End-to-end Generative Pre-training for Multimodal Video Captioning
June 7, 2022
Posted by Paul Hongsuck Seo and Arsha Nagrani, Research Scientists, Google Research, Perception Team
Quick links
Multimodal video captioning systems utilize both the video frames and speech to generate natural language descriptions (captions) of videos. Such systems are stepping stones towards the longstanding goal of building multimodal conversational systems that effortlessly communicate with users while perceiving environments through multimodal input streams.
Unlike video understanding tasks (e.g., video classification and retrieval) where the key challenge lies in processing and understanding multimodal input videos, the task of multimodal video captioning includes the additional challenge of generating grounded captions. The most widely adopted approach for this task is to train an encoder-decoder network jointly using manually annotated data. However, due to a lack of large-scale, manually annotated data, the task of annotating grounded captions for videos is labor intensive and, in many cases, impractical. Previous research such as VideoBERT and CoMVT pre-train their models on unlabelled videos by leveraging automatic speech recognition (ASR). However, such models often cannot generate natural language sentences because they lack a decoder, and thus only the video encoder is transferred to the downstream tasks.
In “End-to-End Generative Pre-training for Multimodal Video Captioning”, published at CVPR 2022, we introduce a novel pre-training framework for multimodal video captioning. This framework, which we call multimodal video generative pre-training or MV-GPT, jointly trains a multimodal video encoder and a sentence decoder from unlabelled videos by leveraging a future utterance as the target text and formulating a novel bi-directional generation task. We demonstrate that MV-GPT effectively transfers to multimodal video captioning, achieving state-of-the-art results on various benchmarks. Additionally, the multimodal video encoder is competitive for multiple video understanding tasks, such as VideoQA, text-video retrieval, and action recognition.
Future Utterance as an Additional Text Signal
Typically, each training video clip for multimodal video captioning is associated with two different texts: (1) a speech transcript that is aligned with the clip as a part of the multimodal input stream, and (2) a target caption, which is often manually annotated. The encoder learns to fuse information from the transcript with visual contents, and the target caption is used to train the decoder for generation. However, in the case of unlabelled videos, each video clip comes only with a transcript from ASR, without a manually annotated target caption. Moreover, we cannot use the same text (the ASR transcript) for the encoder input and decoder target, since the generation of the target would then be trivial.
MV-GPT circumvents this challenge by leveraging a future utterance as an additional text signal and enabling joint pre-training of the encoder and decoder. However, training a model to generate future utterances that are often not grounded in the input content is not ideal. So we apply a novel bi-directional generation loss to reinforce the connection to the input.
Bi-directional Generation Loss
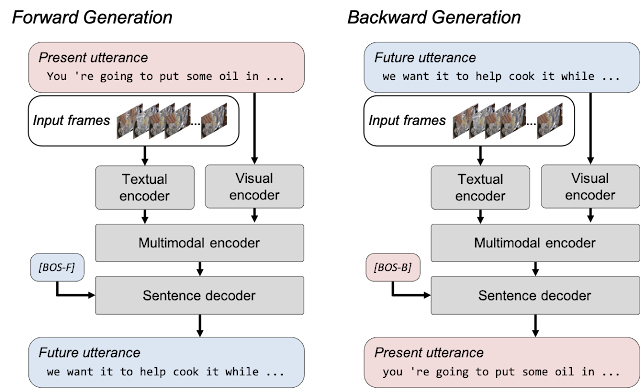
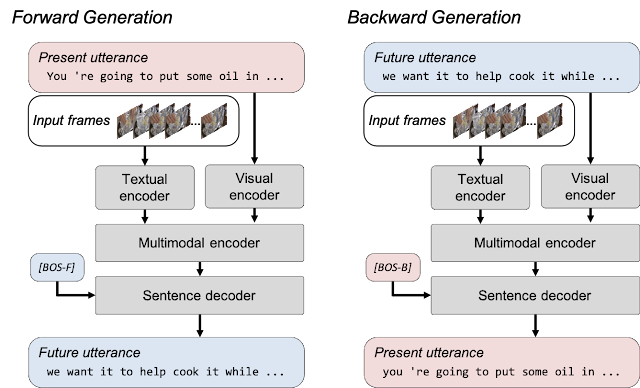
The issue of non-grounded text generation is mitigated by formulating a bi-directional generation loss that includes forward and backward generation. Forward generation produces future utterances given visual frames and their corresponding transcripts and allows the model to learn to fuse the visual content with its corresponding transcript. Backward generation takes the visual frames and future utterances to train the model to generate a transcript that contains more grounded text of the video clip. Bi-directional generation loss in MV-GPT allows the encoder and the decoder to be trained to handle visually grounded texts.
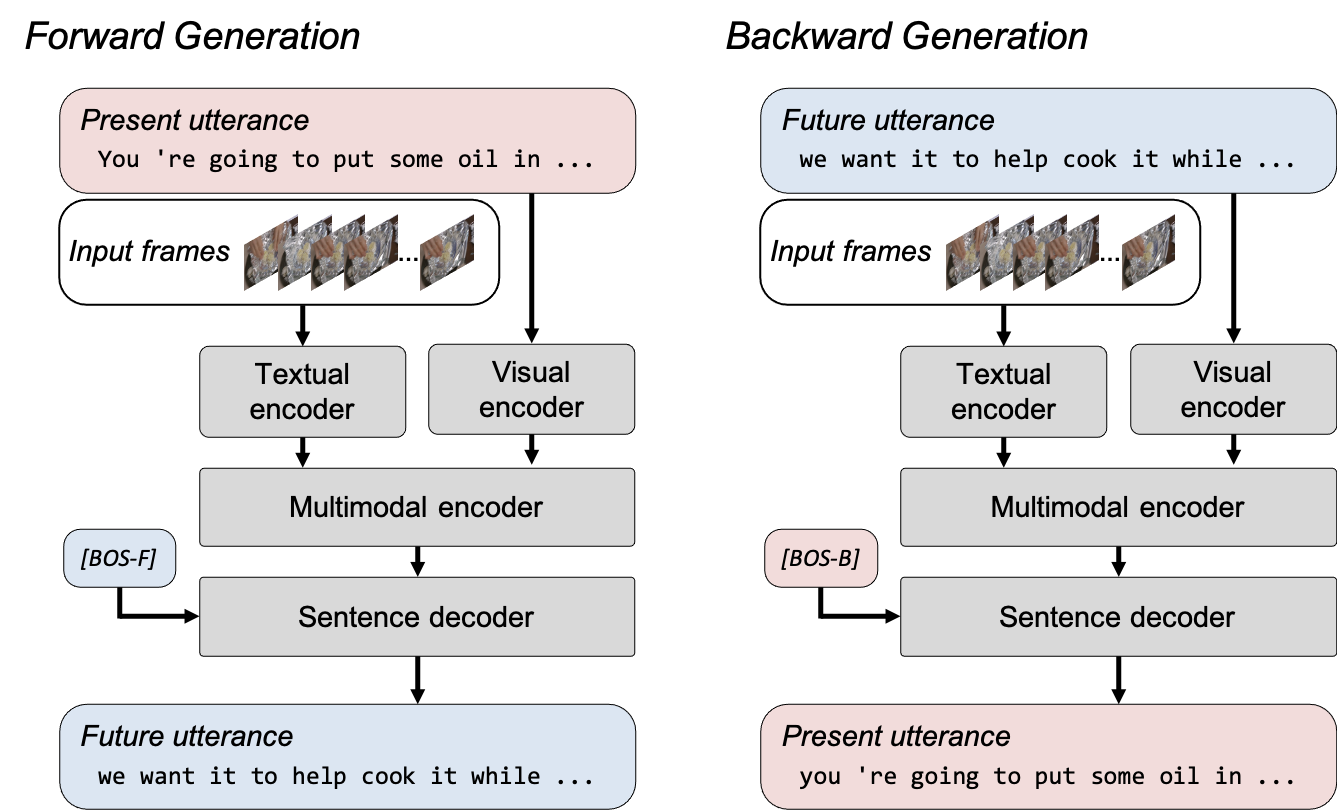 |
| Bi-directional generation in MV-GPT. A model is trained with two generation losses. In forward generation, the model generates a future utterance (blue boxes) given the frames and the present utterance (red boxes), whereas the present is generated from the future utterance in backward generation. Two special beginning-of-sentence tokens ([BOS-F] and [BOS-B]) initiate forward and backward generation for the decoder. |
Results on Multimodal Video Captioning
We compare MV-GPT to existing pre-training losses using the same model architecture, on YouCook2 with standard evaluation metrics (Bleu-4, Cider, Meteor and Rouge-L). While all pre-training techniques improve captioning performances, it is critical to pre-train the decoder jointly to improve model performance. We demonstrate that MV-GPT outperforms the previous state-of-the-art joint pre-training method by over 3.5% with relative gains across all four metrics.
| Pre-training Loss | Pre-trained Parts | Bleu-4 | Cider | Meteor | Rouge-L |
| No Pre-training | N/A | 13.25 | 1.03 | 17.56 | 35.48 |
| CoMVT | Encoder | 14.46 | 1.24 | 18.46 | 37.17 |
| UniVL | Encoder + Decoder | 19.95 | 1.98 | 25.27 | 46.81 |
| MV-GPT (ours) | Encoder + Decoder | 21.26 | 2.14 | 26.36 | 48.58 |
| MV-GPT performance across four metrics (Bleu-4, Cider, Meteor and Rouge-L) of different pre-training losses on YouCook2. “Pre-trained parts” indicates which parts of the model are pre-trained — only the encoder or both the encoder and decoder. We reimplement the loss functions of existing methods but use our model and training strategies for a fair comparison. | ||||
We transfer a model pre-trained by MV-GPT to four different captioning benchmarks: YouCook2, MSR-VTT, ViTT and ActivityNet-Captions. Our model achieves state-of-the-art performance on all four benchmarks by significant margins. For instance on the Meteor metric, MV-GPT shows over 12% relative improvements in all four benchmarks.
| YouCook2 | MSR-VTT | ViTT | ActivityNet-Captions | |
| Best Baseline | 22.35 | 29.90 | 11.00 | 10.90 |
| MV-GPT (ours) | 27.09 | 38.66 | 26.75 | 12.31 |
| Meteor metric scores of the best baseline methods and MV-GPT on four benchmarks. | ||||
Results on Non-generative Video Understanding Tasks
Although MV-GPT is designed to train a generative model for multimodal video captioning, we also find that our pre-training technique learns a powerful multimodal video encoder that can be applied to multiple video understanding tasks, including VideoQA, text-video retrieval and action classification. When compared to the best comparable baseline models, the model transferred from MV-GPT shows superior performance in five video understanding benchmarks on their primary metrics — i.e., top-1 accuracy for VideoQA and action classification benchmarks, and recall at 1 for the retrieval benchmark.
| Task | Benchmark | Best Comparable Baseline | MV-GPT |
| VideoQA | MSRVTT-QA | 41.5 | 41.7 |
| ActivityNet-QA | 38.9 | 39.1 | |
| Text-Video Retrieval | MSR-VTT | 33.7 | 37.3 |
| Action Recognition | Kinetics-400 | 78.9 | 80.4 |
| Kinetics-600 | 80.6 | 82.4 |
| Comparisons of MV-GPT to best comparable baseline models on five video understanding benchmarks. For each dataset we report the widely used primary metric, i.e., MSRVTT-QA and ActivityNet-QA: Top-1 answer accuracy; MSR-VTT: Recall at 1; and Kinetics: Top-1 classification accuracy. | ||||
Summary
We introduce MV-GPT, a new generative pre-training framework for multimodal video captioning. Our bi-directional generative objective jointly pre-trains a multimodal encoder and a caption decoder by using utterances sampled at different times in unlabelled videos. Our pre-trained model achieves state-of-the-art results on multiple video captioning benchmarks and other video understanding tasks, namely VideoQA, video retrieval and action classification.
Acknowledgements
This research was conducted by Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab and Cordelia Schmid.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence