End-to-End, Transferable Deep RL for Graph Optimization
December 17, 2020
Posted by Yanqi Zhou and Sudip Roy, Research Scientists, Google Research
Quick links
An increasing number of applications are driven by large and complex neural networks trained on diverse sets of accelerators. This process is facilitated by ML compilers that map high-level computational graphs to low-level, device-specific executables. In doing so, ML compilers need to solve many optimization problems, including graph rewriting, assignment of operations on devices, operation fusion, layout and tiling of tensors, and scheduling. For example, in a device placement problem, the compiler needs to determine the mapping between operations in the computational graph to the target physical devices so that an objective function, such as training step time, can be minimized. The placement performance is determined by a mixture of intricate factors, including inter-device network bandwidth, peak device memory, co-location constraints, etc., making it challenging for heuristics or search-based algorithms, which typically settle for fast, but sub-optimal, solutions. Furthermore, heuristics are hard to develop and maintain, especially as newer model architectures emerge.
Recent attempts at using learning-based approaches have demonstrated promising results, but they have a number of limitations that make them infeasible to be deployed in practice. Firstly, these approaches do not easily generalize to unseen graphs, especially those arising from newer model architectures, and second, they have poor sample efficiency, leading to high resource consumption during training. Finally, they are only able to solve a single optimization task, and consequently, do not capture the dependencies across the tightly coupled optimization problems in the compilation stack.
In “Transferable Graph Optimizers for ML Compilers”, recently published as an oral paper at NeurIPS 2020, we propose an end-to-end, transferable deep reinforcement learning method for computational graph optimization (GO) that overcomes all of the above limitations. We demonstrate 33%-60% speedup on three graph optimization tasks compared to TensorFlow default optimization. On a diverse set of representative graphs consisting of up to 80,000 nodes, including Inception-v3, Transformer-XL, and WaveNet, GO achieves an average 21% improvement over expert optimization and an 18% improvement over the prior state of the art with 15x faster convergence.
Graph Optimization Problems in ML Compilers
There are three coupled optimization tasks that frequently arise in ML compilers, which we formulate as decision problems that can be solved using a learned policy. The decision problems for each of the tasks can be reframed as making a decision for each node in the computational graph.
The first optimization task is device placement, where the goal is to determine how best to assign the nodes of the graph to the physical devices on which it runs such that the end-to-end run time is minimized.
The second optimization task is operation scheduling. An operation in a computational graph is ready to run when its incoming tensors are present in the device memory. A frequently used scheduling strategy is to maintain a ready queue of operations for each device and schedule operations in first-in-first-out order. However, this scheduling strategy does not take into account the downstream operations placed on other devices that might be blocked by an operation, and often leads to schedules with underutilized devices. To find schedules that can keep track of such cross-device dependencies, our approach uses a priority-based scheduling algorithm that schedules operations in the ready queue based on the priority of each. Similar to device placement, operation scheduling can then be formulated as the problem of learning a policy that assigns a priority for each node in the graph to maximize a reward based on run time.
The third optimization task is operation fusion. For brevity we omit a detailed discussion of this problem here, and instead just note that similar to priority-based scheduling, operation fusion can also use a priority-based algorithm to decide which nodes to fuse. The goal of the policy network in this case is again to assign a priority for each node in the graph.
Finally, it is important to recognize that the decisions taken in each of the three optimization problems can affect the optimal decision for the other problems. For example, placing two nodes on two different devices effectively disables fusion and introduces a communication delay that can influence scheduling.
RL Policy Network Architecture
Our research presents GO, a deep RL framework that can be adapted to solve each of the aforementioned optimization problems — both individually as well as jointly. There are three key aspects of the proposed architecture:
First, we use graph neural networks (specifically GraphSAGE) to capture the topological information encoded in the computational graph. The inductive network of GraphSAGE leverages node attribute information to generalize to previously unseen graphs, which enables decision making for unseen data without incurring significant cost on training.
Second, computational graphs for many models often contain more than 10k nodes. Solving the optimization problems effectively over such large scales requires that the network is able to capture long-range dependencies between nodes. GO’s architecture includes a scalable attention network that uses segment-level recurrence to capture such long-range node dependencies.
Third, ML compilers need to solve optimization problems over a wide variety of graphs from different application domains. A naive strategy of training a shared policy network with heterogeneous graphs is unlikely to capture the idiosyncrasies of a particular class of graphs. To overcome this, GO uses a feature modulation mechanism that allows the network to specialize for specific graph types without increasing the number of parameters.
 |
| Overview of GO: An end-to-end graph policy network that combines graph embedding and sequential attention. |
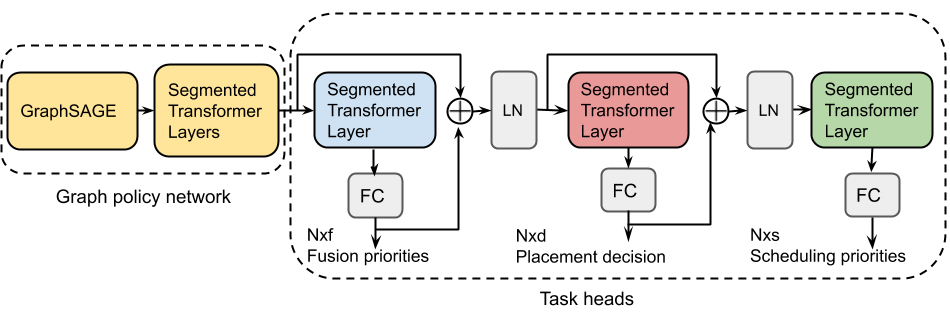
To jointly solve multiple dependent optimization tasks, GO has the ability to add additional recurrent attention layers for each task with parameters shared across different tasks. The recurrent attention layers with residual connections of actions enables tracking inter-task dependencies.
 |
| Multi-task policy network that extends GO’s policy network with additional recurrent attention layers for each task and residual connections. GE: Graph Embedding, FC: Fully-Connected Layer, Nxf: fusion action dimension, Fxd: placement action dimension, Nxs: scheduling action dimension. |
Results
Next, we present evaluation results on a single-task speedup on a device placement task based on real-hardware measurements, generalization to unseen graphs with different GO variants, and multi-task performance jointly optimizing operations fusion, device placement, and scheduling.
Speedup
To evaluate the performance of this architecture, we apply GO to a device placement problem based on real-hardware evaluation, where we first train the model separately on each of our workloads. This approach, called GO-one, consistently outperforms expert manual placement (HP), TensorFlow METIS placement, and Hierarchical Device Placement (HDP) — the current state-of-the-art reinforcement learning-based device placement. Importantly, with the efficient end-to-end single-shot placement, GO-one has a 15x speedup in convergence time of the placement network over HDP.
Our empirical results show that GO-one consistently outperforms expert placement, TensorFlow METIS placement, and hierarchical device placement (HDP). Because GO is designed in a way to scale up to extremely large graphs consisting of over 80,000 nodes like an 8-layer Google Neural Machine Translation (GNMT) model, it outperforms previous approaches, including HDP, REGAL, and Placeto. GO achieves optimized graph runtimes for large graphs like GNMT that are 21.7% and 36.5% faster than HP and HDP, respectively. Overall, GO-one achieves on average 20.5% and 18.2% run time reduction across a diverse set of 14 graphs, compared to HP and HDP respectively. Importantly, with the efficient end-to-end single-shot placement, GO-one has a 15x speedup in convergence time of the placement network over HDP.
Generalization
GO generalizes to unseen graphs using offline pre-training followed by fine-tuning on the unseen graphs. During pre-training, we train GO on heterogeneous subsets of graphs from the training set. We train GO for 1000 steps on each such batch of graphs before switching to the next. This pretrained model is then fine-tuned (GO-generalization+finetune) on hold-out graphs for fewer than 50 steps, which typically takes less than one minute. GO-generalization+finetune for hold-out graphs outperforms both expert placement and HDP consistently on all datasets, and on average matches GO-one.
We also run inference directly on just the pre-trained model without any fine-tuning for the target hold-out graphs, and name this GO-generalization-zeroshot. The performance of this untuned model is only marginally worse than GO-generalization+finetune, while being slightly better than expert placement and HDP. This indicates that both graph embedding and the learned policies transfer efficiently, allowing the model to generalize to the unseen data.
 |
| Generalization across heterogeneous workload graphs. The figure shows a comparison of two different generalization strategies for GO when trained with graphs from 5 (except the held-out one) of the 6 workloads (Inception-v3, AmoebaNet, recurrent neural network language model (RNNLM), Google Neural Machine Translation (GNMT), Transformer-XL (TRFXL), WaveNet), and evaluated on the held-out workload (x-axis). |
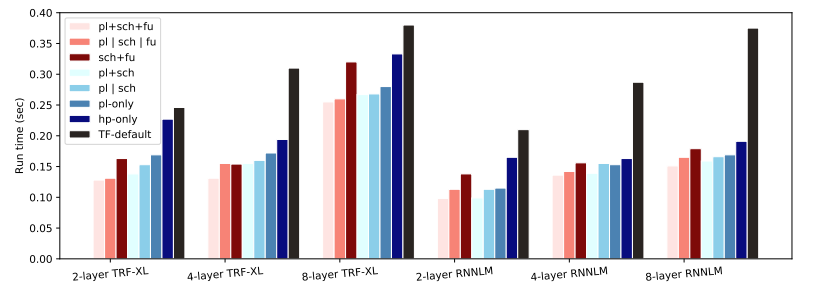
Co-optimizing placement, scheduling, and fusion (pl+sch+fu)
Optimizing simultaneously for placement, scheduling and fusion provides 30%-73% speedup compared to the single-gpu unoptimized case and 33%-60% speedup compared to TensorFlow default placement, scheduling, and fusion. Comparing to optimizing each tasks individually, multi-task GO (pl+sch+fu) outperforms single-task GO (p | sch | fu) — optimizing all tasks, one at a time — by an average of 7.8%. Furthermore, for all workloads, co-optimizing all three tasks offers faster run time than optimizing any two of them and using the default policy for the third.
 |
| Run time for various workloads on multi-task optimizations. TF-default: TF GPU default placement, fusion, and scheduling. hp-only: human placement only with default scheduling and fusion. pl-only: GO placement only with default scheduling and fusion. pl | sch: GO optimizes placement and scheduling individually with default fusion. pl+sch: multi-task GO co-optimizes placement and scheduling with default fusion. sch+fu: multi-task GO co-optimizes scheduling and fusion with human placement. pl | sch | fu: GO optimizes placement, scheduling, and fusion separately. pl+sch+fu: multi-task GO co-optimizes placement, scheduling, and fusion. |
Conclusion
The increasing complexity and diversity of hardware accelerators has made the development of robust and adaptable ML frameworks onerous and time-consuming, often requiring multiple years of effort from hundreds of engineers. In this article, we demonstrated that many of the optimization problems in such frameworks can be solved efficiently and optimally using a carefully designed learned approach.
Acknowledgements
This is joint work with Daniel Wong, Amirali Abdolrashidi, Peter Ma, Qiumin Xu, Hanxiao Liu, Mangpo Phitchaya Phothilimthana, Shen Wang, Anna Goldie, Azalia Mirhoseini, and James Laudon.
Quick links