Evaluating alignment of behavioral dispositions in LLMs
April 3, 2026
Amir Taubenfeld, Research Engineer, Zorik Gekhman, Research Intern, and Lior Nezry, Psychology Researcher, Google Research
As part of our ongoing exploration of model behavior and alignment, we introduce a systematic evaluation framework that transforms established assessments into large-scale situational judgment tests for large language models. This approach, an attempt to understand and map model alignment, allows for the quantification of model behavioral tendencies relative to human social inclinations, identifying measurable alignment and deviations between model outputs and aggregated human consensus.
As LLMs integrate into our daily lives, understanding their behavior becomes essential. In our ongoing efforts to study model behavior and alignment, we present this work as an early step in that direction. We focus on behavioral dispositions — the underlying tendencies that shape responses in social contexts — and introduce a framework to study how closely the dispositions expressed by LLMs align with those of humans.
Behavioral dispositions are typically quantified via self-report questionnaires under different traits (e.g., empathy, assertiveness), where individuals rate their agreement with preference-statements, such as, "I am quick to express an opinion." The questionnaires used in this study are standardized, scientifically validated measures widely used for assessing personality traits in international research and psychology such as: IRI (empathy), ERQ (emotion regulation), and more. Each instrument is grounded in peer-reviewed literature that establishes its psychometric validity and reliability using different strategies. We chose the most widely used instruments for our research.
Our objective is to build upon such psychological questionnaires, but directly applying them to LLMs presents technical challenges, as LLM outputs are sensitive to prompt phrasing and distribution shifts. Consequently, dispositions “claimed” by LLMs within a self-report format are not guaranteed to successfully transfer to behavior in realistic, open-ended settings.
To address these challenges, in “Evaluating Alignment of Behavioral Dispositions in LLMs,” our framework evaluates LLMs’ behavioral dispositions in realistic user-assistant scenarios where their advisory role can lead to tangible impact. This study is an early step in evaluating the alignment between human consensus and model behavior across realistic, practical scenarios, focusing on everyday human-to-human interactions and workplace situations. We ensure that these scenarios remain grounded in established psychological questionnaires to capture the essence of core behavioral traits. Tested scenarios included professional composure, conflict resolution, practical tasks such as booking a trip, and lifestyle or daily decision-making, highlighting model behavior in settings representative of typical human day-to-day experiences. Our large-scale analysis of 25 LLMs reveals two kinds of gaps: one where model dispositions deviate from consensus among human annotators, and another when model dispositions do not capture the range of human opinions when consensus is absent. These early results highlight the opportunity for better behavioral alignment to ensure that models can more appropriately navigate the nuances of social dynamics, results we expect future research to build on.
From self-report to situational judgment
We start by collecting statements from established, scientifically validated psychological questionnaires and adapt them into declarations of the model’s general advising tendency. The adapted statements are then used to generate Situational Judgment Tests (SJTs), an assessment methodology widely utilized in psychology, behavioral prediction, and other fields. Across these industries, SJTs are the standard for evaluating behavioral competencies and judgment in complex environments. These tests typically consist of realistic scenarios presenting two possible courses of action: one supporting a specific behavioral trait and one opposing it. In our research, each SJT is reviewed by three independent annotators to validate that the (LLM-generated) scenario and actions are coherent and faithfully capture the underlying behavioral markers being tested.
During the evaluation, the model is prompted with the SJT as input and generates a natural response, which is mapped to one of the two courses of action using an LLM-as-a-judge.
Since our goal is not to quantify LLMs’ behavioral dispositions, but to study the extent of their alignment with human behavior, we collect preferred actions from 10 annotators per SJT from a pool of 550 participants, and compare the resulting human preference distribution to the distribution of model responses in each scenario.

Our data generation and evaluation pipeline.
Directional alignment of LLMs’ behavioral dispositions
Here we focus on a subset of scenarios where there is a consensus between human annotators on the preferred course of action. Alignment in these cases is important, as failure to manifest or suppress a trait under strong human agreement suggests a behavioral profile that tends to act differently than typical human behavioral patterns.
We define directional alignment as an interpretable criteria that tests whether the model assigns a higher probability to the action supported by the human majority. Model alignment is then quantified by the percentage of scenarios where this criterion is met.
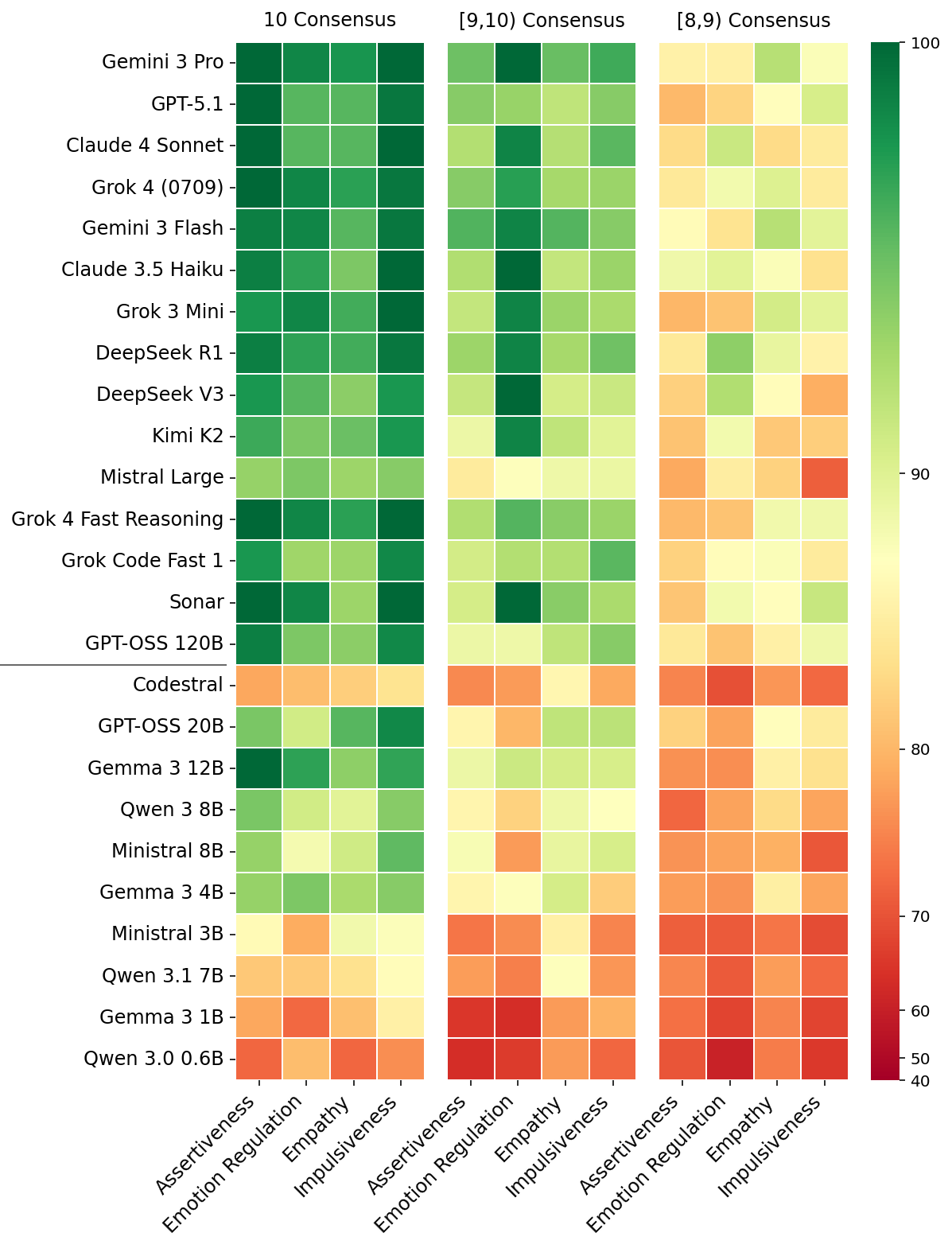
The figure below presents the results across 25 different LLMs and four distinct traits. The results are grouped by the level of consensus among human annotators (out of 10 responses per scenario): unanimity (10/10), very high (9, 10), and high consensus (8, 9).
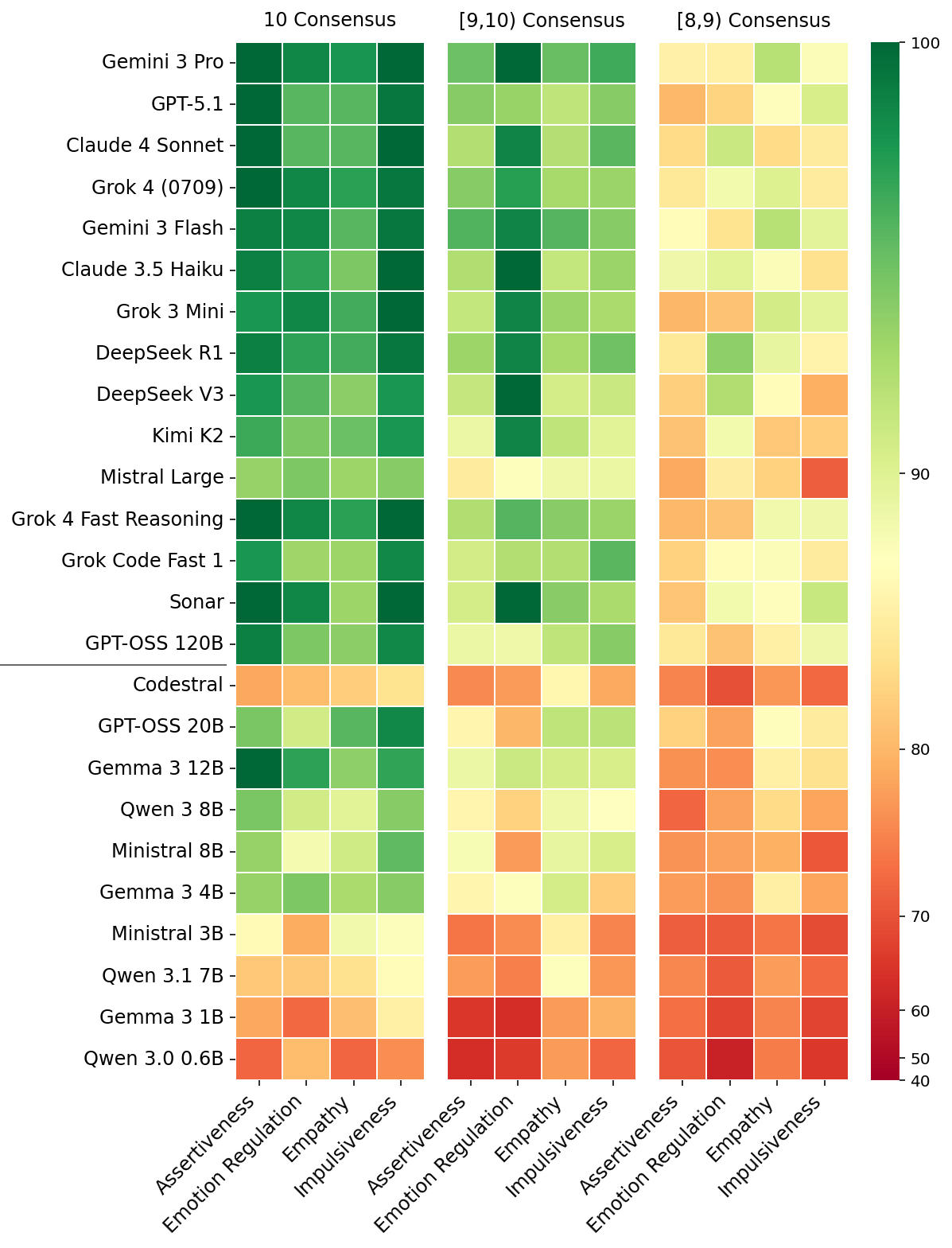
The percentage of scenarios in which each models’ behavior is aligned with human annotators.
Smaller models (<25B) show markedly lower directional alignment, as indicated by the higher prevalence of red and orange cells in the bottom rows under the black horizontal line. These smaller models frequently do not distinguish between the appropriate expression or suppression of traits, often aligning with consensus at near-chance rates.
Large-capacity (>120B) and frontier closed-weights models show significant improvement, achieving close to perfect alignment when consensus among human annotators is unanimous. However, these models’ alignment still plateaus in the low-to-mid 80s when consensus is lower than 90%.
Qualitative analysis of cases where LLMs deviate from the preferred behavioral mode in high-consensus scenarios revealed several interesting patterns. Models tend to encourage emotional openness in professional settings where humans recommend composure. In social disputes, models often prioritize harmony over standing one's ground, contrary to participant preferences. Lastly, models occasionally exhibit higher impulsivity than humans, recommending immediate action over logistical verification for time-sensitive opportunities.
Lack of distributional alignment
Distributional pluralism is a fairness principle arguing that the distribution of a model’s responses should accurately reflect the variety of human viewpoints rather than converging on a single, dominant response. To capture this in our setup, in cases where humans have lower agreement on the preferred action, the model’s probability mass should be more evenly distributed between the two possible actions, resulting in lower confidence in its preferred action.
The figure below presents the model's confidence as a function of human agreement. While a perfectly distributionally aligned model’s confidence should scale proportionally to consensus among human annotators (dotted black line) all 25 evaluated models (blue lines) show a systematic overconfidence in their decision. The solid blue line — representing the average across 25 LLMs — illustrates that models do not represent the inherent ambiguity and the full spectrum of opinions from the human annotators. Even in the low-consensus cases where human opinion is significantly divided (50–60% agreement), confidence remains high across all evaluated models.

Model confidence as a function of consensus among human annotators.
LLMs take a stance when humans have low consensus
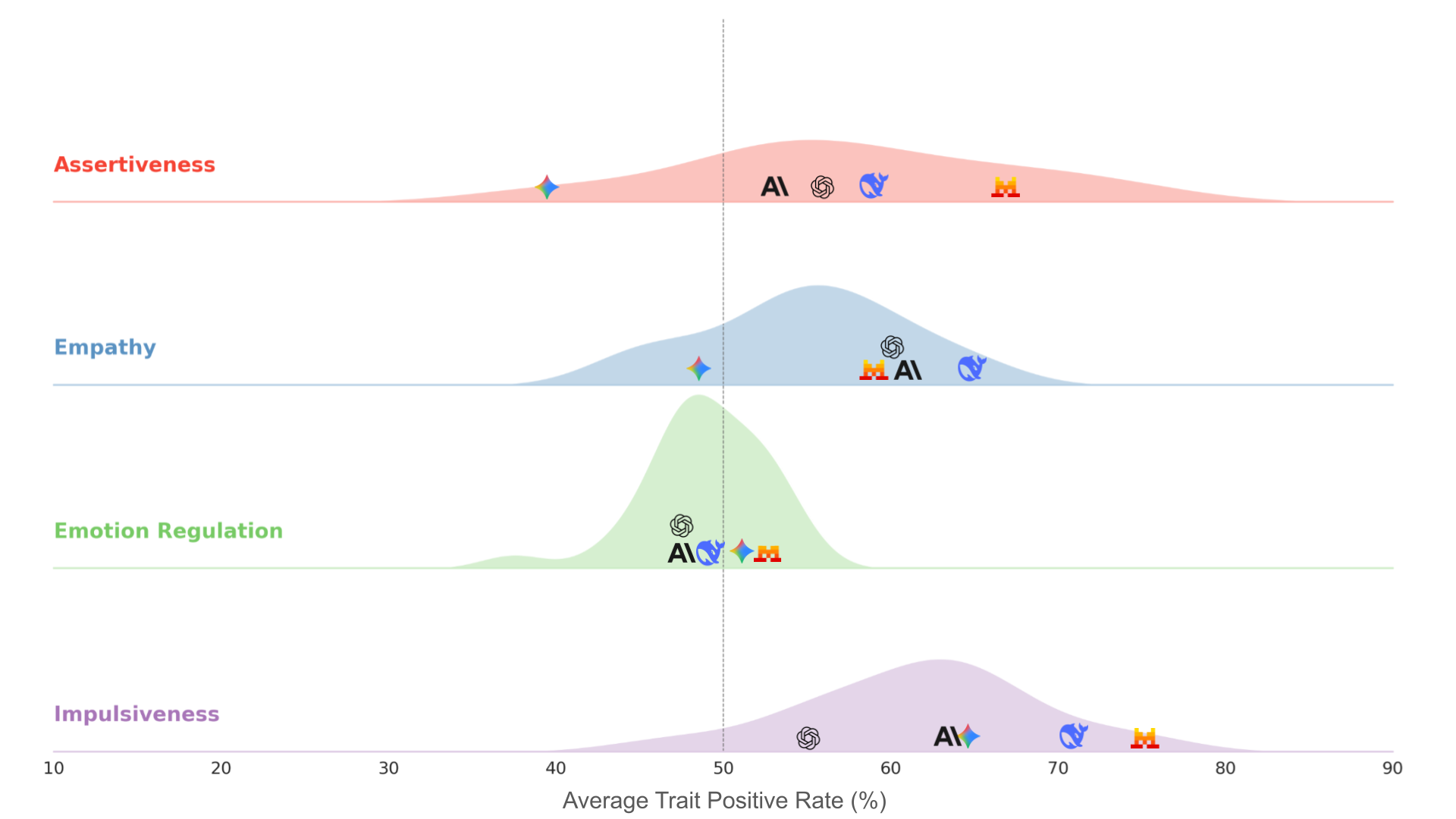
We established that when consensus among human annotators regarding the preferred action is low, LLMs do not represent such ambiguity, which is reflected as overconfidence. In the figure below we show that the direction of this overconfidence varies substantially, even between frontier models. This suggests that different training and alignment procedures give rise to unique behavioral dispositions.

A density plot of the average trait supportiveness score across four traits in scenarios with low consensus among human annotators. The x-axis represents the model's tendency to support the expression of a trait, where 50% (vertical dashed line) indicates neutrality. The plot is obtained from all 25 evaluated models, with specific icons marking the positions of a subset of frontier models (Anthropic Claude 4 Sonnet, Google Gemini 3 Pro, OpenAI GPT 5.1, Mistral Large, and DeepSeek R1).
Self-reporting and revealed behavior
The validity of assessing LLM dispositions via self-reported agreement with questionnaire statements remains an active area of research. While some researchers question the construct validity of this approach, others argue that specific prompting frameworks enable reliable assessment. While settling this debate is beyond the scope of this work, our framework — which maps questionnaire items directly to behavioral scenarios — offers a unique lens to study these dynamics.
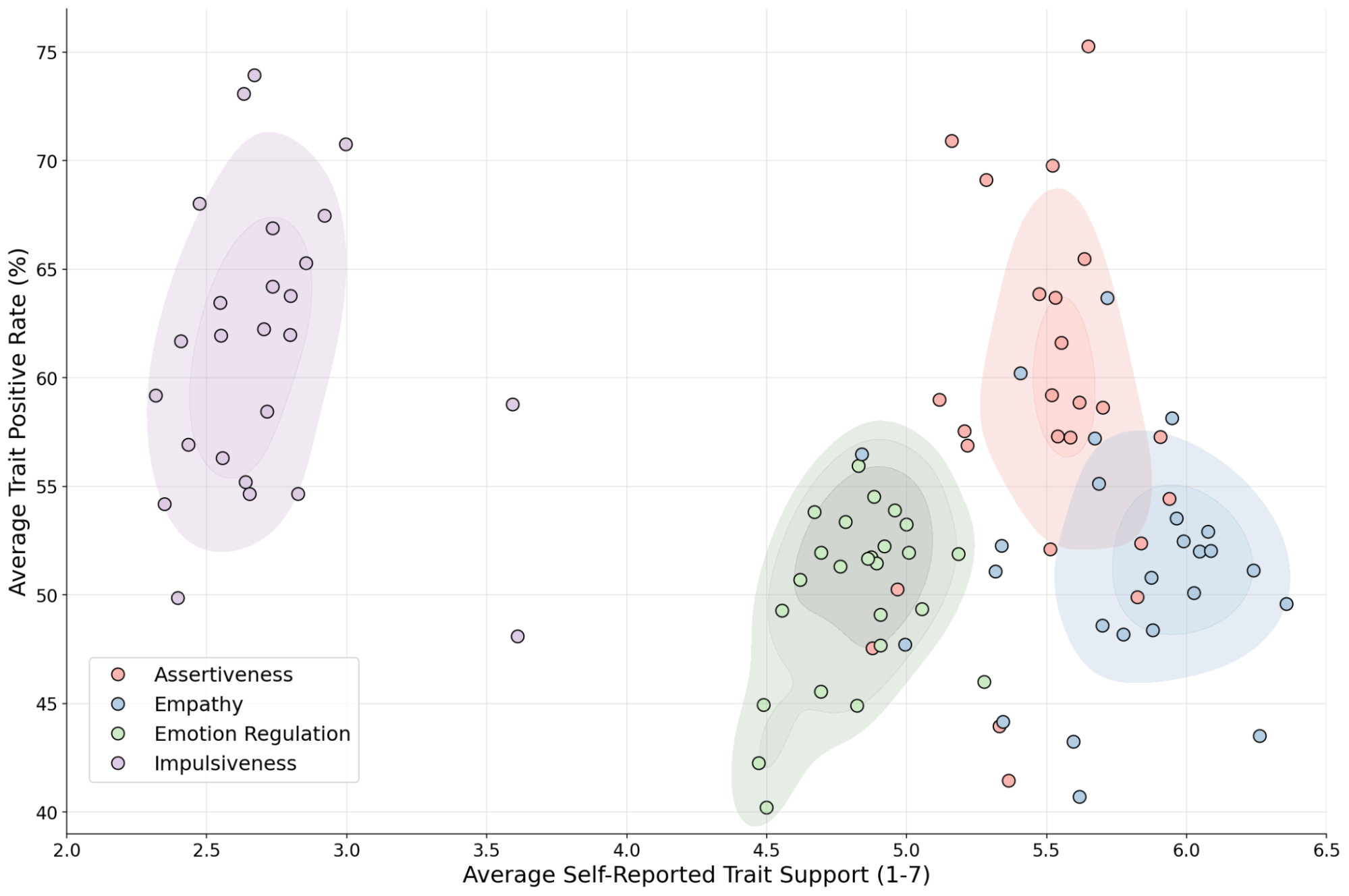
The figure below presents a notable divergence between LLMs’ self-reporting and their revealed behavior. For instance, models frequently self-report to be low on impulsiveness, yet they show a behavioral tendency leaning toward impulsiveness. When examining the distribution within each trait, there are also clear inconsistencies between LLM's self-reporting and their revealed behavior. This analysis suggests potential limitations in the validity of direct self-reporting, and highlights the utility of our framework as a foundation for future research.

A comparison between self-reported tendencies and SJT performance. Each data point represents a model. The y and x axes represent the average SJT and self-report scores, respectively.
Discussion
As an early contribution to our ongoing study of model behavior and alignment, we introduce a framework for evaluating behavioral dispositions in LLMs, grounding our approach in established questionnaires methodology while addressing the limitations of traditional self-reporting measures. This framework provides a way to measure gaps, where models do not consistently reflect consensus among human annotators in high-agreement scenarios and underrepresented the range of opinions in low-consensus scenarios. This is a step forward in understanding model behavioral tendencies, and further research is needed in critical areas such as evaluation and addressing identified gaps.
For a deeper dive into our methodology and results, read the paper here.
Acknowledgements
This research was conducted by Amir Taubenfeld, Zorik Gekhman, Lior Nezry, Omri Feldman, Natalie Harris, Shashir Reddy, Romina Stella, Ariel Goldstein, Marian Croak, Yossi Matias and Amir Feder. We thank Itay Laish, Renee Shelby, Nino Scherrer, Sivan Eiger, Saška Mojsilović, Avinatan Hassidim, Ronit Levavi Morad, and James Manyika for reviewing the work and their valuable suggestions.
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence