Encode, Tag and Realize: A Controllable and Efficient Approach for Text Generation
January 31, 2020
Posted by Eric Malmi and Sebastian Krause, Software Engineers, Google Research
Quick links
Sequence-to-sequence (seq2seq) models have revolutionized the field of machine translation and have become the tool of choice for various text-generation tasks, such as summarization, sentence fusion and grammatical error correction. Improvements in model architecture (e.g., Transformer) and the ability to leverage large corpora of unannotated text via unsupervised pre-training have enabled the quality gains in neural network approaches we have seen in recent years.
Yet, the use of seq2seq models for text generation can come with a number of substantial drawbacks depending on the use case, such as producing outputs that are not supported by the input text (known as hallucination) and requiring large amounts of training data to reach good performance. Furthermore, seq2seq models are inherently slow at inference time, since they typically generate the output word-by-word.
In “Encode, Tag, Realize: High-Precision Text Editing,” we present a novel, open sourced method for text generation, which is designed to specifically address these three shortcomings. This method is called LaserTagger, owing to the speed and precision of the method. Instead of generating the output text from scratch, LaserTagger produces output by tagging words with predicted edit operations that are then applied to the input words in a separate realization step. This is a less error-prone way of tackling text generation, which can be handled by an easier to train and faster to execute model architecture.
Design and Functionality of LaserTagger
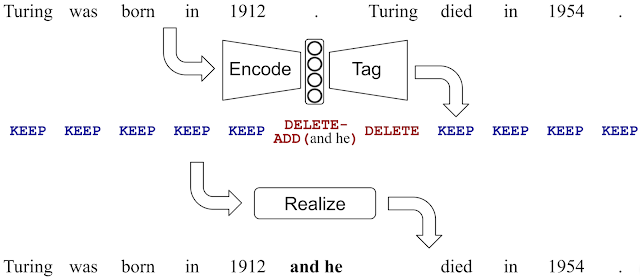
A distinct characteristic of many text-generation tasks is that there is often a high overlap between the input and the output. For instance, when detecting and fixing grammatical mistakes or when fusing sentences, most of the input text can remain unchanged, and only a small fraction of the words needs to be modified. For this reason, LaserTagger produces a sequence of edit operations instead of actual words. The four types of edit operations we use are: Keep (copies a word to the output), Delete (removes a word) and Keep-AddX / Delete-AddX (adds phrase X before the tagged word and optionally deletes the tagged word). This process is illustrated in the figure below, which shows an application of LaserTagger to sentence fusion.
 |
| LaserTagger applied to sentence fusion. The predicted edit operations correspond to deleting “. Turing" and adding "and he" before it. Notice the high overlap between the input and output text. |
Results
We evaluated LaserTagger on four tasks: sentence fusion, split and rephrase, abstractive summarization, and grammar correction. Across the tasks, LaserTagger performs comparably to a strong BERT-based seq2seq baseline that uses a large number of training examples, and clearly outperforms this baseline when the number of training examples is limited. Below we show the results on the WikiSplit dataset, where the task is to rephrase a long sentence into two coherent short sentences.
 |
| When training the models on the full dataset of 1 million examples, both LaserTagger and a BERT-based seq2seq baseline model perform comparably, but when training on a subsample of 10,000 examples or less, LaserTagger clearly outperforms the baseline model (the higher the SARI score the better). |
Compared to traditional seq2seq methods, LaserTagger has the following advantages:
- Control: By controlling the output phrase vocabulary, which we can also manually edit or curate, LaserTagger is less susceptible to hallucination than the seq2seq baseline.
- Inference speed: LaserTagger computes predictions up to 100 times faster than the seq2seq baseline, making it suitable for real-time applications.
- Data efficiency: LaserTagger produces reasonable outputs, even when trained using only a few hundred or a few thousand training examples. In our experiments, a competitive seq2seq baseline required tens of thousands of examples to obtain comparable performance.
The advantages of LaserTagger become even more pronounced when applied at large scale, such as improving the formulation of voice answers in some services by reducing the length of the responses and making them less repetitive. The high inference speed allows the model to be plugged into an existing technology stack, without adding any noticeable latency on the user side, while the improved data efficiency enables the collection of training data for many languages, thus benefiting users from different language backgrounds.
In our current work, we strive to bring similar improvements to other Google technologies that produce natural language. Furthermore, we are exploring how the editing of texts (instead of their generation from scratch) can help us to better understand user queries as they grow longer, become more complex, and come as part of a dialogue discourse. The code for LaserTagger is open-sourced to the community through our GitHub repo.
Acknowledgements
This research was conducted by Eric Malmi, Sebastian Krause, Sascha Rothe, Daniil Mirylenka, and Aliaksei Severyn. We are grateful for useful discussions with Enrique Alfonseca, Idan Szpektor, and Orgad Keller.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
×
❮
❯