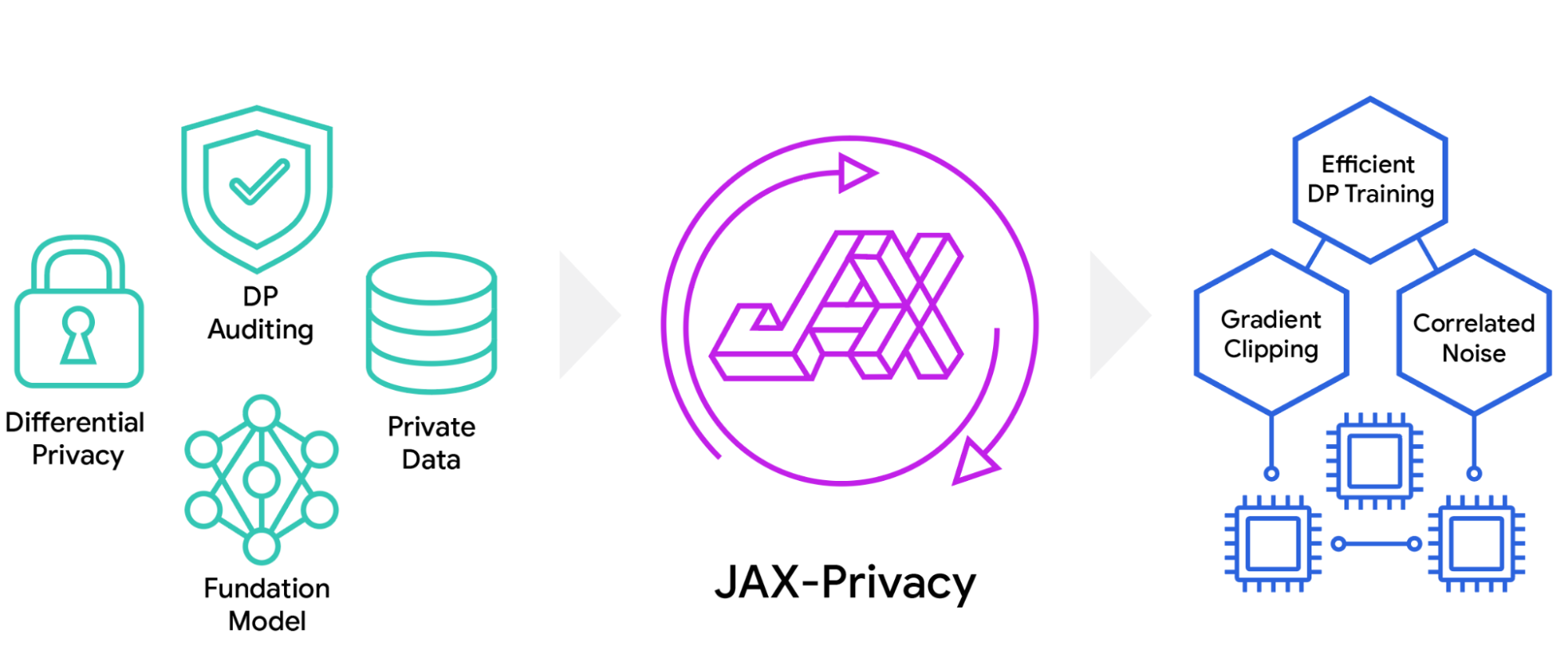
Differentially private machine learning at scale with JAX-Privacy
November 12, 2025
Borja Balle, Staff Research Scientist, Google DeepMind, and Ryan McKenna, Senior Research Scientist, Google Research
We announce the release of JAX-Privacy 1.0, a library for differentially private machine learning on the high-performance computing library, JAX.
Quick links
From personalized recommendations to scientific advances, AI models are helping to improve lives and transform industries. But the impact and accuracy of these AI models is often determined by the quality of data they use. Large, high-quality datasets are crucial for developing accurate and representative AI models, however, they must be used in ways that preserve individual privacy.
That’s where JAX and JAX-Privacy come in. Introduced in 2020, JAX is a high-performance numerical computing library designed for large-scale machine learning (ML). Its core features — including automatic differentiation, just-in-time compilation, and seamless scaling across multiple accelerators — make it an ideal platform for building and training complex models efficiently. JAX has become a cornerstone for researchers and engineers pushing the boundaries of AI. Its surrounding ecosystem includes a robust set of domain-specific libraries, including Flax, which simplifies the implementation of neural network architectures, and Optax, which implements state-of-the-art optimizers.
Built on JAX, JAX-Privacy is a robust toolkit for building and auditing differentially private models. It enables researchers and developers to quickly and efficiently implement differentially private (DP) algorithms for training deep learning models on large datasets, and provides the core tools needed to integrate private training into modern distributed training workflows. The original version of JAX-Privacy was introduced in 2022 to enable external researchers to reproduce and validate some of our advances on private training. It has since evolved into a hub where research teams across Google integrate their novel research insights into DP training and auditing algorithms.
Today, we are proud to announce the release of JAX-Privacy 1.0. Integrating our latest research advances and re-designed for modularity, this new version makes it easier than ever for researchers and developers to build DP training pipelines that combine state-of-the-art DP algorithms with the scalability provided by JAX.
How we got here: The need for JAX-Privacy
For years, researchers have turned to DP as the gold standard for quantifying and bounding privacy leakage. DP guarantees that the output of an algorithm is nearly the same whether or not a single individual (or example) is included in the dataset.
While the theory of DP is well-established, its practical implementation in large-scale ML can be a challenge. The most common approach, differentially private stochastic gradient descent (DP-SGD), requires customized batching procedures, per-example gradient clipping, and the addition of carefully calibrated noise. This process is computationally intensive and can be difficult to implement correctly and efficiently, especially at the scale of modern foundation models.
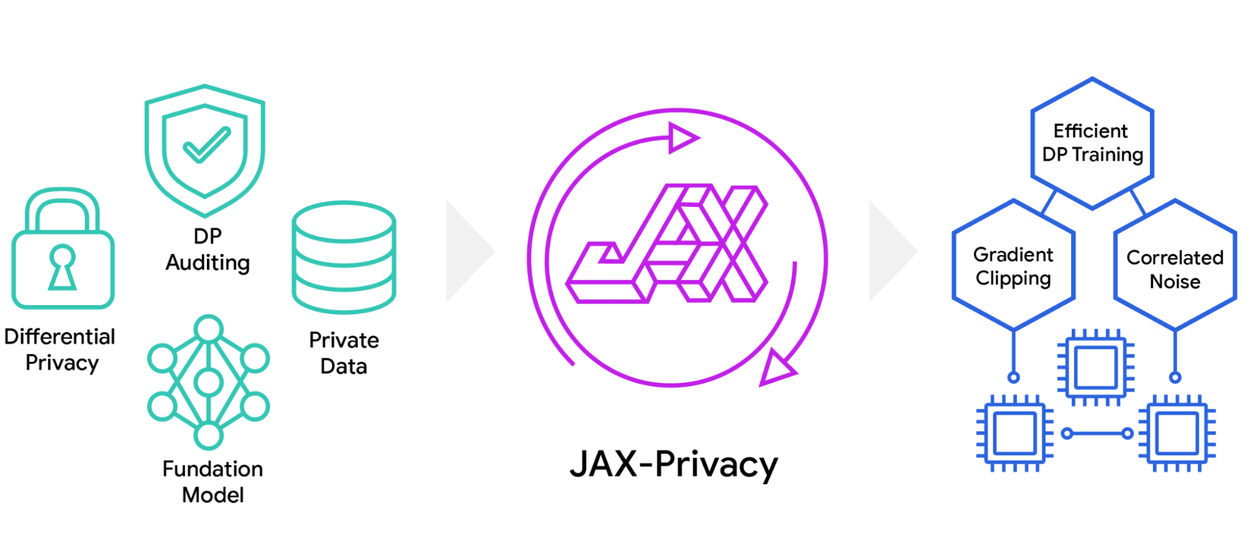
JAX-Privacy enables researchers and developers to train and fine-tune foundation models on private data using state-of-the-art differentially private algorithms in a scalable and efficient way thanks to its primitive building blocks for gradient clipping and correlated noise generation, both of which work effectively in distributed environments.
Existing frameworks have made strides, but they often fall short in scalability or flexibility. Our work has consistently pushed the boundaries of private ML, from pioneering new DP algorithms to developing sophisticated auditing techniques. We needed a tool that could keep pace with our research — a library that was not only correct and efficient but also designed from the ground up to handle the parallelism and complexity of state-of-the-art models.
JAX's functional paradigm and powerful transformations, like vmap (for automatic vectorization) and shard_map (for single-program multiple-data parallelization), provided a strong foundation. By building on JAX, we could create a library that was parallelism-ready out-of-the-box, supporting the training of large-scale models across multiple accelerators and supercomputers. JAX-Privacy is the culmination of this effort, a time-tested library that has powered internal production integrations and is now being shared with the broader community.
What JAX-Privacy delivers
JAX-Privacy simplifies the complexities of DP by providing a suite of carefully engineered components:
- Core building blocks: The library offers correct and efficient implementations of the fundamental DP primitives, including per-example gradient clipping, noise addition, and data batch construction. These components enable developers to build well-known algorithms like DP-SGD and DP-FTRL with confidence.
- State-of-the-art algorithms: JAX-Privacy goes beyond the basics, supporting advanced methods like DP matrix factorization that rely on injecting correlated noise across iterations, which have been shown to improve performance. This makes it easy for researchers to experiment with cutting-edge private training techniques.
- Scalability: All components are designed to work seamlessly with JAX's native parallelism features. This means you can train large-scale models that require data and model parallelism without complex, custom code, making private training on large models a reality. JAX-Privacy also provides tools like micro-batching and padding for seamlessly handling massive, variable-sized batches that are typically needed to obtain the best privacy/utility trade-offs.
- Correctness and auditing: The library is built on Google's state-of-the-art DP accounting library, ensuring the noise calibration is both mathematically correct and as tight as possible. These formal bounds on the privacy loss can be complemented with metrics that quantify the empirical privacy loss, providing a more complete view of the privacy properties of a training pipeline. Users can easily test and develop their own auditing techniques, like our award-winning work on "Tight Auditing of Differentially Private Machine Learning", which works by injecting "canaries" — known data points — and computing auditing metrics at each step.
JAX-Privacy implements a variety of foundational tools for clipping, noise addition, batch selection, accounting, and auditing that can be combined in various ways to construct end-to-end DP training plans.
From research to practice: Fine-tuning LLMs with confidence
One of the most exciting aspects of JAX-Privacy is its practical application. The library is designed to support modern ML frameworks used for pre-training and fine-tuning LLMs. A notable example is our recent use of JAX-Privacy building blocks in the training of VaultGemma, the world's most capable differentially private LLM.
With this open-source release, we want to enable developers to easily fine-tune large models with just a few lines of code via the popular Keras framework. In particular, we include fully-functional examples for fine-tuning models in the Gemma family, a collection of open models built by Google DeepMind based on Gemini. These examples demonstrate how to apply JAX-Privacy to tasks like dialogue summarization and synthetic data generation, showing that this library can deliver state-of-the-art results even when working with the most advanced models.
By simplifying the integration of DP, JAX-Privacy empowers developers to build privacy-preserving applications from the ground up, whether they are fine-tuning a chatbot for a healthcare application or a model for personalized financial advice. It lowers the barrier to entry for privacy-preserving ML and makes powerful, responsible AI more accessible.
Looking ahead
We are excited to share JAX-Privacy with the research community. This release is the result of years of dedicated effort and represents a significant contribution to the field of privacy-preserving ML. We hope that by providing these tools, we can enable a new wave of research and innovation that benefits everyone.
We will continue to support and develop the library, incorporating new research advances and responding to the needs of the community. We look forward to seeing what you build using JAX-Privacy. Check out the repository on GitHub or the PIP package to start training privacy-preserving ML models today.
Acknowledgements
JAX-Privacy includes contributions from: Leonard Berrada, Robert Stanforth, Brendan McMahan, Christopher A. Choquette-Choo, Galen Andrew, Mikhail Pravilov, Sahra Ghalebikesabi, Aneesh Pappu, Michael Reneer, Jamie Hayes, Vadym Doroshenko, Keith Rush, Dj Dvijotham, Zachary Charles, Peter Kairouz, Soham De, Samuel L. Smith, Judy Hanwen Shen.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence