
Deep researcher with test-time diffusion
September 19, 2025
Rujun Han and Chen-Yu Lee, Research Scientists, Google Cloud
We introduce Test-Time Diffusion Deep Researcher (TTD-DR), a framework that uses a Deep Research agent to draft and revise its own drafts using high-quality retrieved information. This approach achieves new state-of-the-art results in writing long-form research reports and completing complex reasoning tasks.
Quick links
The recent advances in large language models (LLMs) have fueled the emergence of deep research (DR) agents. These agents demonstrate remarkable capabilities, including the generation of novel ideas, efficient information retrieval, experimental execution, and the subsequent drafting of comprehensive reports and academic papers.
Currently, most public DR agents use a variety of clever techniques to improve their results, like performing reasoning via chain-of-thought or generating multiple answers and selecting the best one. While they've made impressive progress, they often bolt different tools together without considering the iterative nature of human research. They're missing the key process (i.e., planning, drafting, researching, and iterating based on feedback) on which people rely when writing a paper about a complex topic. A key part of that revision process is to do more research to find missing information or strengthen your arguments. This human pattern is surprisingly similar to the mechanism of retrieval-augmented diffusion models that start with a “noisy” or messy output and gradually refine it into a high-quality result. What if an AI agent's rough draft is the noisy version, and a search tool acts as the denoising step that cleans it up with new facts?
Today we introduce Test-Time Diffusion Deep Researcher (TTD-DR), a DR agent that imitates the way humans do research. To our knowledge, TTD-DR is the first research agent that models research report writing as a diffusion process, where a messy first draft is gradually polished into a high-quality final version. We introduce two new algorithms that work together to enable TTD-DR. First, component-wise optimization via self-evolution enhances the quality of each step in the research workflow. Then, report-level refinement via denoising with retrieval applies newly retrieved information to revise and improve the report draft. We demonstrate that TTD-DR achieves state-of-the-art results on long-form report writing and multi-hop reasoning tasks.
Test-Time Diffusion Deep Researcher
TTD-DR is designed to take a user query as input and then create a preliminary draft that serves as an evolving foundation to guide the research plan. This evolving draft is iteratively refined using a denoising with retrieval process (report-level refinement) that takes the information it finds and uses it to improve the draft at each step. This happens in a continuous loop that improves the report with each cycle. To top it all off, a self-evolution algorithm constantly enhances the entire process, from the initial plan to the final report. This powerful combination of refinement and self-improvement leads to a more coherent report writing process.
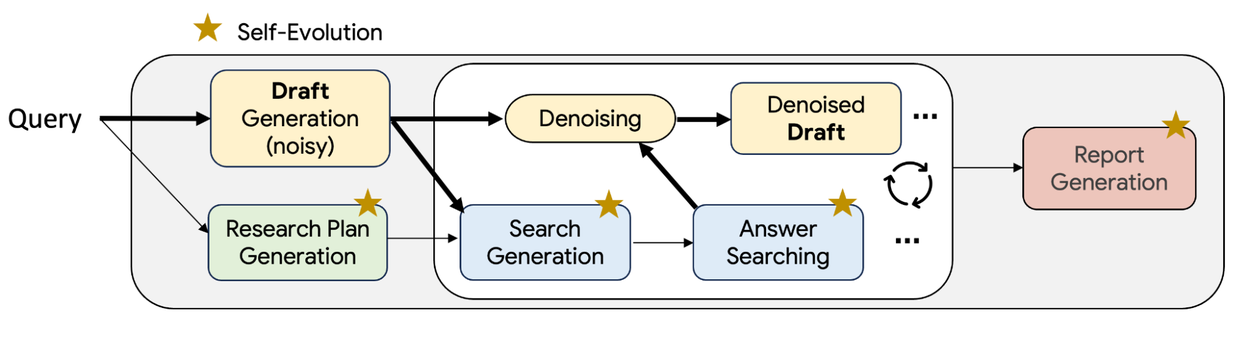
Illustration of TTD-DR. We designed it to imitate typical research practices by performing iterative cycles of drafting and revision.
Backbone DR design
The backbone DR design consists of three stages that we outline below.
- Research plan generation: Produces a structured research plan upon receiving a user query. This plan outlines a list of key areas needed for the final report, serving as an initial guideline for the subsequent information-gathering process.
- Iterative search: Contains two sub-agents: Search Question Generation (stage 2a in the figure below) formulates a search query based on the research plan, the user query, and the context from previous search iterations (i.e., past questions and answers). Answer Searching (stage 2b) searches the available sources to find relevant documents and returns a summarized answer, similar to retrieval-augmented generation (RAG) systems.
- Final report generation: Produces a comprehensive and coherent final report by combining all the structured information gathered, that is, the plan and the series of question-answer pairs.

Our backbone DR agent operates in three stages. Stage 1 generates a detailed research plan; Stage 2a iteratively generates search questions and then uses a RAG-like system to synthesize precise answers from retrieved documents (2b); Stage 3 synthesizes all gathered information to produce the final report.
Component-wise self-evolution
We leverage a self-evolutionary algorithm to enhance the performance of each stage's agents in order to find and preserve the high quality context.
- Initial states: The leftmost blocks in the diagram below represent multiple diverse answer variants based on the output of previous stages, which are used to explore a larger search space. This ideally leads to discovery of more valuable information.
- Environmental feedback: Each answer variant is assessed by an LLM-as-a-judge, utilizing auto-raters for metrics, such as helpfulness and comprehensiveness. These raters not only provide fitness scores but also generate textual feedback that help improve the answer.
- Revision: With the scores and feedback from the previous step, each variant undergoes a revision step to adapt toward better fitness scores. The environmental feedback and revision steps repeat until reaching some maximum number of iterations or until the agent determines no more revisions are needed.
- Cross-over: Finally, multiple revised variants are merged into a single, high-quality output. This merging process consolidates the best information from all evolutionary paths, producing superior context for the main report generation process.
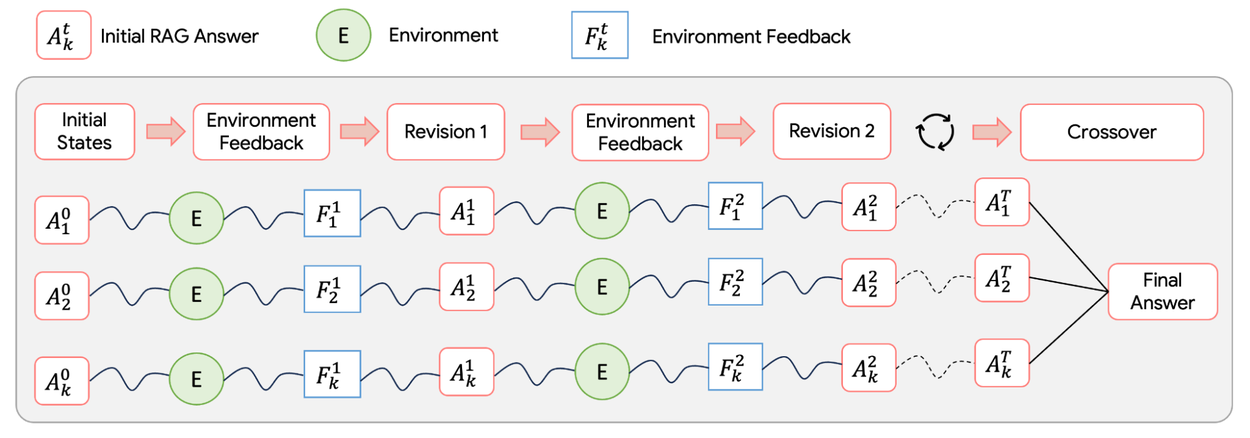
Illustration of the component-wise self-evolution algorithm applied to Search Answer (Stage 2b). The process starts with multiple variants of initial answers, each undergoing a self-evolving episode where it first interacts with the environment to obtain a fitness score and feedback. It is then revised based on the feedback. This process repeats until the maximum number of iterations is reached. Finally, multiple revised variants from all episodes are merged to produce the final answer.
Report-level denoising with retrieval
Since a preliminary noisy draft is useless for complex topics without real research, TTD-DR uses a search tool that denoises and evolves the draft.
Specifically, we feed the current draft report into the Search Generation stage (Stage 2a) of the backbone DR workflow to inform the generation of the next search query. After obtaining a synthesized answer in the Answer Searching stage (Stage 2b), the new information is used to revise the report draft, either by adding new details or by verifying existing information. This process of feeding the denoised report back to generate the next search query is repeated. The draft is progressively denoised until the search process concludes, at which point a final agent writes the final report based on all historical search answers and revisions (Stage 3).
Results
We evaluate TTD-DR's performance using benchmark datasets that focus on two broad tasks: 1) Complex queries that require research agents to produce a long-form comprehensive report (DeepConsult) and, 2) multi-hop queries that require extensive search and reasoning to answer (Humanity's Last Exam [HLE] and GAIA). We sub-sample 200 queries from HLE that need more search and reasoning (HLE-Search). Both categories fit into our objective of building a general-purpose, real-world research companion. We compare our DR systems with OpenAI Deep Research.
TTD-DR consistently achieves better results across all benchmarks. Notably, when compared to OpenAI DR, TTD-DR achieves 74.5% win rate for the long-form research report generation tasks. Additionally, it outperforms OpenAI DR by 7.7% and 1.7% on the two extensive research datasets with short-form ground-truth answers.
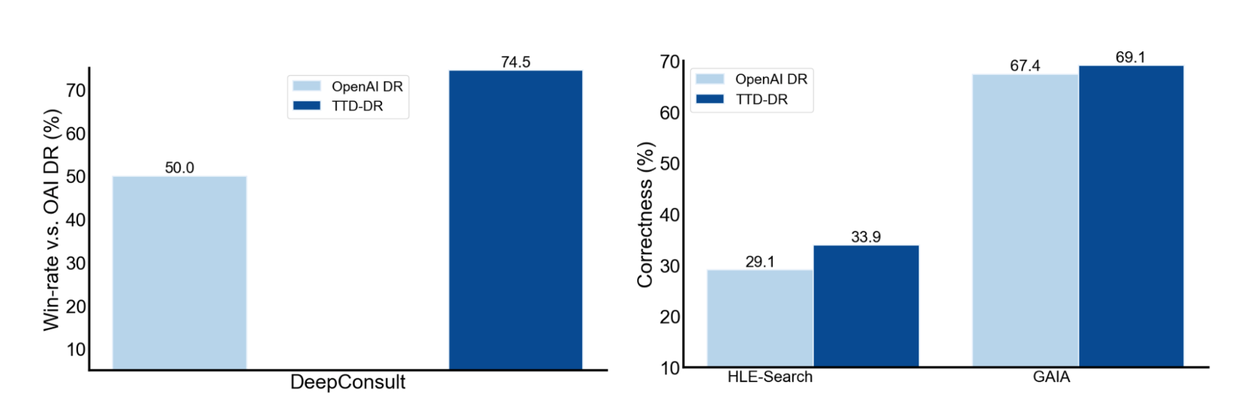
TTD-DR's performance against different baseline systems for benchmark datasets. Left: Win rates (%) are computed based on OpenAI DR. Right: Correctness is computed as matching between system predicted and reference answers. TTD-DR outperforms OpenAI DR with significant margins.
Ablation study
For the ablation study, we incrementally add the three methods in the section above. Our DR agents use Gemini-2.5-pro as the base model. All other baseline agents use their default LLMs. The charts below show the ablation study for our DR agents. The backbone DR agent underperforms OpenAI DR. With the addition of the proposed self-evolution algorithm, we observe that for DeepConsult, our system outperforms OpenAI Deep Research with 59.8% win rates. The Correctness scores on HLE-Search and GAIA datasets also show an improvement of 4.4% and 1.2%. Finally, incorporating diffusion with retrieval leads to substantial gains across all benchmarks.
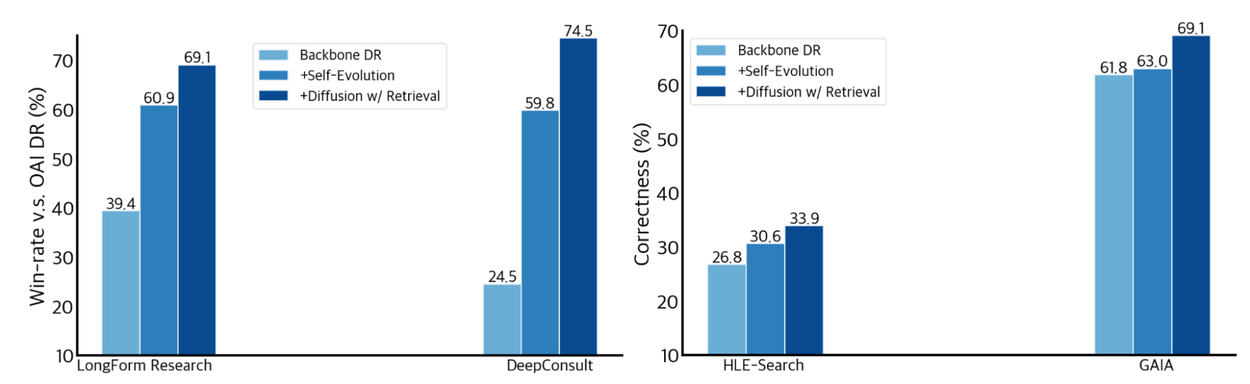
TTD-DR's performance by incrementally adding 1) backbone DR, 2) self-evolution, and 3) diffusion with retrieval. We observe step-by-step improvements across the board that help us achieve new state-of-the-art results.
The Pareto-frontier diagram below further shows the test-time scaling efficiency of TTD-DR compared with other DR agents. We found that TTD-DR is more efficient than OpenAI DR, as with the same latency, it achieves the better quality per win-rate. See the paper for more details.
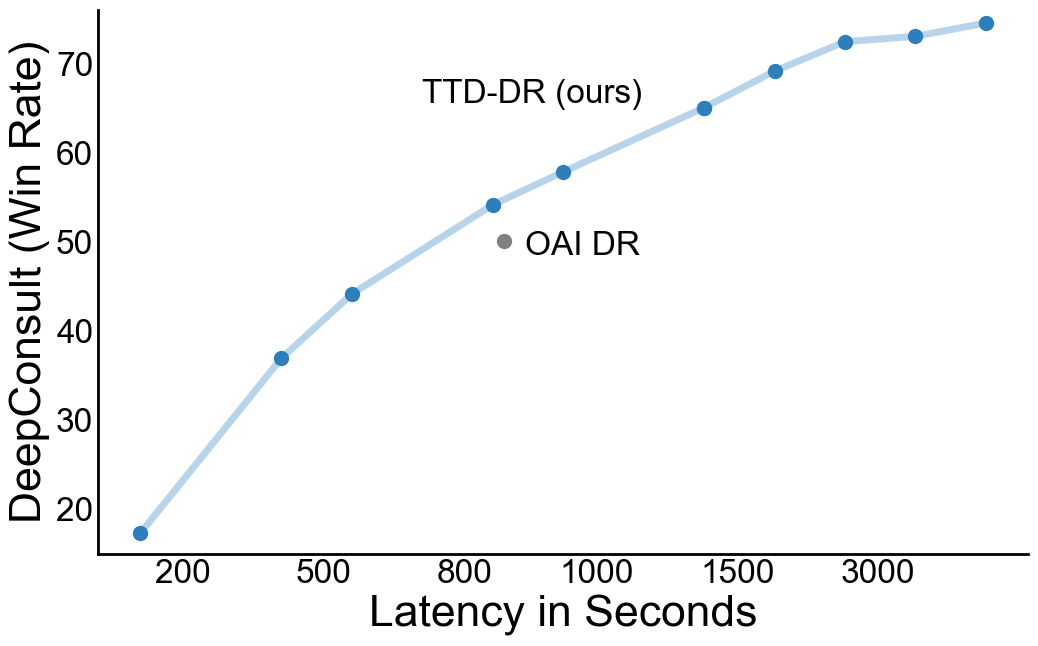
Pareto-frontier of research report quality vs. latency in seconds. The blue line indicates TTD-DR, whereas grey dots indicate compared DR agents.
Conclusion
The Deep Researcher with Test-Time Diffusion (TTD-DR) is a new framework inspired by the iterative way humans do research. This agent addresses the limitations of existing DR agents by conceptualizing report generation as a diffusion process. The TTD-DR framework significantly outperforms existing DR agents across various benchmarks requiring intensive search and multi-hop reasoning. It demonstrates state-of-the-art performance in generating comprehensive long-form research reports and identifying concise answers for multi-hop search and reasoning tasks. We believe the reason it works so well is its "draft-first" design, which keeps the whole research process focused and coherent, preventing important information from getting lost along the way.
Availability on Google Cloud Platform
A product version of this work is available on Google Agentspace, implemented with Google Cloud Agent Development Kit.
Acknowledgements
This research was conducted by Rujun Han, Yanfei Chen, Guan Sun, Lesly Miculicich, Zoey CuiZhu, Yuanjun (Sophia) Bi, Weiming Wen, Hui Wan, Chunfeng Wen, Solène Maître, George Lee, Vishy Tirumalashetty, Xiaowei Li, Emily Xue, Zizhao Zhang, Salem Haykal, Burak Gokturk, Tomas Pfister, and Chen-Yu Lee.
Quick links
Other posts of interest
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence




