Deciding Which Tasks Should Train Together in Multi-Task Neural Networks
October 25, 2021
Posted by Christopher Fifty, Research Engineer, Google Research, Brain Team
Quick links
Many machine learning (ML) models typically focus on learning one task at a time. For example, language models predict the probability of a next word given a context of past words, and object detection models identify the object(s) that are present in an image. However, there may be instances when learning from many related tasks at the same time would lead to better modeling performance. This is addressed in the domain of multi-task learning, a subfield of ML in which multiple objectives are trained within the same model at the same time.
Consider a real-world example: the game of ping-pong. When playing ping-pong, it is often advantageous to judge the distance, spin, and imminent trajectory of the ping-pong ball to adjust your body and line up a swing. While each of these tasks are unique — predicting the spin of a ping-pong ball is fundamentally distinct from predicting its location — improving your reasoning of the location and spin of the ball will likely help you better predict its trajectory and vice-versa. By analogy, within the realm of deep learning, training a model to predict three related tasks (i.e., the location, spin, and trajectory of a ping-pong ball) may result in improved performance over a model that only predicts a single objective.
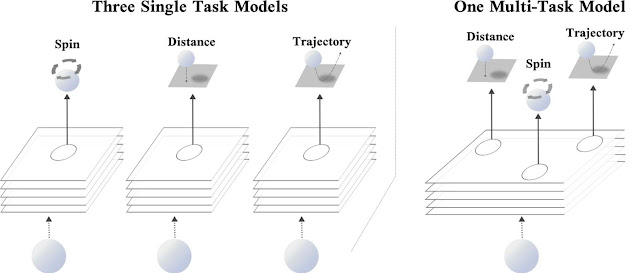 |
| Left: Three single-task networks, each of which uses the same input to predict the spin, distance, or trajectory of the ping-pong ball, respectively. Right: A single multi-task network that simultaneously predicts the spin, distance, and trajectory. |
In “Efficiently Identifying Task Groupings in Multi-Task Learning”, a spotlight presentation at NeurIPS 2021, we describe a method called Task Affinity Groupings (TAG) that determines which tasks should be trained together in multi-task neural networks. Our approach attempts to divide a set of tasks into smaller subsets such that the performance across all tasks is maximized. To accomplish this goal, it trains all tasks together in a single multi-task model and measures the degree to which one task’s gradient update on the model’s parameters would affect the loss of the other tasks in the network. We denote this quantity as inter-task affinity. Our experimental findings indicate that selecting groups of tasks that maximize inter-task affinity correlates strongly with overall model performance.
Which Tasks Should Train Together?
In the ideal case, a multi-task learning model will apply the information it learns during training on one task to decrease the loss on other tasks included in training the network. This transfer of information leads to a single model that can not only make multiple predictions, but may also exhibit improved accuracy for those predictions when compared with the performance of training a different model for each task. On the other hand, training a single model on many tasks may lead to competition for model capacity and severely degrade performance. This latter scenario often occurs when tasks are unrelated. Returning to our ping-pong analogy, imagine trying to predict the location, spin, and trajectory of the ping-pong ball while simultaneously recounting the Fibonnaci sequence. Not a fun prospect, and most likely detrimental to your progression as a ping-pong player.
One direct approach to select the subset of tasks on which a model should train is to perform an exhaustive search over all possible combinations of multi-task networks for a set of tasks. However, the cost associated with this search can be prohibitive, especially when there are a large number of tasks, because the number of possible combinations increases exponentially with respect to the number of tasks in the set. This is further complicated by the fact that the set of tasks to which a model is applied may change throughout its lifetime. As tasks are added to or dropped from the set of all tasks, this costly analysis would need to be repeated to determine new groupings. Moreover, as the scale and complexity of models continues to increase, even approximate task grouping algorithms that evaluate only a subset of possible multi-task networks may become prohibitively costly and time-consuming to evaluate.
Building Task Affinity Groupings
In examining this challenge, we drew inspiration from meta-learning, a domain of machine learning that trains a neural network that can be quickly adapted to a new, and previously unseen task. One of the classic meta-learning algorithms, MAML, applies a gradient update to the models’ parameters for a collection of tasks and then updates its original set of parameters to minimize the loss for a subset of tasks in that collection computed at the updated parameter values. Using this method, MAML trains the model to learn representations that will not minimize the loss for its current set of weights, but rather for the weights after one or more steps of training. As a result, MAML trains a models’ parameters to have the capacity to quickly adapt to a previously unseen task because it optimizes for the future, not the present.
TAG employs a similar mechanism to gain insight into the training dynamics of multi-task neural networks. In particular, it updates the model’s parameters with respect only to a single task, looks at how this change would affect the other tasks in the multi-task neural network, and then undoes this update. This process is then repeated for every other task to gather information on how each task in the network would interact with any other task. Training then continues as normal by updating the model’s shared parameters with respect to every task in the network.
Collecting these statistics, and looking at their dynamics throughout training, reveals that certain tasks consistently exhibit beneficial relationships, while some are antagonistic towards each other. A network selection algorithm can leverage this data in order to group tasks together that maximize inter-task affinity, subject to a practitioner’s choice of how many multi-task networks can be used during inference.
 |
| Overview of TAG. First, tasks are trained together in the same network while computing inter-task affinities. Second, the network selection algorithm finds task groupings that maximize inter-task affinity. Third, the resulting multi-task networks are trained and deployed. |
Results
Our experimental findings indicate that TAG can select very strong task groupings. On the CelebA and Taskonomy datasets, TAG is competitive with the prior state-of-the-art, while operating between 32x and 11.5x faster, respectively. On the Taskonomy dataset, this speedup translates to 2,008 fewer Tesla V100 GPU hours to find task groupings.
Conclusion
TAG is an efficient method to determine which tasks should train together in a single training run. The method looks at how tasks interact through training, notably, the effect that updating the model’s parameters when training on one task would have on the loss values of the other tasks in the network. We find that selecting groups of tasks to maximize this score correlates strongly with model performance.
Acknowledgements
We would like to thank Ehsan Amid, Zhe Zhao, Tianhe Yu, Rohan Anil, and Chelsea Finn for their fundamental contributions to this work. We also recognize Tom Small for designing the animation, and Google Research as a whole for fostering a collaborative and uplifting research environment.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence