Data Cascades in Machine Learning
June 4, 2021
Nithya Sambasivan, Research Scientist, Google Research
Quick links
Data is a foundational aspect of machine learning (ML) that can impact performance, fairness, robustness, and scalability of ML systems. Paradoxically, while building ML models is often highly prioritized, the work related to data itself is often the least prioritized aspect. This data work can require multiple roles (such as data collectors, annotators, and ML developers) and often involves multiple teams (such as database, legal, or licensing teams) to power a data infrastructure, which adds complexity to any data-related project. As such, the field of human-computer interaction (HCI), which is focused on making technology useful and usable for people, can help both to identify potential issues and to assess the impact on models when data-related work is not prioritized.
In “‘Everyone wants to do the model work, not the data work’: Data Cascades in High-Stakes AI”, published at the 2021 ACM CHI Conference, we study and validate downstream effects from data issues that result in technical debt over time (defined as "data cascades"). Specifically, we illustrate the phenomenon of data cascades with the data practices and challenges of ML practitioners across the globe working in important ML domains, such as cancer detection, landslide detection, loan allocation and more — domains where ML systems have enabled progress, but also where there is opportunity to improve by addressing data cascades. This work is the first that we know of to formalize, measure, and discuss data cascades in ML as applied to real-world projects. We further discuss the opportunity presented by a collective re-imagining of ML data as a high priority, including rewarding ML data work and workers, recognizing the scientific empiricism in ML data research, improving the visibility of data pipelines, and improving data equity around the world.
Origins of Data Cascades
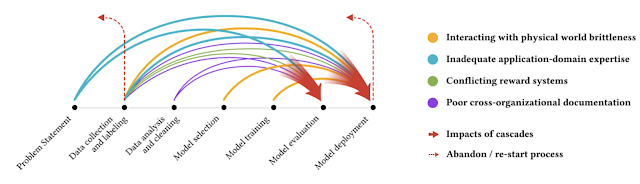
We observe that data cascades often originate early in the lifecycle of an ML system, at the stage of data definition and collection. Cascades also tend to be complex and opaque in diagnosis and manifestation, so there are often no clear indicators, tools, or metrics to detect and measure their effects. Because of this, small data-related obstacles can grow into larger and more complex challenges that affect how a model is developed and deployed. Challenges from data cascades include the need to perform costly system-level changes much later in the development process, or the decrease in users’ trust due to model mis-predictions that result from data issues. Nevertheless and encouragingly, we also observe that such data cascades can be avoided through early interventions in ML development.
 |
| Different color arrows indicate different types of data cascades, which typically originate upstream, compound over the ML development process, and manifest downstream. |
Examples of Data Cascades
One of the most common causes of data cascades is when models that are trained on noise-free datasets are deployed in the often-noisy real world. For example, a common type of data cascade originates from model drifts, which occur when target and independent variables deviate, resulting in less accurate models. Drifts are more common when models closely interact with new digital environments — including high-stakes domains, such as air quality sensing, ocean sensing, and ultrasound scanning — because there are no pre-existing and/or curated datasets. Such drifts can lead to more factors that further decrease a model’s performance (e.g., related to hardware, environmental, and human knowledge). For example, to ensure good model performance, data is often collected in controlled, in-house environments. But in the live systems of new digital environments with resource constraints, it is more common for data to be collected with physical artefacts such as fingerprints, shadows, dust, improper lighting, and pen markings, which can add noise that affects model performance. In other cases, environmental factors such as rain and wind can unexpectedly move image sensors in deployment, which also trigger cascades. As one of the model developers we interviewed reported, even a small drop of oil or water can affect data that could be used to train a cancer prediction model, therefore affecting the model’s performance. Because drifts are often caused by the noise in real-world environments, they also take the longest — up to 2-3 years — to manifest, almost always in production.
Another common type of data cascade can occur when ML practitioners are tasked with managing data in domains in which they have limited expertise. For instance, certain kinds of information, such as identifying poaching locations or data collected during underwater exploration, rely on expertise in the biological sciences, social sciences, and community context. However, some developers in our study described having to take a range of data-related actions that surpassed their domain expertise — e.g., discarding data, correcting values, merging data, or restarting data collection — leading to data cascades that limited model performance. The practice of relying on technical expertise more than domain expertise (e.g., by engaging with domain experts) is what appeared to set off these cascades.
Two other cascades observed in this paper resulted from conflicting incentives and organizational practices between data collectors, ML developers, and other partners — for example, one cascade was caused by poor dataset documentation. While work related to data requires careful coordination across multiple teams, this is especially challenging when stakeholders are not aligned on priorities or workflows.
How to Address Data Cascades
Addressing data cascades requires a multi-part, systemic approach in ML research and practice:
- Develop and communicate the concept of goodness of the data that an ML system starts with, similar to how we think about goodness of fit with models. This includes developing standardized metrics and frequently using those metrics to measure data aspects like phenomenological fidelity (how accurately and comprehensively does the data represent the phenomena) and validity (how well the data explains things related to the phenomena captured by the data), similar to how we have developed good metrics to measure model performance, like F1-scores.
- Innovate on incentives to recognize work on data, such as welcoming empiricism on data in conference tracks, rewarding dataset maintenance, or rewarding employees for their work on data (collection, labelling, cleaning, or maintenance) in organizations.
- Data work often requires coordination across multiple roles and multiple teams, but this is quite limited currently (partly, but not wholly, because of the previously stated factors). Our research points to the value of fostering greater collaboration, transparency, and fairer distribution of benefits between data collectors, domain experts, and ML developers, especially with ML systems that rely on collecting or labelling niche datasets.
- Finally, our research across multiple countries indicates that data scarcity is pronounced in lower-income countries, where ML developers face the additional problem of defining and hand-curating new datasets, which makes it difficult to even start developing ML systems. It is important to enable open dataset banks, create data policies, and foster ML literacy of policy makers and civil society to address the current data inequalities globally.
Conclusion
In this work we both provide empirical evidence and formalize the concept of data cascades in ML systems. We hope to create an awareness of the potential value that could come from incentivising data excellence. We also hope to introduce an under-explored but significant new research agenda for HCI. Our research on data cascades has led to evidence-backed, state-of-the-art guidelines for data collection and evaluation in the revised PAIR Guidebook, aimed at ML developers and designers.
Acknowledgements
This paper was written in collaboration with Shivani Kapania, Hannah Highfill, Diana Akrong, Praveen Paritosh and Lora Aroyo. We thank our study participants, and Sures Kumar Thoddu Srinivasan, Jose M. Faleiro, Kristen Olson, Biswajeet Malik, Siddhant Agarwal, Manish Gupta, Aneidi Udo-Obong, Divy Thakkar, Di Dang, and Solomon Awosupin.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
