
Evaluating progress of LLMs on scientific problem-solving
April 3, 2025
Subhashini Venugopalan, Research Scientist, Google Research
We introduce CURIE, a scientific long-Context Understanding, Reasoning and Information Extraction benchmark to measure the potential of large language models in scientific problem-solving and assisting scientists in realistic workflows.
Quick links
The advancement of science relies on the ability to build upon the collective knowledge accumulated in scientific literature, requiring not only deep domain expertise and reasoning skills, but also the capacity to apply that knowledge within the context of a given problem. Large language models (LLMs) have already shown remarkable breadth of knowledge across a wide spectrum of domains, including commonsense reasoning, language understanding, coding, math and scientific question-answering. As LLMs transition from merely surfacing knowledge to reasoning and actively solving problems, their application to scientific endeavors holds immense potential, promising to revolutionize how research is conducted and understood.
Realizing this potential will require rigorous evaluation of LLMs' capabilities in handling the complexities inherent in scientific tasks. It will be necessary to measure models’ capacity to understand and reason about long-form, context-rich scientific information, including multimodal content in figures and tables, and, crucially, to understand the reasoning processes models use to select the appropriate tools to solve the problems at hand. However, current LLM benchmarks on science are often focused on short form questions and multiple choice responses, testing primarily the recollection of knowledge and to a lesser extent, the ability to reason.
To address this gap, we propose several new benchmarks and datasets to measure the ability of LLMs in seeking information and solving problems where additional context is available. Our paper, “CURIE: Evaluating LLMs on Multitask Scientific Long-Context Understanding and Reasoning”, set to appear at ICLR 2025, focuses on tasks in six scientific disciplines that test long-context understanding, reasoning, information extraction and aggregation capabilities. In a similar vein, at NeurIPS 2024, we introduced “SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers”, which evaluated the ability of LLMs to ground their responses to queries in figures and tables from scientific papers. Alongside this dataset, we also created a benchmark test set and evaluated multimodal LLMs on the task. Additionally, at the MATH-AI workshop at NeurIPS 2024, we shared “FEABench: Evaluating Language Models on Multiphysics Reasoning Ability” in which we proposed a task to measure the ability of LLM agents to simulate, reason, and solve physics, mathematics and engineering problems using finite element analysis (FEA) software.
CURIE, a multitask benchmark for scientific reasoning
CURIE is designed to evaluate LLMs on scientific problem solving across six disciplines: materials science, condensed matter physics, quantum computing, geospatial analysis, biodiversity, and proteins. It includes ten challenging tasks that require domain expertise, comprehension of long-context information, and multi-step reasoning. The tasks in CURIE cover a range of scientific workflows, including information extraction, reasoning, concept tracking, aggregation, algebraic manipulation, multimodal understanding, and cross-domain expertise, all performed within the context of full-length scientific papers. By requiring LLMs to be adept at such realistic tasks, CURIE aims to measure their potential in assisting scientists in their daily workflows.

The CURIE benchmark encompasses 10 tasks, with a total of 580 input and solution pairs based on 429 research documents across six diverse scientific disciplines: materials science, theoretical condensed matter physics, quantum computing, geospatial analysis, biodiversity, and proteins – covering both experimental and theoretical aspects of scientific research.
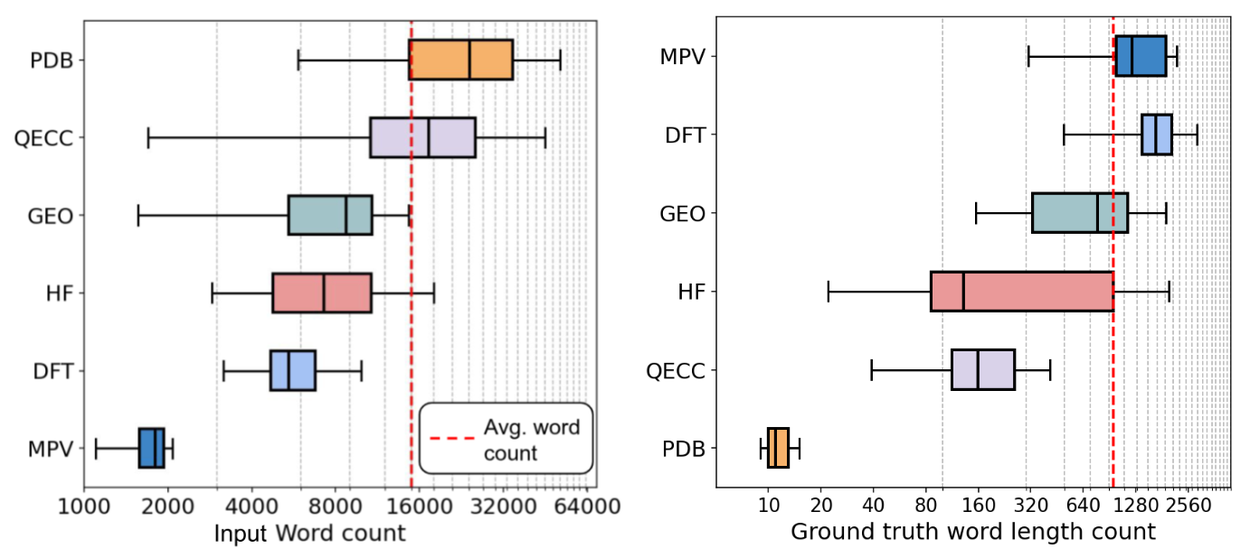
Left: The average length of the input queries in CURIE is about 15k words. Right: The ground truth responses contain on average 954 words.
Domain experts played a vital role in every phase of the benchmark development. First, they helped define and identify tasks that accurately represent real-world scientific workflows and helped source relevant research papers from their domains. They then assisted in creating detailed ground truth answers, prioritizing accuracy, nuance, and comprehensiveness. Finally, they quantified task difficulty by rating each example based on key features. We then selected evaluation metrics and confirmed their correlation with the experts' subjective assessments of model responses compared to the ground truth answers. The table below gives an overview of the specific tasks the benchmark encompasses.
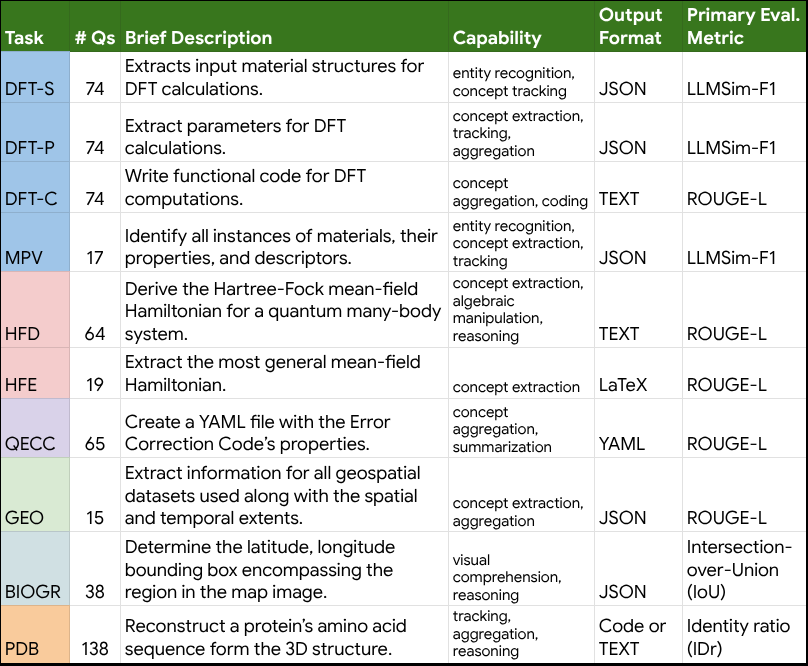
Brief description of the tasks in CURIE that models are to perform when given the context of a single research document (often a full-length paper). Also shown are the capabilities measured and the evaluation metrics.
Programmatic and model-based evaluations
Tasks in CURIE are varied and have ground-truth annotations in mixed and heterogeneous form, e.g., as JSONs, latex equations, YAML files, or free-form text. Evaluating free-form generation is challenging because answers are often descriptive, and even when a format is specified, as in most of our cases, the response to each field can have differing forms. For example, materials grid points may sometimes be specified as “[p, q, r]” and at other times as “p × q × r”. Hence, in addition to the programmatic evaluation metrics, such as ROUGE-L, intersection-over-inion (used for BIOGR), and identity ratio (used in PDB), we propose two model-based evaluation metrics.
(1) LMScore: Prompts an LLM asking how closely the predictions match ground truth on a 3-point scale: “good” if the prediction has few minor errors, “okay” if there are many minor errors, and “bad” if there are major errors. We consider the weighted average of the log-likelihood scores of the tokens to produce a final confidence.
(2) LLMSim: Is used for retrieval tasks where we ask the model to exhaustively extract many details, e.g., descriptors, properties and values of materials from a research document, and provide as output an unordered list of dictionaries or records. We use a chain-of-thought (CoT) prompt that asks the LLM to look at each ground-truth record and identify the predicted records that correctly match each field (key) and value of the ground truth. Once we match the ground-truth records with predicted records, we can then measure precision and recall for the retrieval task, and compute the mean average precision, recall and F1 scores across all documents.
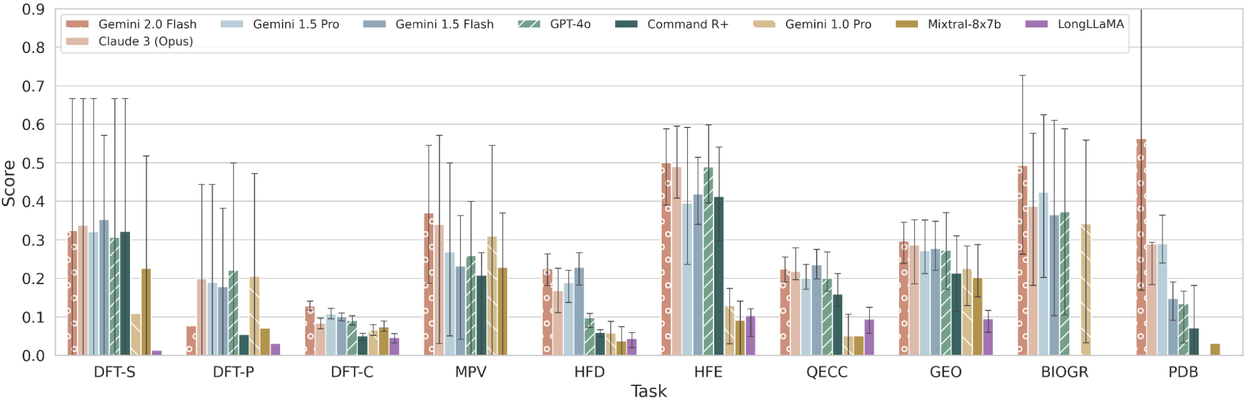
Per task normalized scores of various LLMs on the CURIE benchmark to measure performance on 10 long-context tasks (see table above) requiring expertise across six scientific disciplines. Higher is better.
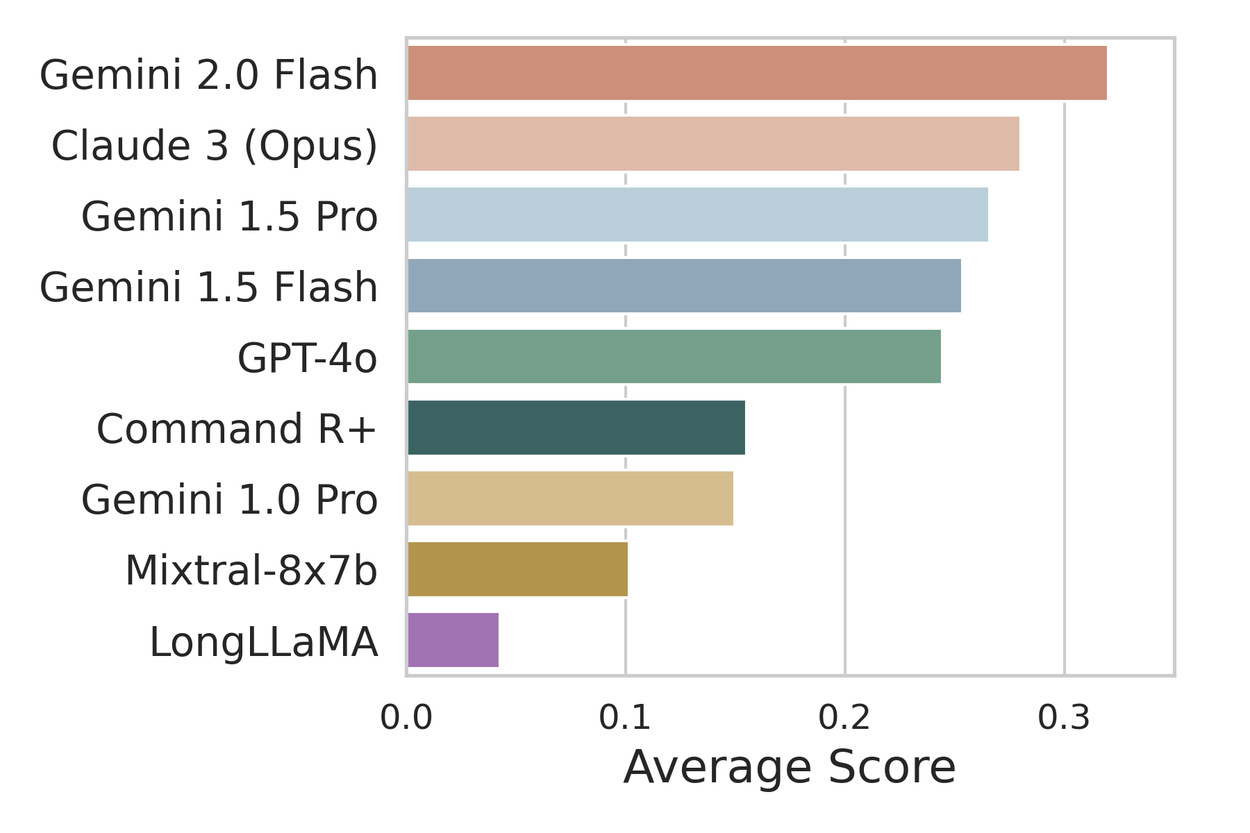
Average normalized performance of long-context LLMs across the 10 tasks from six scientific domains in CURIE.
We evaluated popular long-context closed- and open-weight models on CURIE and found that there is substantial room for improvement across all models and tasks, in particular on DFT, MPV and GEO tasks that require exhaustive retrieval of multiple values and aggregation. The paper includes detailed analysis of the results from experts. Of note is that experts found model responses promising, particularly in extracting details from a scientific paper, grouping them appropriately, and generating responses in a desired format. Overall, improving the effectiveness of LLMs on such tasks will augment and accelerate scientists in their workflows.
SPIQA: A dataset for multimodal question answering on scientific papers
While CURIE evaluates scientific reasoning over long texts in different domains, comprehending multimodal content in scientific articles presents additional challenges. Often, key insights, motivation, and a simplified overview of the scientific methods are presented in meticulously crafted figures and tables. Thus, to independently evaluate the ability of LLMs to simultaneously reason over multiple figures and associated text in a scientific article, we introduce the Scientific Paper Image Question Answering (SPIQA) dataset and benchmark. Using SPIQA, we test both the multimodal and long-context capabilities of LLMs.
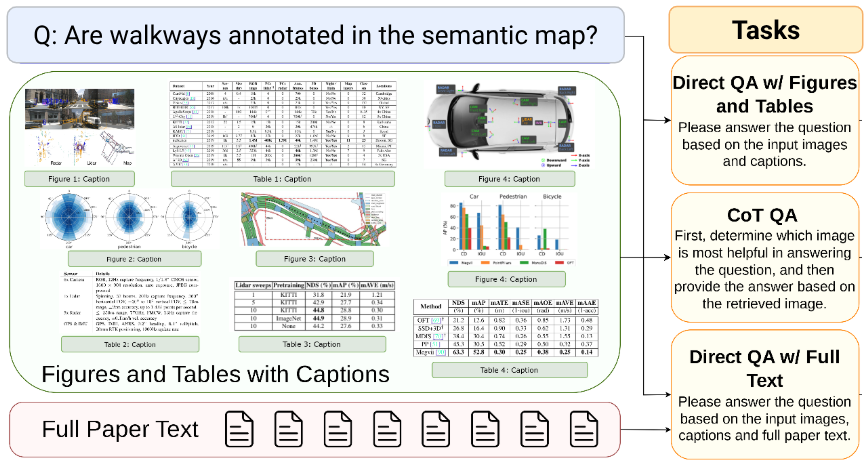
Given a question anchored in a figure or table from a research paper, we evaluate the capabilities of multimodal LLMs in comprehending information in multiple figures, tables, and the paper text to ground its responses in the right figure or table.
In SPIQA, we leverage the breadth of expertise and ability of multimodal LLMs to understand individual figures and tables to curate a large dataset of 270k question and answer pairs. The questions involve multiple images covering plots, charts, tables, schematic diagrams, and result visualizations.
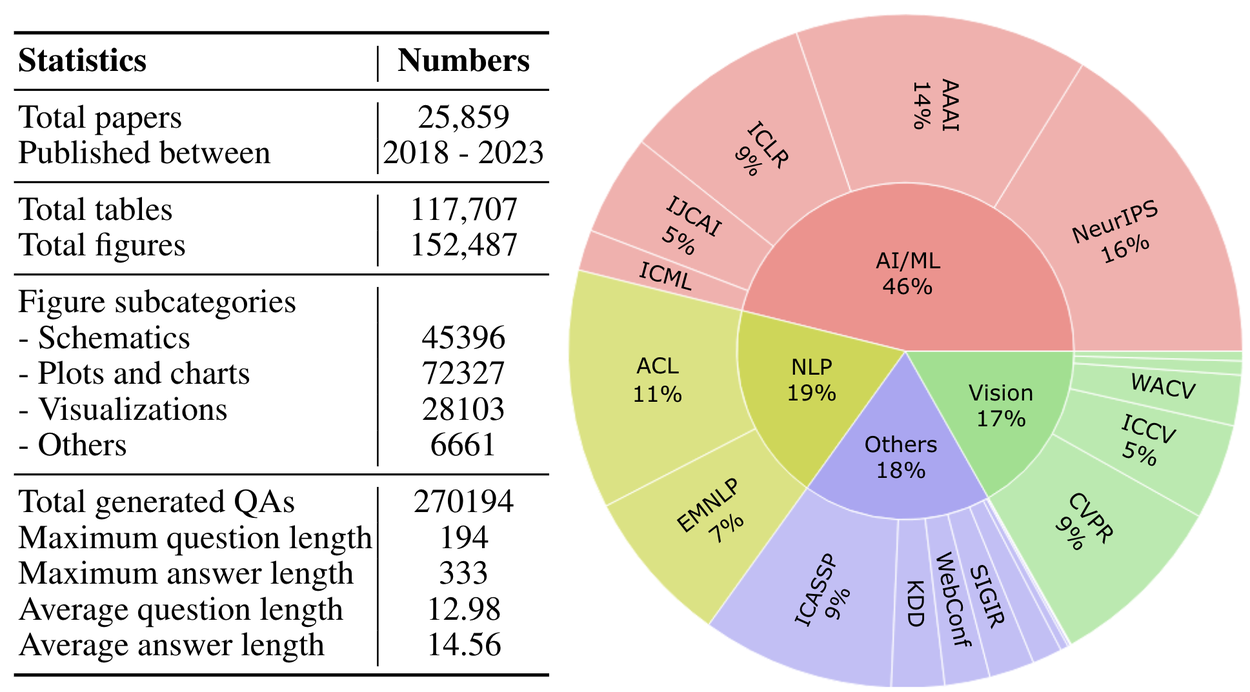
Distribution of the sub-domains of the ~25k computer science papers on which the SPIQA dataset is curated. SPIQA consists of 270,194 question and answer pairs on 152k figures and 117k tables where the answer to each query is grounded in a figure or a table.
Through extensive experiments we evaluate 12 prominent foundational models on the task of grounding responses in images of a scientific paper. Additionally, we show significant performance gains by fine-tuning two open-source systems (LLaVA and InstructBLIP) on the SPIQA training set, which reveals promising avenues for improving open source multimodal LLMs on scientific image understanding and reasoning.
FEABench
Yet another essential requirement in engineering and science is building precise simulations of the real world and invoking software tools to answer quantitative problems. With FEABench, we investigate the ability of LLMs to solve engineering modeling problems end-to-end by reasoning over natural language problem descriptions and operating COMSOL Multiphysics®, a finite element analysis (FEA) software, to compute the answers. The benchmark consists of a set of 15 manually verified problems (FEABench Gold), as well as a larger set of algorithmically parsed problems, that could potentially be used to tune models. The problems in this benchmark prove to be challenging enough that the LLMs and agents we tested were not able to completely and correctly solve any problem.

Left: Illustrative example showing the specifications for a heat transfer problem in the dataset. Right: Distribution of FEABench Gold problems by physics domain.
Benchmarks: Towards building trustworthy scientific AI
Links to download the datasets and evaluation code for CURIE, SPIQA, and FEABench are provided on GitHub along with an expanded version of the BIOGR (biodiversity) dataset. These benchmarks represent a significant effort to create challenging and realistic evaluations for AI systems, focusing on long-context understanding, multimodal reasoning, and the integration of computational tools. We hope these encourage and support the community in developing more rigorous evaluations on scientific tasks, thereby facilitating the advancement of AI-assisted scientific discovery. Contributions to the GitHub repositories, especially those related to enhancing evaluation metrics, are welcomed.
Acknowledgements
We thank the several domain experts who contributed to these benchmarks. We would like to specifically acknowledge the valuable contributions of student researchers Nayantara Mudur, Shraman Pramanick, Maria Tikanovskaya, and Martyna Plomecka; and sincerely appreciate the contributions from our domain expert collaborators Eun-Ah Kim, Haining Pan, Victor V. Albert, Brian Rohr, Michael J. Statt, Gowoon Cheon, Yasaman Bahri, Zahra Shamsi, Xuejian Ma, Shutong Li, Dan Morris, and Drew Purves. We also thank other members of the project including Hao Cui, Peter Norgaard, Paul Raccuglia, Pranesh Srinivasan, Elise Kleeman, Ruth Alcantara, Matthew Abraham, Muqthar Mohammad, Ean Phing VanLee, Chenfei Jiang, Elizabeth Dorfman, Michael P Brenner, Viren Jain and Sameera Ponda for their critical and thoughtful contributions to the benchmarks, as well as encouragement and support.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing






