Directing ML toward natural hazard mitigation through collaboration
April 7, 2023
Posted by Oren Gilon, Software Engineer, and Grey Nearing, Research Scientist, Google Research
Quick links
Floods are the most common type of natural disaster, affecting more than 250 million people globally each year. As part of Google's Crisis Response and our efforts to address the climate crisis, we are using machine learning (ML) models for Flood Forecasting to alert people in areas that are impacted before disaster strikes.
Collaboration between researchers in the industry and academia is essential for accelerating progress towards mutual goals in ML-related research. Indeed, Google's current ML-based flood forecasting approach was developed in collaboration with researchers (1, 2) at the Johannes Kepler University in Vienna, Austria, the University of Alabama, and the Hebrew University of Jerusalem, among others.
Today we discuss our recent Machine Learning Meets Flood Forecasting Workshop, which highlights efforts to bring together researchers from Google and other universities and organizations to advance our understanding of flood behavior and prediction, and build more robust solutions for early detection and warning. We also discuss the Caravan project, which is helping to create an open-source repository for global streamflow data, and is itself an example of a collaboration that developed from the previous Flood Forecasting Meets Machine Learning Workshop.
2023 Machine Learning Meets Flood Forecasting Workshop
The fourth annual Google Machine Learning Meets Flood Forecasting Workshop was held in January. This 2-day virtual workshop hosted over 100 participants from 32 universities, 20 governmental and non-governmental agencies, and 11 private companies. This forum provided an opportunity for hydrologists, computer scientists, and aid workers to discuss challenges and efforts toward improving global flood forecasts, to keep up with state-of-the-art technology advances, and to integrate domain knowledge into ML-based forecasting approaches.
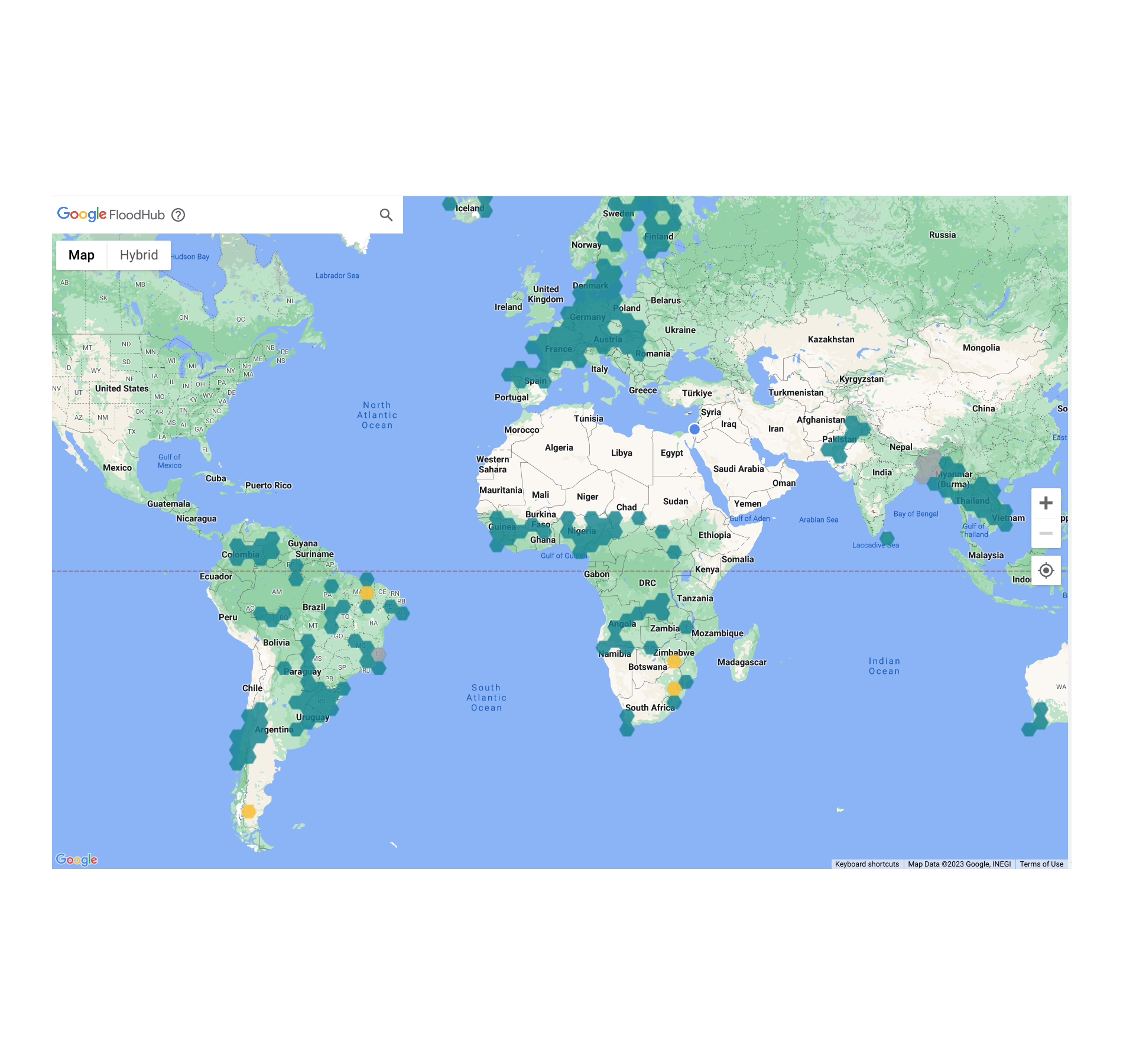
The event included talks from six invited speakers, a series of small-group discussion sessions focused on hydrological modeling, inundation mapping, and hazard alerting–related topics, as well as a presentation by Google on the FloodHub, which provides free, public access to Google’s flood forecasts, up to 7 days in advance.
 |
Invited speakers at the workshop included:
- Chaopeng Shen (Associate Professor at Pennsylvania State University) talked about recent research related to integrating physically-based hydrology models with ML.
- Beth Tellman (Assistant Professor at the University of Arizona & Chief Science Officer at Floodbase) gave an overview of recent efforts to map inundation in the United States using ML with input from NOAA’s US National Water Model.
- Frederik Kratzert (Research Scientist at Google) provided an overview of the Caravan project (below).
- Maulik Jagnani (Assistant Professor at the University of Colorado Denver) discussed a series of studies that measured how communities in India received and acted on perceived flood alerts from Google’s flood forecasting system.
- Shruti Verma (UX Researcher with the Flood Forecasting team at Google) discussed how UX research plays a role in understanding the people and populations who live in flood-prone regions around the world.
- Justin Sheffield (Professor and Head of the School of Geography and Environmental Science at the University of Southampton) talked about an operational forecasting system called the African Flood and Drought Monitor (AFDM).
The presentations can be viewed on YouTube:
2023 Flood Forecasting Meets Machine Learning Talks Day 1
2023 Flood Forecasting Meets Machine Learning Talks Day 2
Some of the top challenges highlighted during the workshop were related to the integration of physical and hydrological science with ML to help build trust and reliability; filling gaps in observations of inundated areas with models and satellite data; measuring the skill and reliability of flood warning systems; and improving the communication of flood warnings to diverse, global populations. In addition, participants stressed that addressing these and other challenges will require collaboration between a number of different organizations and scientific disciplines.
The Caravan project
One of the main challenges in conducting successful ML research and creating advanced tools for flood forecasting is the need for large amounts of data for computationally expensive training and evaluation. Today, many countries and organizations collect streamflow data (typically either water levels or flow rates), but it is not standardized or held in a central repository, which makes it difficult for researchers to access.
During the 2019 Machine Learning Meets Flood Forecasting Workshop, a group of researchers identified the need for an open source, global streamflow data repository, and developed ideas around leveraging free computational resources from Google Earth Engine to address the flood forecasting community’s challenge of data collection and accessibility. Following two years of collaborative work between researchers from Google, the school of Geography at the University of Exeter, the Institute for Machine Learning at Johannes Kepler University, and the Institute for Atmospheric and Climate Science at ETH Zurich, the Caravan project was created.
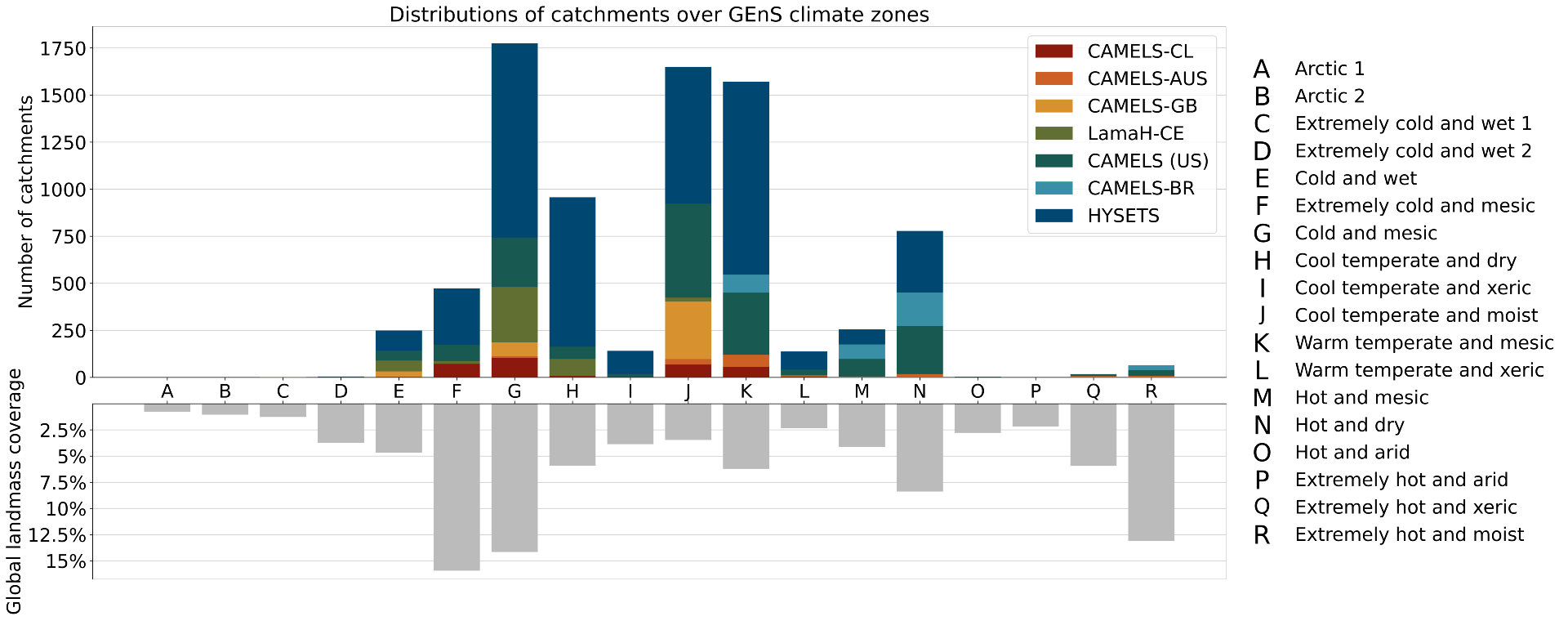
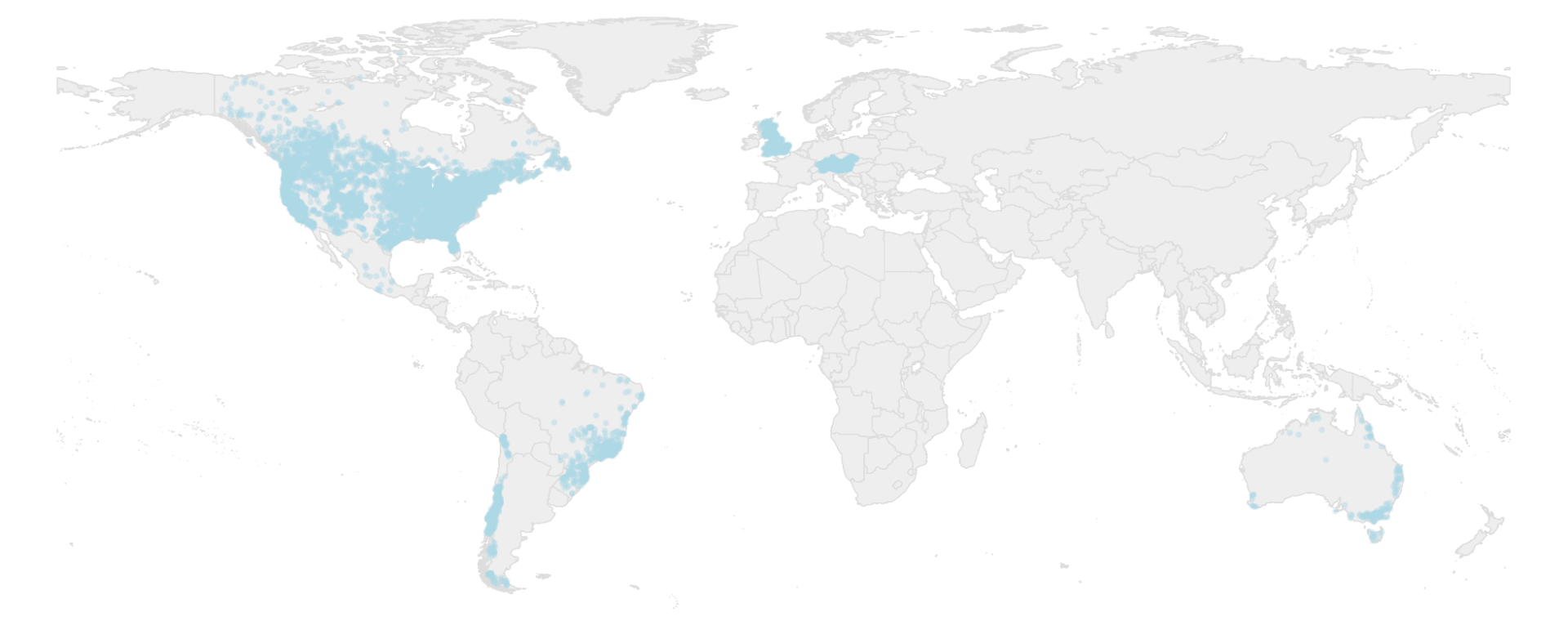
In “Caravan - A global community dataset for large-sample hydrology”, published in Nature Scientific Data, we describe the project in more detail. Based on a global dataset for the development and training of hydrological models (see figure below), Caravan provides open-source Python scripts that leverage essential weather and geographical data that was previously made public on Google Earth Engine to match streamflow data that users upload to the repository. This repository originally contained data from more than 13,000 watersheds in Central Europe, Brazil, Chile, Australia, the United States, Canada, and Mexico. It has further benefited from community contributions from the Geological Survey of Denmark and Greenland that includes streamflow data from most of the watersheds in Denmark. The goal is to continue to develop and grow this repository to enable researchers to access most of the world’s streamflow data. For more information regarding contributing to the Caravan dataset, reach out to caravan@google.com.
 |
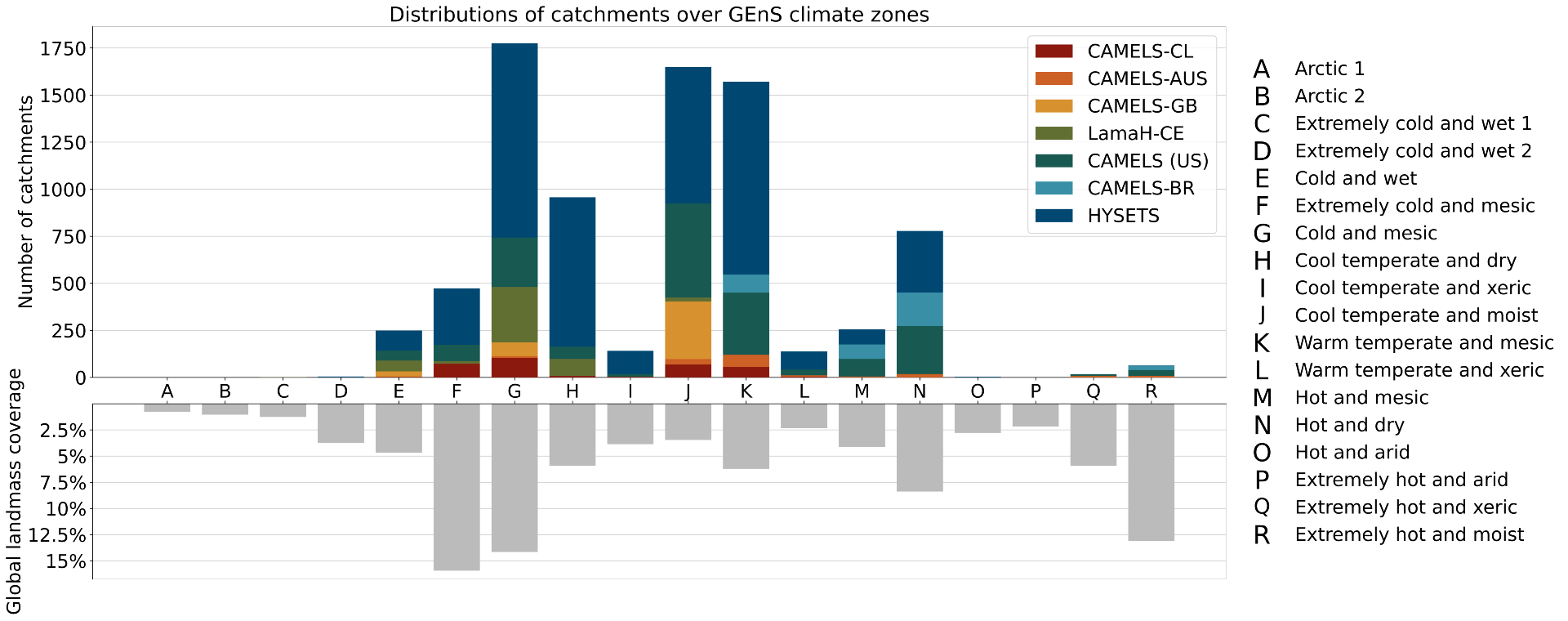 |
| Locations of the 13,000 streamflow gauges in the Caravan dataset and the distribution of those gauges in GEnS global climate zones. |
The path forward
Google plans to continue to host these workshops to help broaden and deepen collaboration between industry and academia in the development of environmental AI models. We are looking forward to seeing what advances might come out of the most recent workshop. Hydrologists and researchers interested in participating in future workshops are encouraged to contact flood-forecasting-meets-ml@google.com.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence