Evaluating and enhancing probabilistic reasoning in language models
October 21, 2024
Xin Liu and Daniel McDuff, Research Scientists, Google Health
Language models are capable of remarkably complex linguistic tasks. However, numerical reasoning is an area in which they frequently struggle. We systematically evaluate the probabilistic reasoning capabilities of LLMs and show that they can make more accurate inferences about distributions aided by the incorporation of real-world context and simplified assumptions.
Quick links
Large language models (LLMs) have shown remarkable capabilities in understanding and generating text for a variety of linguistic tasks, including summarization of complex documents and zero-shot inference in specialist domains like medicine. At the same time, LLMs struggle with tasks that require numerical reasoning capabilities, such as calculating probabilities. Difficulties handling numbers may stem from the fact that most models rely on autoregressive next token prediction pretext tasks during training, which might not be suitable for mathematical operations, or simply because a limited number of numerical reasoning tasks are included in the model’s training corpora. Nevertheless, it is known that performance can be improved using prompt techniques, indicating that relevant knowledge may already exist within LLMs.
Probabilistic reasoning is a frequently used form of numerical reasoning that contextualizes samples within distributions. It allows people to not have to represent every detail of every sample that they observe, instead they can have the data summarized with a small number of parameters that describe the distribution. Understanding data distributions is important in many contexts. For example, in population health it can help determine if a person’s behavior is normative (e.g., is sleeping 8 hours unusual for a college-aged student?). In climatology, understanding temperature or precipitation distributions for a given day of the year at a particular location is important to determine whether or not an observation is typical or unexpected.
Research has shown that some probabilistic reasoning processes lead to superior performance; for example, people are more likely to accurately answer questions about statistical properties when they estimate the full distribution first. Yet, there are limited examples using LLMs to evaluate or improve probabilistic reasoning.
In “What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, to be presented at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), we evaluate and enhance the probabilistic reasoning capabilities of LLMs using idealized and real-world statistical distributions. First, we perform a systematic evaluation of state-of-the-art LLMs using three tasks: estimating percentiles, drawing samples, and calculating probabilities. Then, we evaluate three ways to provide context to LLMs: anchoring examples from within a distribution or family of distributions, adding real-world context, and utilizing summary statistics on which to base a normal approximation. We show that LLMs can make inferences about distributions and can be further aided by the incorporation of real-world context, example shots, and simplified assumptions. Our work includes a new benchmark distribution dataset with associated question-answer pairs.
Large language models are capable of probabilistic reasoning.
Probabilistic reasoning with LLMs
To understand the probabilistic reasoning capabilities of three state-of-the-art LLMs (Gemini, GPT family models), we define three distinct tasks: estimating percentiles, drawing samples, and calculating probabilities. These tasks reflect key aspects of interpreting probability distributions, such as understanding where a sample falls within a distribution (percentiles), generating representative data (sampling), and assessing the likelihood of outcomes (probabilities). By testing these abilities, we aimed to assess how well LLMs can reason over both idealized and real-world distributions.
Since no publicly available dataset existed for LLM-based probabilistic reasoning, we developed a new dataset combining real-world and idealized distributions. For the real-world distributions, data was collected from three domains: health, finance, and climate. The health data were de-identified and sampled from 100,000 Fitbit users in the U.S. aged 18–65 who consented to their data being used for research. These data included metrics like step count, resting heart rate, sleep duration, and exercise minutes. Financial data were obtained from the U.S. Census Bureau’s American Community Survey, and climate data came from NOAA’s Global Historical Climatology Network. The datasets were manually curated to ensure relevant filtering (e.g., erroneous data removal).
In addition, we programmatically generated idealized distributions using Python libraries to complement the real-world data and better test the probabilistic reasoning capabilities of language models. While we generated 12 idealized distributions, this blog post will focus on three: normal, log normal, and power law. See the paper to learn about all of the generated distributions.
We evaluated Gemini, GPT family models on the three tasks using 12 idealized distributions and 12 real-world distributions. To enhance probabilistic reasoning, we explored three strategies for providing more context to the LLMs:
- Anchoring examples from within a distribution or its family: We provided anchoring examples from the same distribution or related distributions. For instance, when estimating percentiles for a normal distribution, we included examples from the same distribution with different value–percentile pairs, allowing the model to interpolate and make more accurate predictions.
- Adding real-world context: We added real-world context by introducing domain-specific data, such as U.S. rental prices from the American Community Survey when estimating the percentile of monthly rent values. This enabled the model to reason using practical, real-world information.
- Leveraging summary statistics to approximate a normal distribution: We used summary statistics and normal approximations to simplify complex distributions. For example, income data, which typically follows a power law distribution, was approximated as normal to help the model make reasonably accurate predictions despite the complexity of the actual, underlying distribution.
Results
Our findings with both idealized and real-world distributions demonstrate that LLMs are capable of performing probabilistic reasoning, although their success varies based on the task and type of distribution. For example, all LLMs performed well on uniform and normal distributions when estimating percentiles but struggled with calculating probabilities and drawing samples, particularly in zero-shot settings. Anchoring examples from within a distribution or its family proved to be an effective strategy, allowing models to interpolate between in-context examples. Performance significantly improved when we provided a few examples — percentile estimation accuracy increased by 59.14%, sampling by 55.26%, and probability calculation by 70.13%. Additionally, the models exhibited complex reasoning abilities, not just reciting the nearest example but instead performing some form of interpolation, which further enhanced performance.
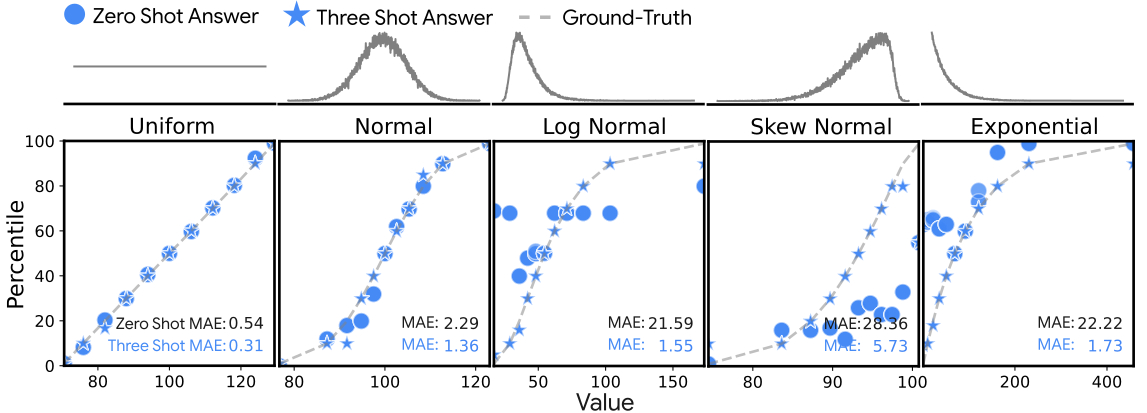
To illustrate the dramatic improvement of few-shot prompting we show the percentile estimates from Gemini for different values of a set of distributions (uniform, normal, log-normal, skew-normal and exponential) below. The circles represent the zero-shot estimates and stars the three-shot estimates. Points closer to the dashed line are better. The quantitative performance measure by mean absolute error (MAE) is a lot smaller.
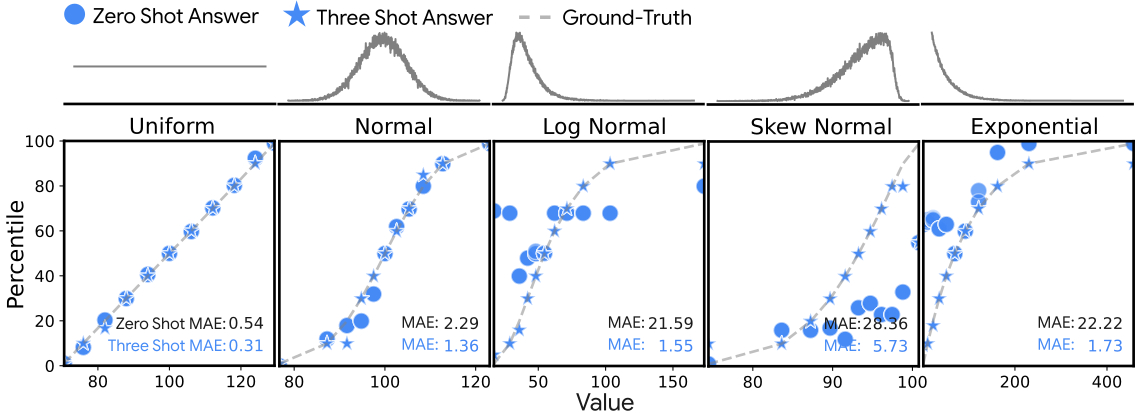
Results of estimating percentiles within some idealized distributions. Providing as few as three-shot examples dramatically improves inference accuracy. The top row illustrates the forms of these idealized distributions.
Further experiments involving real-world distributions from health, finance, and climate domains explored the effects of real-world context and simplified assumptions. We found that incorporating real-world context, such as information on data sources and time periods, led to significant improvements in model performance, suggesting LLMs can effectively draw from their knowledge base to enhance probabilistic reasoning. Simplified assumptions, such as approximating non-normal real-world distributions (like income or precipitation) as normal using summary statistics, also improved performance, even when the assumptions were not fully accurate. This suggests that LLMs can benefit from efficient parametric approximations, allowing them to generalize and reason more effectively across both idealized and real-world settings.
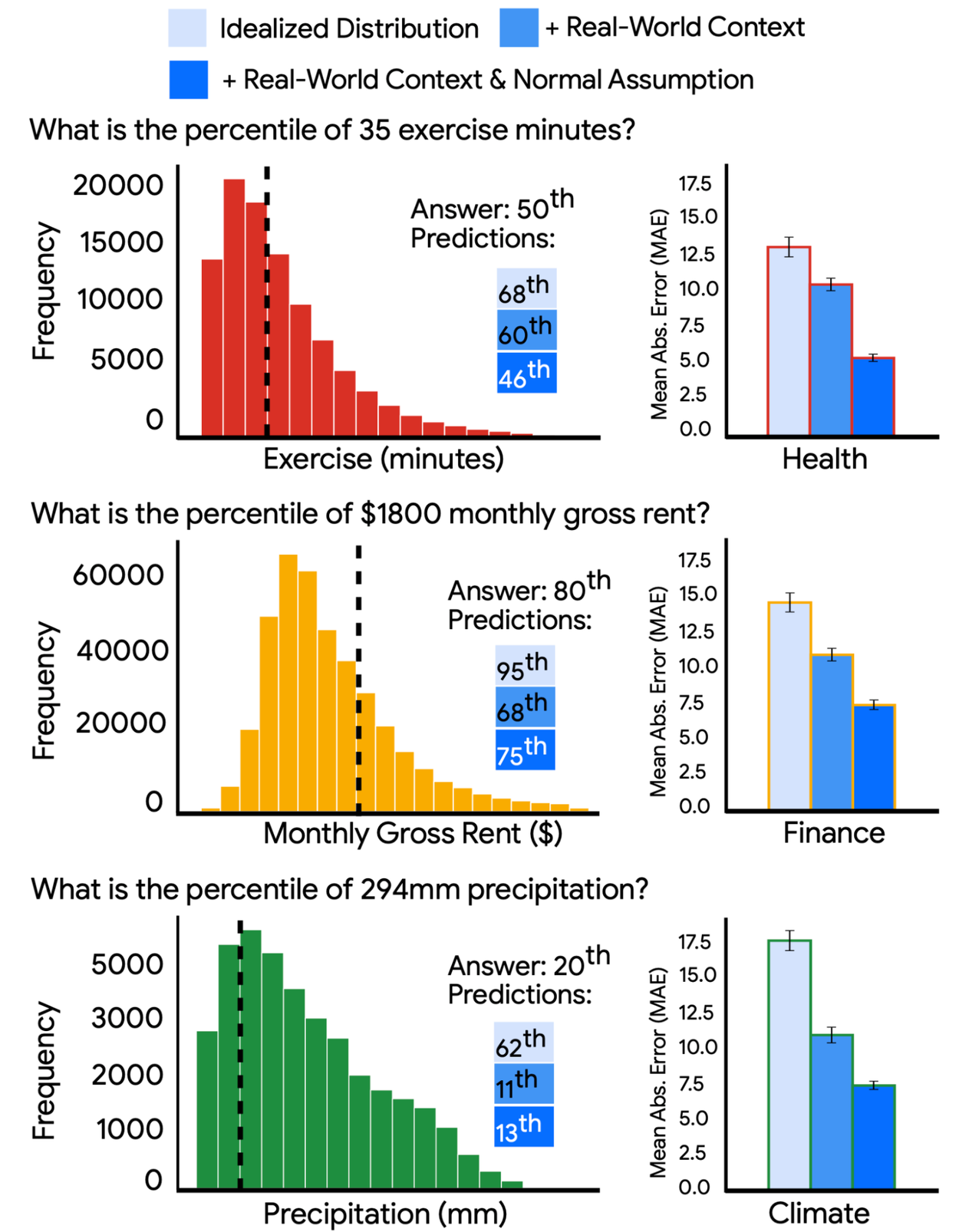
LLMs can make inferences about distributions and can be aided by the incorporation of real-world context, few-shot examples and simplified normal assumptions.
Conclusion
Our research demonstrates that LLMs possess the ability to reason probabilistically, suggesting that there is some internal representation that enables modeling or interpolation from distribution parameters. Furthermore, this capability to do probabilistic reasoning can be improved using examples within distribution, context, and simplified assumptions such as a normal approximation. Despite these promising signs, there's still plenty of room for improvement, particularly when dealing with complex and non-normal distributions. We are excited about the potential of LLMs for probabilistic reasoning, and we believe our work lays the foundation for future research in this area. We hope this research will facilitate further research and development of LLMs that are more adept at understanding and reasoning about probability, ultimately enabling LLMs to be more useful, safer, and more reliable.
Acknowledgements
This research was conducted by Akshay Paruchuri, Jake Garrison, Shun Liao, John Hernandez, Jacob Sunshine, Tim Althoff, Xin Liu, and Daniel McDuff.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence
