Deciphering language processing in the human brain through LLM representations
March 21, 2025
Mariano Schain, Software Engineer, and Ariel Goldstein, Visiting Researcher, Google Research
Large Language Models (LLMs) optimized for predicting subsequent utterances and adapting to tasks using contextual embeddings can process natural language at a level close to human proficiency. This study shows that neural activity in the human brain aligns linearly with the internal contextual embeddings of speech and language within LLMs as they process everyday conversations.
Quick links
How does the human brain process natural language during everyday conversations? Theoretically, large language models (LLMs) and symbolic psycholinguistic models of human language provide a fundamentally different computational framework for coding natural language. Large language models do not depend on symbolic parts of speech or syntactic rules. Instead, they utilize simple self-supervised objectives, such as next-word prediction and generation enhanced by reinforcement learning. This allows them to produce context-specific linguistic outputs drawn from real-world text corpora, effectively encoding the statistical structure of natural speech (sounds) and language (words) into a multidimensional embedding space.
Inspired by the success of LLMs, our team at Google Research, in collaboration with Princeton University, NYU, and HUJI, sought to explore the similarities and differences in how the human brain and deep language models process natural language to achieve their remarkable capabilities. Through a series of studies over the past five years, we explored the similarity between the internal representations (embeddings) of specific deep learning models and human brain neural activity during natural free-flowing conversations, demonstrating the power of deep language model’s embeddings to act as a framework for understanding how the human brain processes language. We demonstrate that the word-level internal embeddings generated by deep language models align with the neural activity patterns in established brain regions associated with speech comprehension and production in the human brain.
Similar embedding-based representations of language.
Our most recent study, published in Nature Human Behaviour, investigated the alignment between the internal representations in a Transformer-based speech-to-text model and the neural processing sequence in the human brain during real-life conversations. In the study, we analyzed neural activity recorded using intracranial electrodes during spontaneous conversations. We compared patterns of neural activity with the internal representations — embeddings — generated by the Whisper speech-to-text model, focusing on how the model's linguistic features aligned with the brain's natural speech processing.
For every word heard (during speech comprehension) or spoken (during speech production), two types of embeddings were extracted from the speech-to-text model — speech embeddings from the model’s speech encoder and word-based language embeddings from the model's decoder. A linear transformation was estimated to predict the brain’s neural signals from the speech-to-text embeddings for each word in each conversation. The study revealed a remarkable alignment between the neural activity in the human brain's speech areas and the model's speech embeddings and between the neural activity in the brain’s language area and the model's language embeddings. The alignment is illustrated in the following animation, modeling the sequence of the brain’s neural responses to subjects’ language comprehension:
Sequence of the brain’s neural responses to subjects' language comprehension as they listen to the sentence “How are you doing?”.
As the listener processes the incoming spoken words, we observe a sequence of neural responses: Initially, as each word is articulated, speech embeddings enable us to predict cortical activity in speech areas along the superior temporal gyrus (STG). A few hundred milliseconds later, when the listener starts to decode the meaning of the words, language embeddings predict cortical activity in Broca’s area (located in the inferior frontal gyrus; IFG).
Turning to participants' production, we observe a different (reversed!) sequence of neural responses:
Sequence of neural responses to subjects’ language production as they answer “feeling fantastic".
Looking at this alignment more closely, about 500 milliseconds before articulating the word (as the subject prepares to articulate the next word), language embeddings (depicted in blue) predict cortical activity in Broca’s area. A few hundred milliseconds later (still before word onset), speech embeddings (depicted in red) predict neural activity in the motor cortex (MC) as the speaker plans the articulatory speech sequence. Finally, after the speaker articulates the word, speech embeddings predict the neural activity in the STG auditory areas as the listener listens to their own voice. This dynamic reflects the sequence of neural processing, starting with planning what to say in language areas, then how to articulate it in motor areas, and finally monitoring what was spoken in perceptual speech areas.
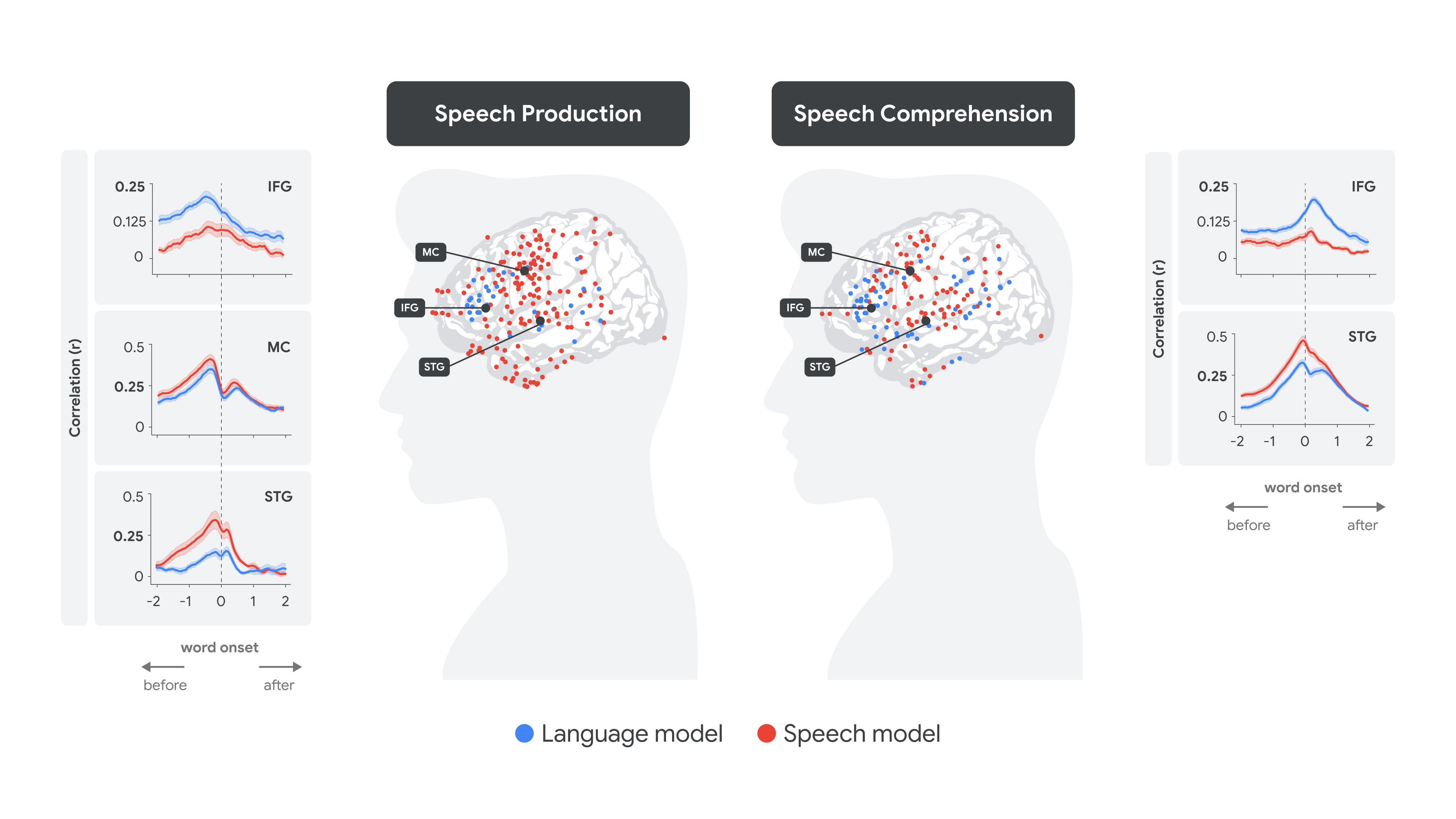
The quantitative results of the whole-brain analysis are illustrated in figure below: for each word, given its speech embeddings (red) and language embedding (blue), we predicted the neural response in each electrode at time lags ranging from -2 seconds before to +2 seconds after the word onset (x-axis value of 0 in the figure). This was done during speech production (left panel) and speech comprehension (right panel). The related graphs illustrate the accuracy of our predictions of neural activity (correlation) for all words as a function of the lag in the electrodes across various brain regions.
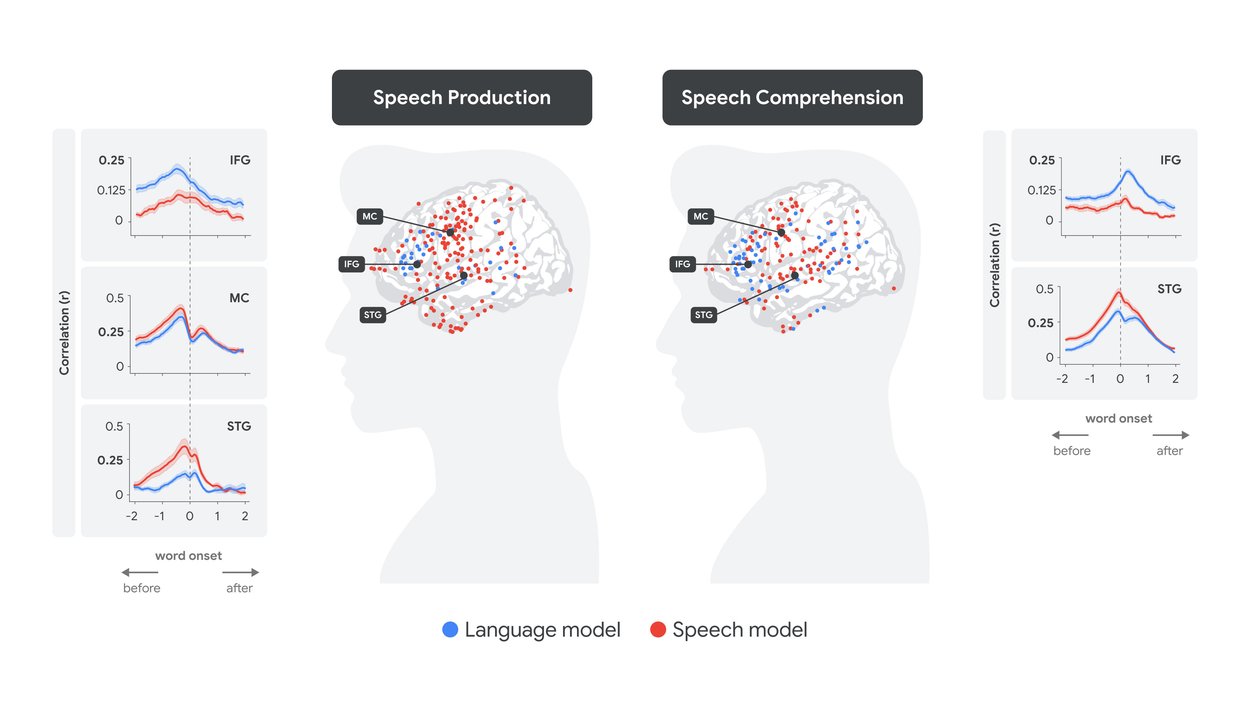
Fitting speech and language embeddings to human brain signals at production and comprehension.
During speech production, it is evident that language embeddings (blue) in the IFG peaked before speech embeddings (red) peaked in the sensorimotor area, followed by the peak of speech encoding in the STG. In contrast, during speech comprehension, the peak encoding shifted to after the word onset, with speech embeddings (red) in the STG peaking significantly before language encoding (blue) in the IFG.
All in all, our findings suggest that the speech-to-text model embeddings provide a cohesive framework for understanding the neural basis of processing language during natural conversations. Surprisingly, while Whisper was developed solely for speech recognition, without considering how the brain processes language, we found that its internal representations align with neural activity during natural conversations. This alignment was not guaranteed — a negative result would have shown little to no correspondence between the embeddings and neural signals, indicating that the model's representations did not capture the brain's language processing mechanisms.
A particularly intriguing concept revealed by the alignment between LLMs and the human brain is the notion of a "soft hierarchy" in neural processing. Although regions of the brain involved in language, such as the IFG, tend to prioritize word-level semantic and syntactic information — as indicated by stronger alignment with language embeddings (blue) — they also capture lower-level auditory features, which is evident from the lower yet significant alignment with speech embeddings (red). Conversely, lower-order speech areas such as the STG tend to prioritize acoustic and phonemic processing — as indicated by stronger alignment with speech embeddings (red) — they also capture word-level information, evident from the lower yet significant alignment with language embeddings (blue).
Shared objectives and geometry between LLMs and the human brain
LLMs are trained to process natural language by using a simple objective: predicting the next word in a sequence. In a paper published in Nature Neuroscience, we discovered that, similar to LLMs, the language areas of a listener’s brain attempt to predict the next word before it is spoken. Furthermore, like LLMs, listeners' confidence in their predictions before the word’s onset modifies their surprise level (prediction error) after the word is articulated. These findings provide compelling new evidence for fundamental computational principles of pre-onset prediction, post-onset surprise, and embedding-based contextual representation shared by autoregressive LLMs and the human brain. In another paper published in Nature Communications, the team also discovered that the relation among words in natural language, as captured by the geometry of the embedding space of an LLM, is aligned with the geometry of the representation induced by the brain (i.e., brain embeddings) in language areas.
Differences between how LLMs and the human brain process natural language
While the human brain and Transformer-based LLMs share fundamental computational principles in processing natural language, their underlying neural circuit architectures are markedly different. For example, in a follow-up study, we investigated how information is processed across layers in Transformer-based LLMs compared to the human brain. The team found that while the non-linear transformations across layers are similar in LLMs and language areas in the human brain, the implementations differ significantly. Unlike the Transformer architecture, which processes hundreds to thousands of words simultaneously, the language areas appear to analyze language serially, word by word, recurrently, and temporally.
Summary and future directions
The accumulated evidence from the team’s work uncovered several shared computational principles between how the human brain and deep learning models process natural language. These findings indicate that deep learning models could offer a new computational framework for understanding the brain's neural code for processing natural language based on principles of statistical learning, blind optimization, and a direct fit to nature. At the same time, there are significant differences between the neural architecture, types and scale of linguistic data, the training protocols of Transformer-based language models, and the biological structure and developmental stages through which the human brain naturally acquires language in social settings environments. Moving forward, our goal is to create innovative, biologically inspired artificial neural networks that have improved capabilities for processing information and functioning in the real world. We plan to achieve this by adapting neural architecture, learning protocols, and training data that better match human experiences.
Acknowledgments
The work described is the result of Google Research's long-term collaboration with the Hasson Lab at the Neuroscience Institute and the Psychology Department at Princeton University, the DeepCognitionLab at the Hebrew University Business School and Cognitive Department, and researchers from the NYU Langone Comprehensive Epilepsy Center.
Quick links
Other posts of interest
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing