
Deeper insights into retrieval augmented generation: The role of sufficient context
May 14, 2025
Cyrus Rashtchian, Research Lead, and Da-Cheng Juan, Software Engineering Manager, Google Research
We introduce a new notion of sufficient context to examine retrieval augmented generation (RAG) systems, developing a method to classify instances, analyzing failures of RAG systems, and proposing a way to reduce hallucinations.
Quick links
Retrieval augmented generation (RAG) enhances large language models (LLMs) by providing them with relevant external context. For example, when using a RAG system for a question-answer (QA) task, the LLM receives a context that may be a combination of information from multiple sources, such as public webpages, private document corpora, or knowledge graphs. Ideally, the LLM either produces the correct answer or responds with “I don’t know” if certain key information is lacking.
A main challenge with RAG systems is that they may mislead the user with hallucinated (and therefore incorrect) information. Another challenge is that most prior work only considers how relevant the context is to the user query. But we believe that the context’s relevance alone is the wrong thing to measure — we really want to know whether it provides enough information for the LLM to answer the question or not.
In “Sufficient Context: A New Lens on Retrieval Augmented Generation Systems”, which appeared at ICLR 2025, we study the idea of "sufficient context” in RAG systems. We show that it’s possible to know when an LLM has enough information to provide a correct answer to a question. We study the role that context (or lack thereof) plays in factual accuracy, and develop a way to quantify context sufficiency for LLMs. Our approach allows us to investigate the factors that influence the performance of RAG systems and to analyze when and why they succeed or fail.
Moreover, we have used these ideas to launch the LLM Re-Ranker in the Vertex AI RAG Engine. Our feature allows users to re-rank retrieved snippets based on their relevance to the query, leading to better retrieval metrics (e.g., nDCG) and better RAG system accuracy.
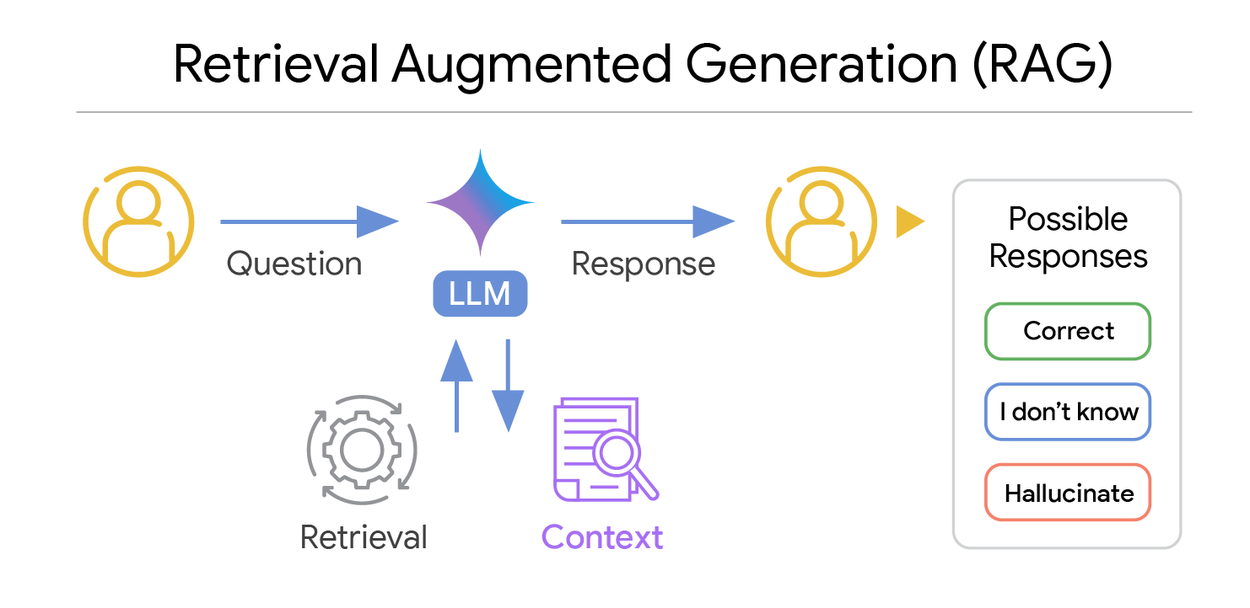
In a RAG system, an LLM uses retrieved context to provide a response to the input question.
Main conceptual contribution: Sufficient context
We define context as “sufficient” if it contains all the necessary information to provide a definitive answer to the query and “insufficient” if it lacks the necessary information, is incomplete, inconclusive, or contains contradictory information. For example:
Input query: The error code for “Page Not Found” is named after room 404, which had stored the central database of error messages in what famous laboratory?
- Sufficient context: The “Page Not Found” error, often displayed as a 404 code, is named after Room 404 at CERN, the European Organization for Nuclear Research. This was the room where the central database of error messages was stored, including the one for a page not being found.
- Insufficient context: A 404 error, or “Page Not Found” error, indicates that the web server cannot find the requested page. This can happen due to various reasons, including typos in the URL, a page being moved or deleted, or temporary issues with the website.
The second context is very relevant to the user’s query, but it does not answer the question, and hence it is insufficient.
Developing a sufficient context autorater
With this definition, we first develop an LLM-based automatic rater (“autorater”) that evaluates query-context pairs. To evaluate the autorater, we first had human experts analyze 115 question-and-context examples to determine if the context was sufficient to answer the question. This became the “gold standard” to which we compared the LLM’s judgements. Then, we had the LLM evaluate the same questions and contexts, where it outputs either “true” for sufficient context or “false” for insufficient context.
To optimize the model’s ability to solve this task, we also improved the prompt with various prompting strategies, such as chain-of-thought prompting and providing a 1-shot example. We then measured classification performance based on how often the LLM’s true/false labels matched the gold standard labels.
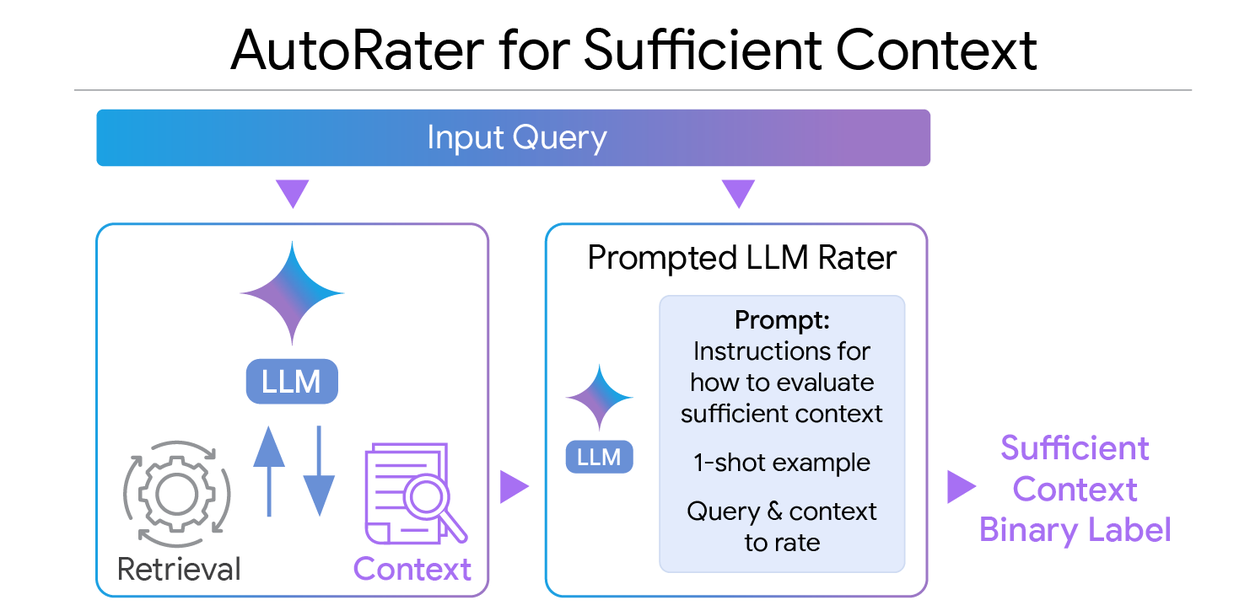
Our automatic rating method (autorater) for sufficient context. We use a prompted LLM to rate examples consisting of an input query and the retrieved context. The model outputs a binary true/false label that represents sufficient vs. insufficient context.
Using our optimized prompt, we show that we can classify sufficient context with very high accuracy (at least 93% of the time). It also turns out that the best performing method we tried is a prompted Gemini 1.5 Pro, without any fine-tuning. As baselines, we show that FLAMe (fine-tuned PaLM 24B) is slightly worse than Gemini but could be a more computationally efficient alternative. We also compare our approach to methods that rely on ground truth answers, such as TRUE-NLI (a fine-tuned entailment model), and a method that checks if the ground truth answer appears in the context ("Contains GT"). Gemini outperforms the alternatives, likely because it has better language understanding abilities.

Accuracy of classifying sufficient context, where we measure the agreement between various automatic methods to the human-annotated labels.
This autorater enables us to scalably label instances and analyze model responses based on sufficient vs. insufficient context.
Key insights into RAG systems
Using our sufficient context autorater, we analyzed the performance of various LLMs and datasets, leading to several key findings:
- State-of-the-art large models: Models like Gemini, GPT, and Claude generally excel at answering queries when provided with sufficient context but lack the ability to recognize and avoid generating incorrect answers when the provided context is insufficient.
- Smaller open-source models: Our analysis uncovers the specific issue that open-source models have a high rate of hallucination and abstention even when the context is sufficient to answer the question correctly.
- Insufficient context: Sometimes models generate correct answers when we rate the context as insufficient. This highlights the fact that insufficient context can still be useful. For example, it can bridge gaps in the model's knowledge or clarify ambiguities in the query.
Actionable insights: Based on our findings, we now have recommendations for how to improve RAG systems. For example, it could be beneficial to (i) add a sufficiency check before generation, (ii) retrieve more context or re-rank the retrieved contexts, or (iii) tune an abstention threshold with confidence and context signals.
Diving into the research behind sufficient context
Our analysis reveals that several standard benchmark datasets contain many instances with insufficient context. We consider three datasets: FreshQA, HotPotQA, and MuSiQue. Datasets with a higher percentage of sufficient context instances, such as FreshQA, tend to be those where the context is derived from human-curated supporting documents.
Example 182 from FreshQA is the question “How many food allergens with mandatory labeling are there in the United States?” This is a tricky question because the answer is nine, after sesame was added in 2023. The supporting document in the dataset is the Wikipedia article on Food Allergies, where the table under “Regulation of labeling” provides the list of the nine allergens with mandatory labeling.
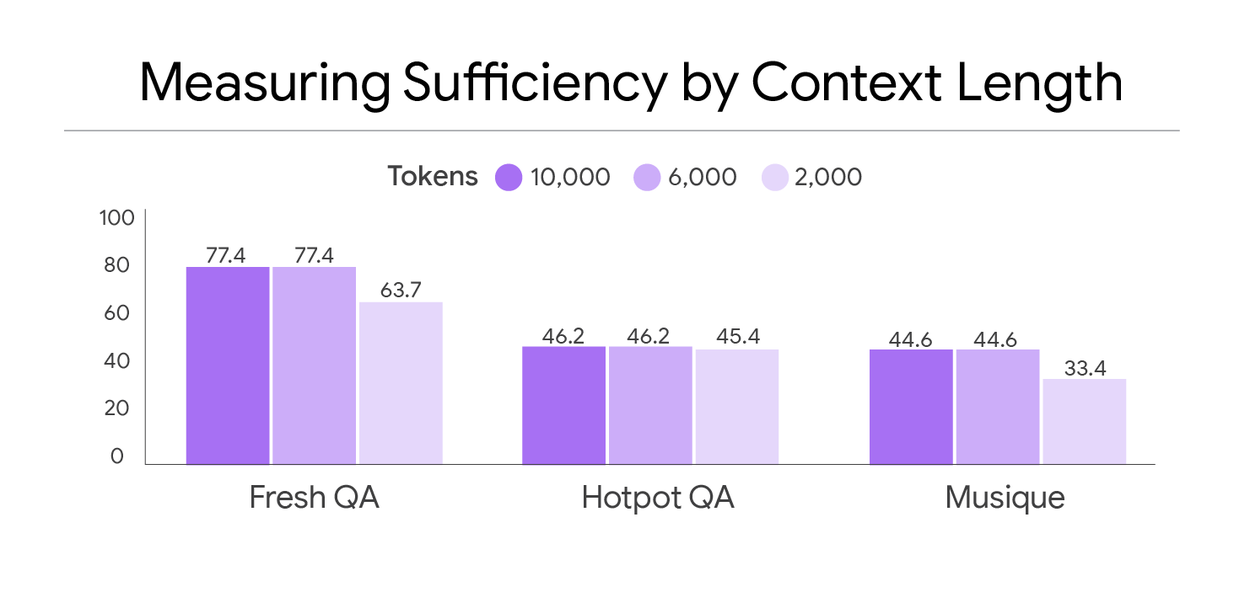
Comparing the percentage of examples with sufficient context (y-axis) across three datasets (x-axis).
Adding context leads to more hallucinations
A surprising observation is that while RAG generally improves overall performance, it paradoxically reduces the model's ability to abstain from answering when appropriate. The introduction of additional context seems to increase the model's confidence, leading to a higher propensity for hallucination rather than abstention.
To understand this, we use Gemini to rate each model response by comparing it to the set of possible ground truth answers. We classify each response as “Correct”, “Hallucinate” (i.e., incorrect answer), or ”Abstain” (e.g., saying “I don’t know”). With this approach we find, for example, that Gemma goes from providing incorrect answers on 10.2% of questions with no context up to 66.1% when using insufficient context.
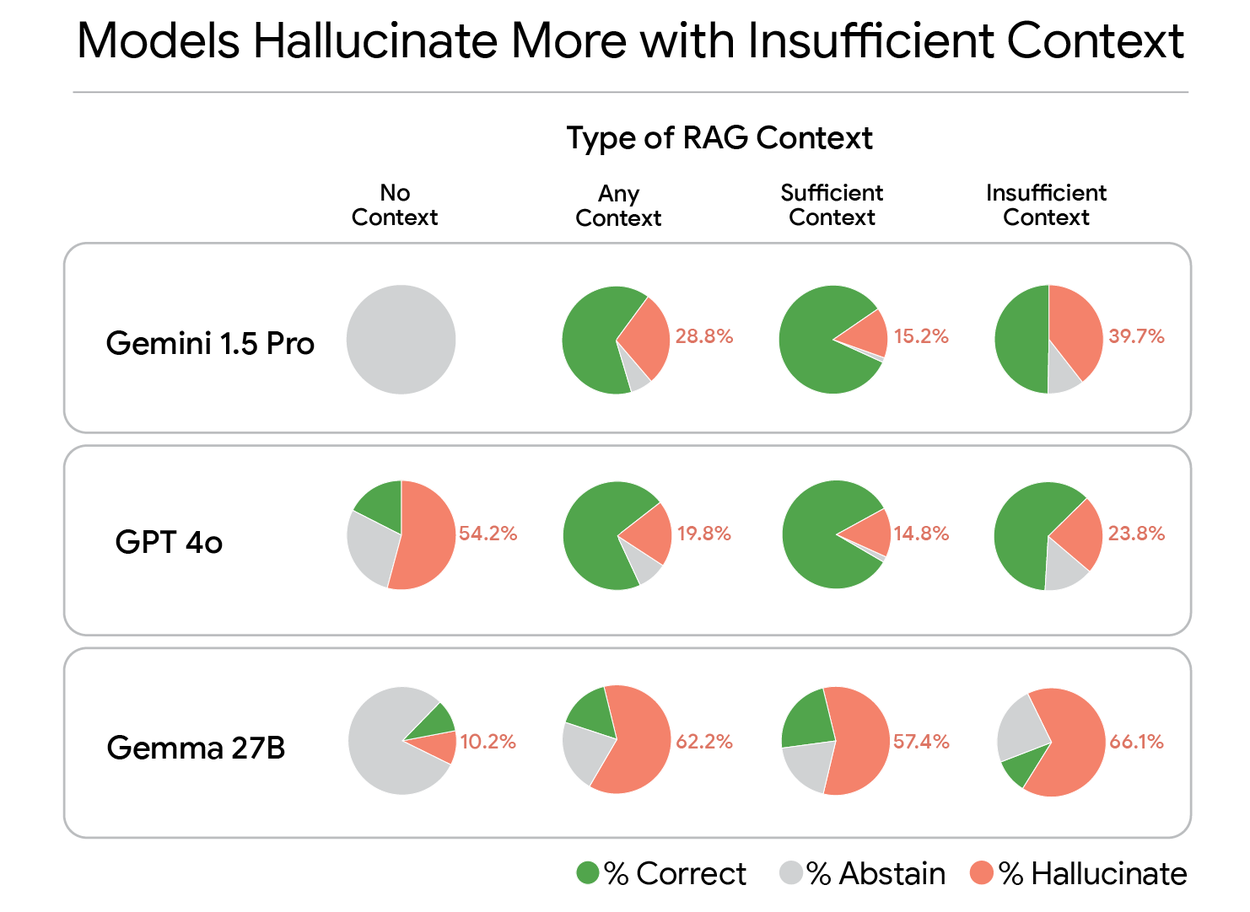
Detailed analysis of three LLMs in four different RAG settings.
Selective generation to reduce hallucinations
As another contribution, we develop a “selective generation” framework that leverages sufficient context information to guide abstention. We consider the following metrics: selective accuracy measures the model’s fraction of correct answers among the ones it answers, and coverage is the fraction of answered questions (non-abstentions).
Our selective generation approach combines the sufficient context signal with the model's self-rated confidence scores to make informed decisions about when to abstain. This is more nuanced than simply abstaining whenever the context is insufficient, as models can sometimes provide correct answers even with limited context. We use these signals to train a logistic regression model to predict hallucinations. We then set a coverage-accuracy trade-off threshold, determining when the model should abstain from answering.
The pipeline for our selective generation method to reduce hallucinations.
We use two main signals for abstention:
- Self-rated confidence: We use two strategies: P(True) and P(Correct). P(True) involves sampling answers multiple times and prompting the model to label each sample as correct or incorrect. P(Correct) is used for models where extensive querying is expensive; it involves obtaining the model's response and its estimated probability of correctness.
- Sufficient context signal: We use the binary label from an autorater model (FLAMe) to indicate whether the context is sufficient. Crucially, we do not need the ground truth answer to determine the sufficient context label, and so we can use this signal when answering the question.
Our results demonstrate that this approach leads to a better selective accuracy-coverage trade-off compared to using model confidence alone. By using the sufficient context label, we can increase the accuracy on the questions that the model answers, sometimes by up to 10% of the time.
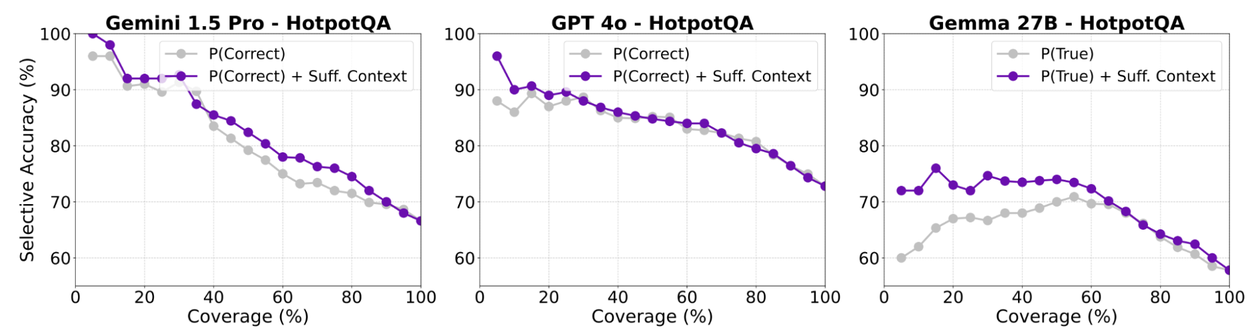
Selective accuracy (i.e., accuracy on the fraction of answered questions) vs. coverage (i.e., fraction of answered questions).
Conclusion
Our work provides new insights into the behavior of LLMs within RAG systems. By introducing and utilizing the concept of sufficient context, we have developed a valuable tool for analyzing and enhancing these systems. We showed that hallucinations in RAG systems may be due to insufficient context, and we demonstrated that selective generation can mitigate this issue. Future work will analyze how different retrieval methods influence context sufficiency and explore how signals about retrieval quality can be used to improve model post-training.
Acknowledgments
This work is in collaboration with Hailey Joren (lead student author), Jianyi Zhang, Chun-Sung Ferng, and Ankur Taly. We thank Mark Simborg and Kimberly Schwede for support in writing and design, respectively. We also thank Alyshia Olsen for help in designing the graphics.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence





