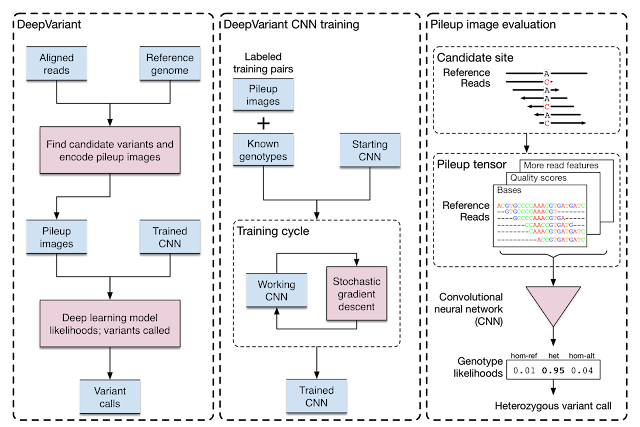
DeepVariant: Highly Accurate Genomes With Deep Neural Networks
December 4, 2017
Posted by Mark DePristo and Ryan Poplin, Google Brain Team
Quick links
(Crossposted on the Google Open Source Blog)
Across many scientific disciplines, but in particular in the field of genomics, major breakthroughs have often resulted from new technologies. From Sanger sequencing, which made it possible to sequence the human genome, to the microarray technologies that enabled the first large-scale genome-wide experiments, new instruments and tools have allowed us to look ever more deeply into the genome and apply the results broadly to health, agriculture and ecology.
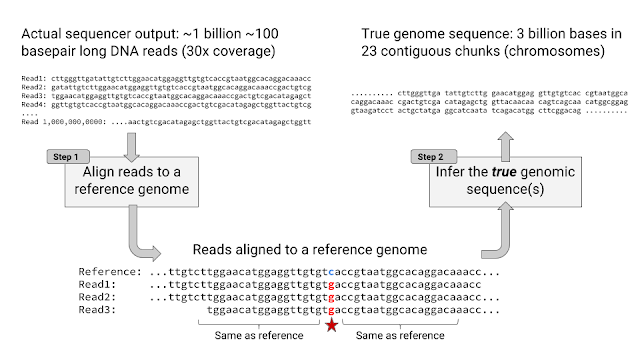
One of the most transformative new technologies in genomics was high-throughput sequencing (HTS), which first became commercially available in the early 2000s. HTS allowed scientists and clinicians to produce sequencing data quickly, cheaply, and at scale. However, the output of HTS instruments is not the genome sequence for the individual being analyzed — for humans this is 3 billion paired bases (guanine, cytosine, adenine and thymine) organized into 23 pairs of chromosomes. Instead, these instruments generate ~1 billion short sequences, known as reads. Each read represents just 100 of the 3 billion bases, and per-base error rates range from 0.1-10%. Processing the HTS output into a single, accurate and complete genome sequence is a major outstanding challenge. The importance of this problem, for biomedical applications in particular, has motivated efforts such as the Genome in a Bottle Consortium (GIAB), which produces high confidence human reference genomes that can be used for validation and benchmarking, as well as the precisionFDA community challenges, which are designed to foster innovation that will improve the quality and accuracy of HTS-based genomic tests.
 |
| For any given location in the genome, there are multiple reads among the ~1 billion that include a base at that position. Each read is aligned to a reference, and then each of the bases in the read is compared to the base of the reference at that location. When a read includes a base that differs from the reference, it may indicate a variant (a difference in the true sequence), or it may be an error. |
 |
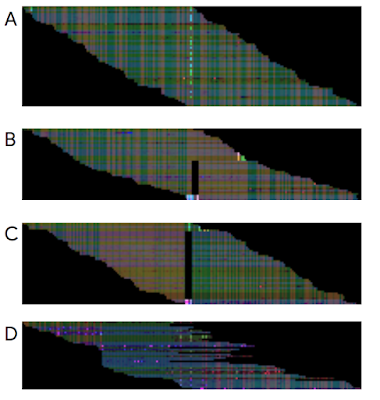
| Each of the four images above is a visualization of actual sequencer reads aligned to a reference genome. A key question is how to use the reads to determine whether there is a variant on both chromosomes, on just one chromosome, or on neither chromosome. There is more than one type of variant, with SNPs and insertions/deletions being the most common. A: a true SNP on one chromosome pair, B: a deletion on one chromosome, C: a deletion on both chromosomes, D: a false variant caused by errors. It's easy to see that these look quite distinct when visualized in this manner. |

DeepVariant is the first of what we hope will be many contributions that leverage Google's computing infrastructure and ML expertise to both better understand the genome and to provide deep learning-based genomics tools to the community. This is all part of a broader goal to apply Google technologies to healthcare and other scientific applications, and to make the results of these efforts broadly accessible.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯