Efficient data generation for source-grounded information-seeking dialogs: A use case for meeting transcripts
June 25, 2024
Lotem Golany and Filippo Galgani, Software Engineers, Google Research
Meeting recordings have helped people worldwide catch missed meetings, focus instead of taking notes during calls, and review information. But recordings can also take a lot of time to review. One solution to enable efficient navigation of recordings would be an agent that supports natural language conversations with meeting recordings, so that users can catch up on meetings they have missed. This could manifest as a source-grounded information-seeking dialog task where the agent would allow users to efficiently navigate the given knowledge source and extract information of interest. In this conversational setting, a user would interact with an agent over multiple rounds of queries and responses regarding a source text. The input to the agent model would include the source text, dialog history, and the current user query, and its output should be a response to the query and a set of attributions (text spans from the source document that support the response).
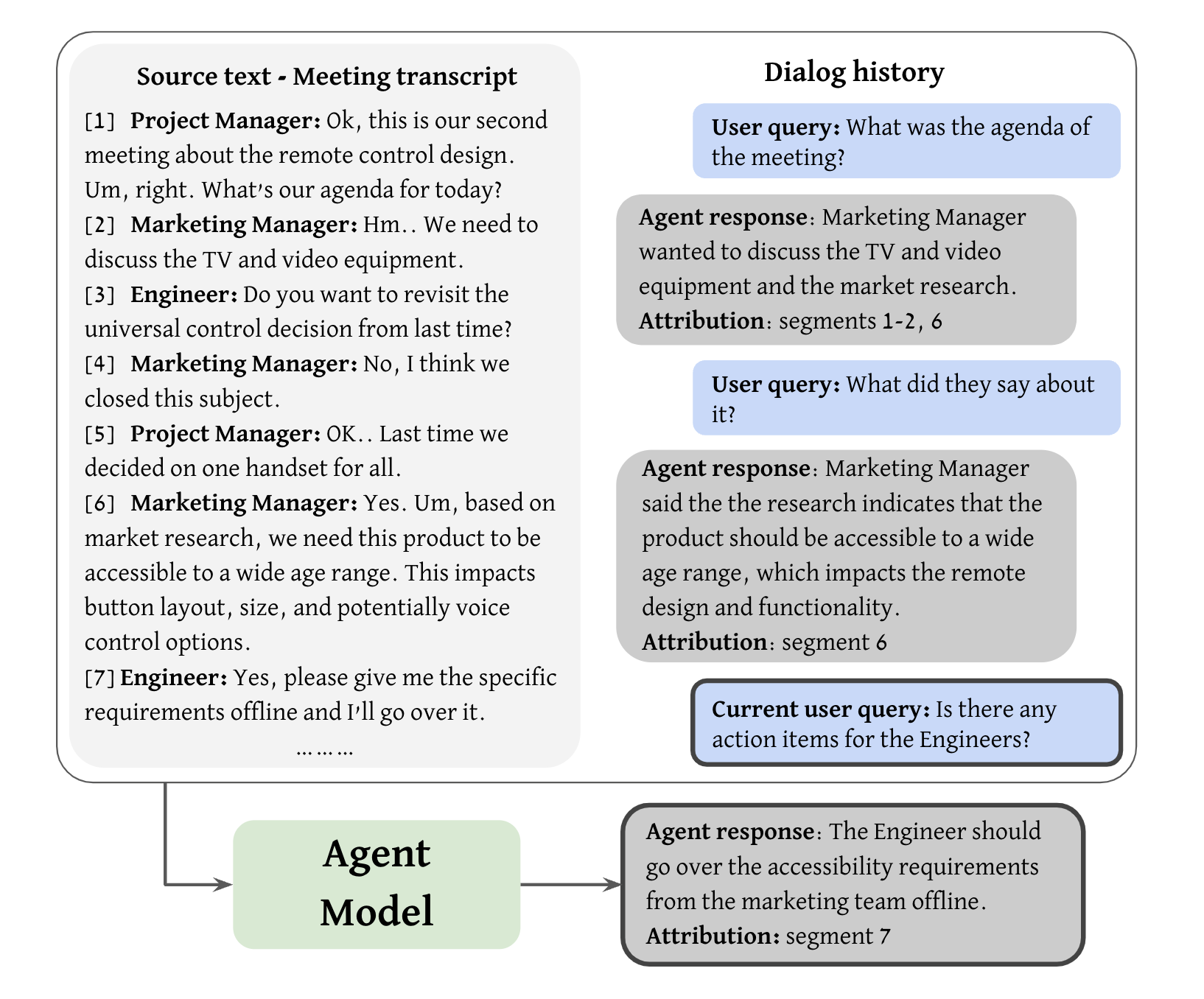
An illustration of the agent model task. The agent receives the source text (meeting transcript), dialog history, and the current user query. It then generates a corresponding response along with supporting attributions in the source text. Each attribution is a sequence of consecutive transcript segments.
However, to train effective agent models, quality dialog datasets are essential. Existing datasets in the meetings domain provide summarization and question-answering data, but none support multi-turn dialogs over meeting content. The dialog setup introduces additional complexity, as each query and response must consider the shared dialog state (e.g., previously shared information) in addition to the transcript, to maintain a coherent dialog flow. One prominent technique for creating dialog datasets is the Wizard-of-Oz (WOZ) method, in which two human annotators work together to produce a dialog, role-playing the user and agent. Yet the WOZ method is fully manual, time-consuming, and may lead to answers that vary in quality across annotators.
With this in mind, we present “Efficient Data Generation for Source-grounded Information-seeking Dialogs: A Use Case for Meeting Transcripts”, which describes our first of its kind, open-source Meeting Information Seeking Dialogs dataset (MISeD). Extending a recent trend of automating the generation of dialog datasets, we created MISeD by prompting pre-trained LLMs to partially automate the WOZ process. We utilize separate prompts to guide the LLM's generation of both the user queries and the agent responses. This is followed by annotator validation and manual generation of attributions. Models fine-tuned with MISeD demonstrate superior performance compared to off-the-shelf models, even those of larger size. Fine-tuning on MISeD gives comparable response generation quality to fine-tuning on fully manual data, while improving attribution quality and reducing time and effort.
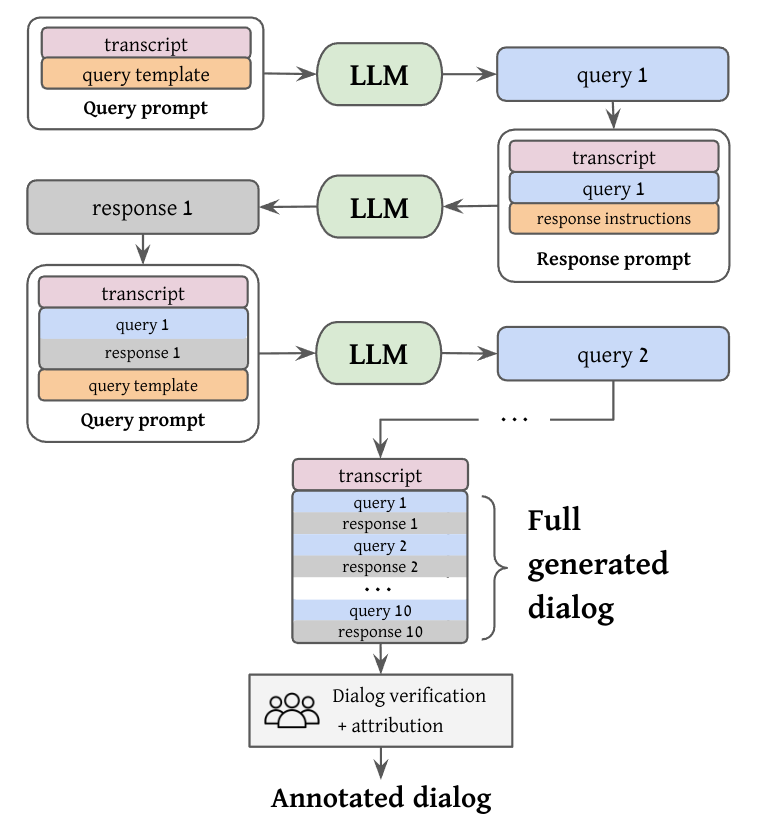
Iterative dialog generation flow. In each turn, a query prompt guides the LLM to generate a user query given the transcript, the accumulated dialog history, and a query template. Then, a response prompt, accompanied by the full context so far, generates the agent response. Iterating this automatic process yields a full dialog, which is then validated by annotators, who further augment it with response attributions.
Dataset creation methodology
We created the MISeD dataset using a semi-automated method applied over meeting transcripts. It includes the following stages:
- Automatic dialog generation
We generated dialog turns iteratively, with each turn consisting of a user query and an agent response. These were generated via targeted LLM prompts (detailed in our paper).
• User query prompts: These prompts incorporate the transcript, the dialog history, and templated instructions randomly selected from a pool of query instructions, designed to include various query types. These templates are adapted from the QMSum paper query schema (originally for human annotators) to guide LLM generation. We include both general queries for overall meeting themes and specific queries that focus on particular topics or individuals. We also expand the QMSum schema to include yes/no questions, an unanswerable variant to generate queries that cannot be answered from the transcript, and context-dependent queries that rely on the existing dialog for context.
• Agent response prompt: After generating the user query, we provide the LLM with a prompt that includes the meeting transcript, dialog history, the current query, and an instruction on how to generate the agent response. The instruction guides the LLM to generate an answer that aligns with certain length and format guidelines and that is grounded in the meeting content. - Dialog annotation and validation
We present the automatically generated dialog to annotators, who assess the generated query and the response, correct it if necessary, and identify corresponding attributions within the source text.
The MISeD dataset
We applied our automatic data creation methodology to transcripts from the QMSum meeting corpus across three meeting domains: product, using the AMI corpus; academic, using the ICSI corpus; and public Parliamentary Committee meetings. To generate dialogs based on the meeting transcripts — both queries and responses — we used the public Gemini Pro model. The resulting dataset includes 443 dialogs comprising 4430 query-response turns. During validation, annotators eliminated 6% of the queries, yielding 4161 turns. Of these remaining turns, annotators corrected 11% of the responses.
Each dataset entry includes a single dialog about a specific meeting transcript, containing up to ten query-response turns with associated metadata and attributing transcript spans. For model training and evaluation, dialogs are split into task instances. Each instance represents a single query with its history, target response, and attributions.
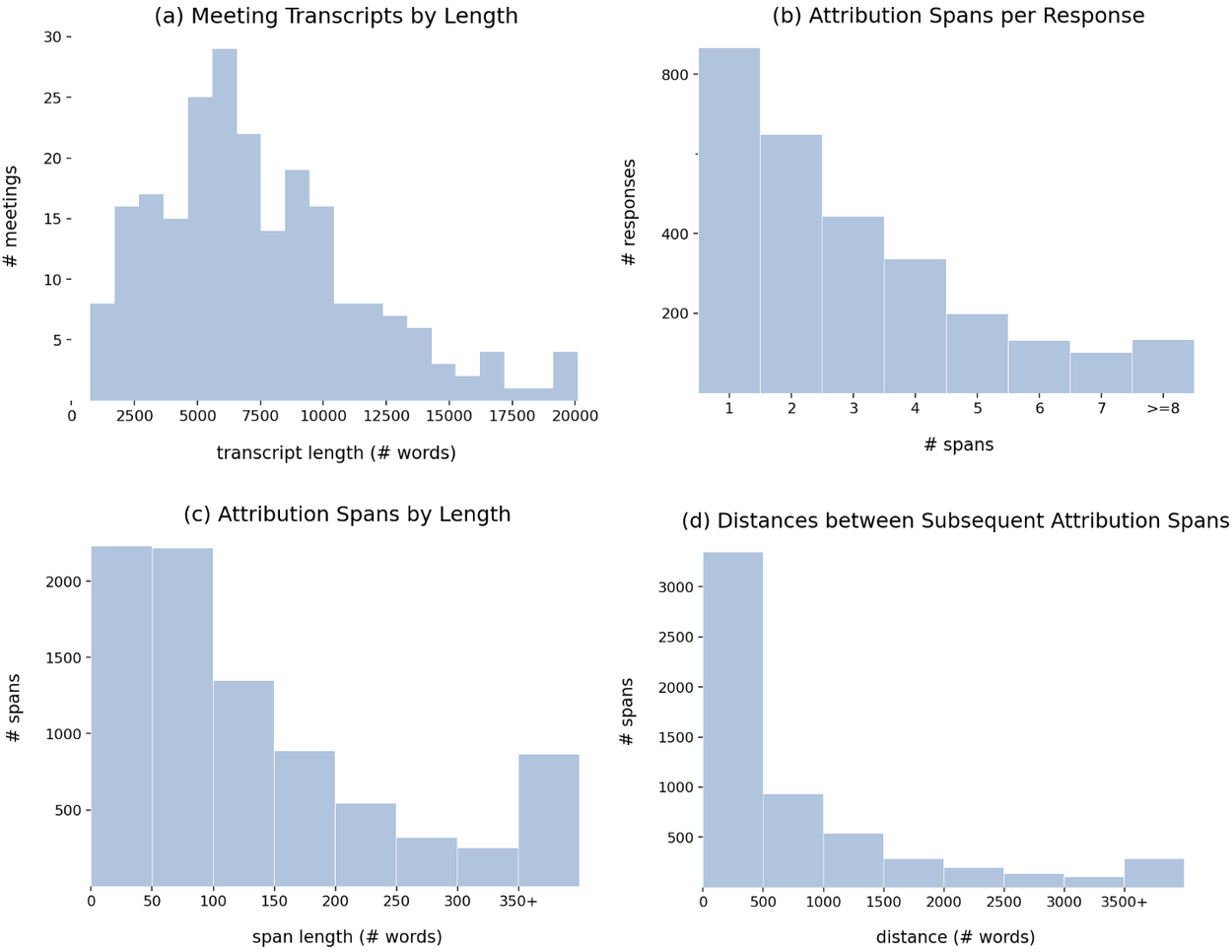
Statistics on the transcripts and attributions in MISeD.
We have open-sourced the MISeD dataset so it is publicly available for researchers.
Evaluation and performance
To evaluate the MISeD data, we compare with a dataset collected using the traditional WOZ approach. A “user” annotator was given the general context for a meeting and asked questions about it, while an ”agent” annotator used the full transcripts to provide answers and supporting attribution. This WOZ test set contains 70 dialogs (700 query-response pairs). It serves as an unbiased test set, revealing model performance on fully human-generated data. We found that the WOZ annotation time was 1.5 times slower than the MISeD annotation time.
We compared the performance for the following three model types: an encoder-decoder (LongT5 XL) fine-tuned on MISeD for long contexts (16k tokens); LLMs (Gemini Pro/Ultra) using prompts with transcripts and queries (28k tokens); and an LLM (Gemini Pro) fine-tuned on MISeD, using the same prompt and context length as above.
We trained the fine-tuned agent models using the MISeD training set (2922 training examples). Automatic evaluation was computed on the full test set (628 MISeD queries, 700 WOZ queries), while manual evaluation was run on a random subset of 100 queries of each test set.
We evaluate the agent models along two dimensions: the quality of the generated responses and the accuracy of the provided attributions, through both automatic and human evaluations. Our evaluation methodologies are described in our paper and results are presented below:
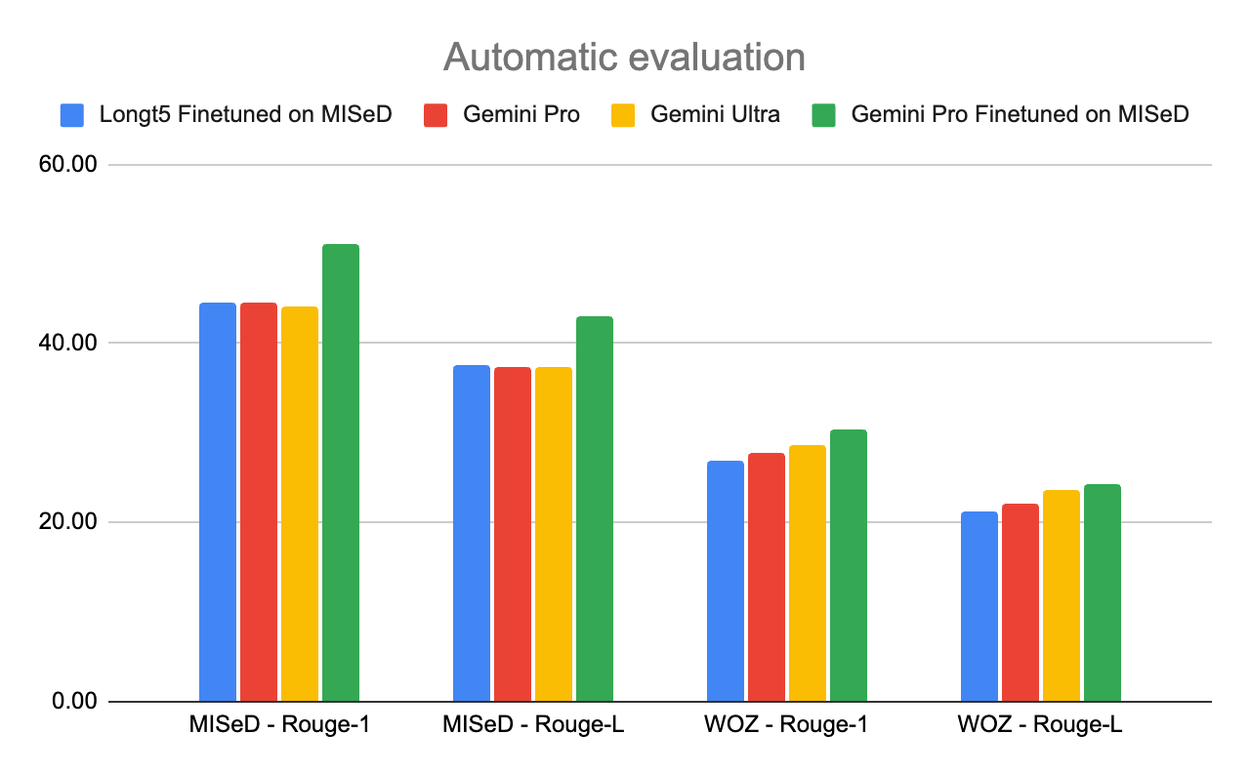
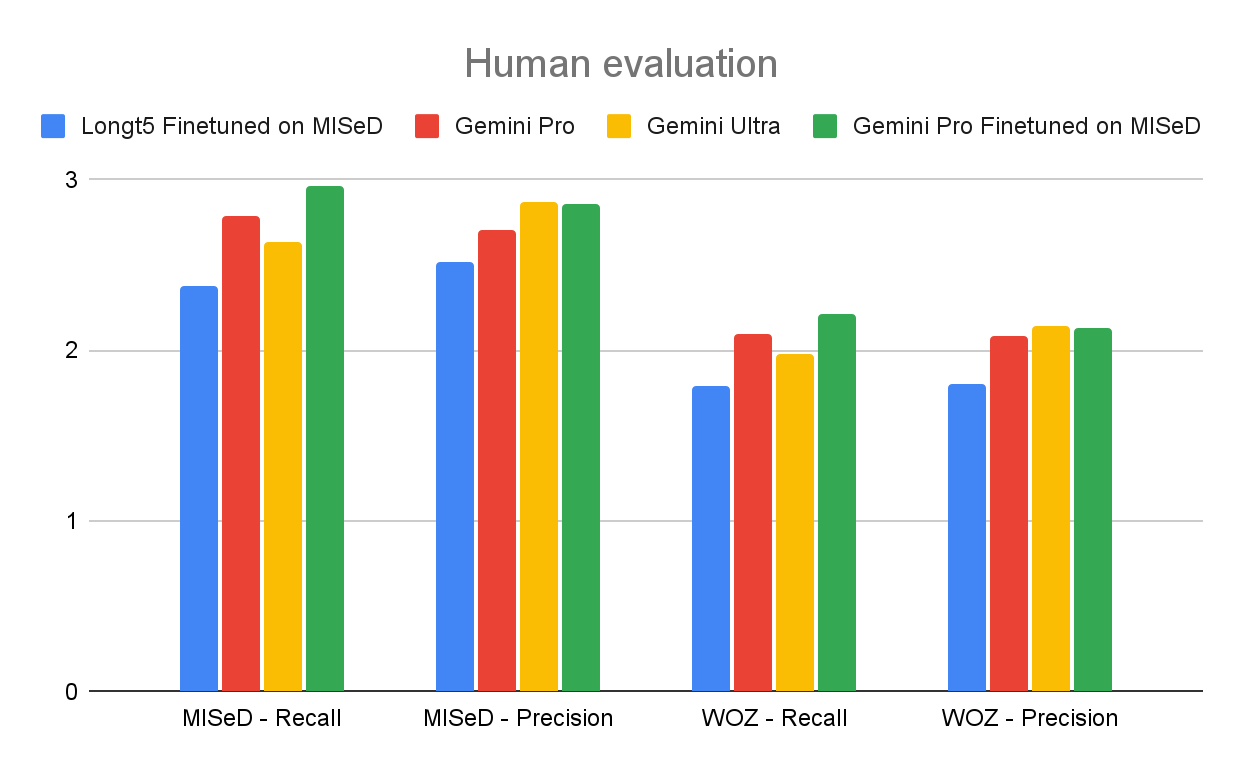
Response evaluation for the MISeD and WOZ test sets.
These baseline model evaluations on the MISeD and the fully manual WOZ test sets, as well as on an existing query-based summarization benchmark (QMSum), show the benefit of training with the MISeD dataset. It helps a smaller, fine-tuned LongT5 model nearly match the performance of much larger Gemini models. Fine-tuning Gemini Pro on MISeD significantly improves its results, even outperforming the larger Gemini Ultra.
Overall, scores on the WOZ test set are lower, indicating its greater challenge due to its fully-human creation. Fine-tuned models unsurprisingly perform better on the MISeD test set due to alignment with their training data. The attribution evaluation yields similar trends, showing that fine-tuning with MISeD improves performance. When we compared the performance of models trained on our semi-automatic MISeD data to those trained on the manual WOZ data, we found that both training sets (of the same size) yield comparable results. Full results can be found in the paper.
Conclusion & future work
We introduce a new method for creating source-grounded, information-seeking dialog datasets. Using targeted LLM prompts and human editing, we semi-automate the traditional WOZ process. We demonstrate this approach with MISeD, a meeting transcript dialog dataset, achieving improved quality, speed-up in data generation, and a reduction in dataset generation effort. We're sharing the MISeD dataset with the research community and are excited to see how it will enhance meeting-exploration research.
While query and response creation are successful, attribution remains challenging. Future research on improving attribution generation models could enable more complete automation of dialog generation, leading to an even more efficient process. Additionally, advancements in LLMs and prompting techniques will enable them to produce high-quality results that will possibly require little to no human validation.
Acknowledgements
The direct contributors to this work include Lotem Golany, Filippo Galgani, Maya Mamo, Nimrod Parasol, Omer Vandsburger, Nadav Bar, Ido Dagan.
We wish to thank David Karam, Michelle Tadmor Ramanovich, Eliya Nachmani, Benny Schlesinger, David Petrou and Blaise Aguera y Arcas for their support and feedback on the research. We also would like to express our gratitude to Victor Cărbune, Lucas Werner and Ondrej Skopek for their help with the annotation framework, and to Riteeka Kapila for leading the annotators team.



An illustration of the agent model task. The agent receives the source text (meeting transcript), dialog history, and the current user query. It then generates a corresponding response along with supporting attributions in the source text. Each attribution is a sequence of consecutive transcript segments.


