future research.
In this study, the interaction between AMIE and patients was overseen “live” by a dedicated physician, which represents one paradigm for maximizing patient safety. We have also explored possibilities for asynchronous workflows in our OSCE studies of physician-centered oversight.
To conclude, this work provides important empirical evidence that conversational AI can be safe and helpful for patients and providers in the real world, and we look forward to further assessing the utility and impact of these systems in forthcoming larger studies with controlled comparisons.
Acknowledgements
This project was an extensive collaboration between Beth Israel Deaconess Medical Center, Beth Israel Lahey Health, and many teams at Google Research, Google DeepMind and Google for Health. We thank our many collaborators, sponsors and reviewers of this work. We are grateful to the many contributions from our co-authors throughout this research: Peter Brodeur, Jacob M. Koshy, Anil Palepu, Khaled Saab, Ava Homiar, Roma Ruparel, Charles Wu, Ryutaro Tanno, Joseph Xu, Amy Wang, David Stutz, Hannah M. Ferrera, David Barrett, Lindsey Crowley, Jihyeon Lee, Spencer E. Rittner, Ellery Wulczyn, Selena K. Zhang, Elahe Vedadi, Christine G. Kohn, Kavita Kulkarni, Vinay Kadiyala, Sara Mahdavi, Wendy Du, Jessica Williams, David Feinbloom, Renee Wong, Tao Tu, Petar Sirkovic, Alessio Orlandi, Christopher Semturs, Yun Liu, Juraj Gottweis, Dale R. Webster, Joëlle Barral, Katherine Chou, Pushmeet Kohli, Avinatan Hassidim, Yossi Matias, James Manyika, Rob Fields, Jonathan X. Li, Marc L. Cohen, Vivek Natarajan, Adam Rodman.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence