Crowdsourcing a Text-to-Speech Voice for Low-Resource Languages (Episode 1)
September 9, 2015
Posted by Linne Ha, Senior Program Manager, Google Research for Low Resource Languages
Quick links
Building a decent text-to-speech (TTS) voice for any language can be challenging, but creating one – a good, intelligible one – for a low resource language can be downright impossible. By definition, working with low resource languages can feel like a losing proposition – from the get go, there is not enough audio data, and the data that exists may be questionable in quality. High quality audio data, and lots of it, is key to developing a high quality machine learning model. To make matters worse, most of the world’s oldest, richest spoken languages fall into this category. There are currently over 300 languages, each spoken by at least one million people, and most will be overlooked by technologists for various reasons. One important reason is that there is not enough data to conduct meaningful research and development.
Project Unison is an on-going Google research effort, in collaboration with the Speech team, to explore innovative approaches to building a TTS voice for low resource languages – quickly, inexpensively and efficiently. This blog post will be one of several to track progress of this experiment and to share our experience with the research community at large – our successes and failures in a trial and error, iterative approach – as our adventure plays out.
One of the most critical aspects of building a TTS system is acquiring audio data. The traditional way to do this is in a professional recording studio with a voice talent, sound engineer and a voice director. The process can take considerable time and can be quite expensive. People often mistake voice talent work to be similar to a news reader, but it is highly specialized and the work can be very difficult.
Such investments in time and money may yield great audio, but the catch is that even if you’ve created the best TTS voice from these recordings, at best it will still sound exactly like the voice talent - the person who provided the raw audio data. (We’ve read the articles about people who have fallen for their GPS voice to find that they are real people with real names.) So the interesting problem here from a research perspective is how to create a voice that sounds human but is not identifiable as a singular person.
Crowd-sourcing projects for automatic speech recognition (ASR) for Google Voice Search had been successful in the past, with public volunteers eager to participate by providing voice samples. For ASR, the objective is to collect from a diversity of speakers and environments, capturing varying regional accents. The polar opposite is true of TTS, where one unique speaker, with the standard accent and in a soundproof studio is the basic criteria.
Many years ago, Yannis Agiomyrgiannakis, Digital Signal Processing researcher on the TTS team in Google London, wrote a “manifesto” for acoustic data collection for 2000 languages. In his document, he gave technical specifications on how to convert an average room into a recording studio. Knot Pipatsrisawat, software engineer in Google Research for Low Resource Languages, built a tool that we call “ChitChat”, a portable recording studio, using Yannis’ specifications. This web app allows users to read the prompt, playback the recording and even assess the noise level of the room.

Now we needed multiple speakers of a single language. For us, it was a no-brainer to pilot Project Unison with Bangladeshi Googlers, all of whom are passionate about getting Google products to their home country (the success of Android products in Bangladesh is an example of this). Googlers by and large are passionate about their work and many offer their 20% time as a way to help, to improve or to experiment on something that may or may not work because they care. The Bangladeshi Googlers are no exception. They embodied our objectives for a crowdsourcing innovation: out of many, we could achieve (literally) one voice.
With multiple speakers, we would target speakers of similar vocal profiles and adapt them to create a blended voice. Statistical parametric synthesis is not new, but the advances in recent technology have improved quality and proved to be a lightweight solution for a project like ours.
In May of this year, we auditioned 15 Bangaldeshi Googlers in Mountain View. From these recordings, the broader Bangladeshi Google community voted blindly for their preferred voice. Zakaria Haque, software engineer in Machine Intelligence, was chosen as our reference for the Bangla voice. We then narrowed down the group to five speakers based on these criteria: Dhaka accent, male (to match Zakaria’s), similarity in pitch and tone, and availability for recordings. The original plan of a spectral analysis using PRAAT proved to be unnecessary with our limited pool of candidates.
All 5 software engineers – Ahmed Chowdury, Mohammad Hossain, Syeed Faiz, Md. Arifuzzaman Arif, Sabbir Yousuf Sanny – plus Zakaria Haque recorded over 3 days in the anechoic chamber, a makeshift sound-proofed room at the Mountain View campus just before Ramadan. HyunJeong Choe, who had helped with the Korean TTS recordings, directed our volunteers.
 |
| Left: TPM Mohammad Khan measures the distance from the speaker to the mic to keep the sound quality consistent across all speakers. Right: Analytical Linguist HyunJeong Choe coaches SWE Ahmed Chowdury on how to speak in a friendly, knowledgeable, "Googly" voice |
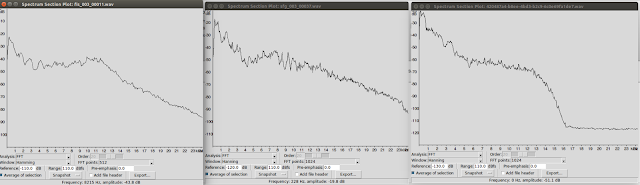
In this session, we discovered an issue: a sudden drop in amplitude at high frequencies in a few recordings. We were worried that all the recordings might have to be scrapped.
 |
| As illustrated in the third image, speaker3 has a drop in energy above 13kHz which is visible in the graph and may be present at speech, distorting the speaker’s voice to sound as if he were speaking through a tube. |
Deciding to proceed anyway, Alexander Gutkin, Speech software engineer and lead for TTS for Low Resource Languages in Google London, built an initial prototype voice. Using the preliminary text normalization rules created by Richard Sproat, Speech and Language Processing researcher, the first voice we attempted proved to be surprisingly good. The problem in the high frequencies we had seen in the recordings is undetectable in the parametric voice.
NEXT UP: Building a parametric voice with multiple speaker data (Ep.2)
-
Labels:
- Speech Processing
Quick links
Other posts of interest
-

December 3, 2025
From Waveforms to Wisdom: The New Benchmark for Auditory Intelligence- Machine Intelligence ·
- Sound & Accoustics ·
- Speech Processing
-

October 7, 2025
Speech-to-Retrieval (S2R): A new approach to voice search- Machine Intelligence ·
- Natural Language Processing ·
- Product ·
- Speech Processing
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing
×
❮
❯