Crisscrossed Captions: Semantic Similarity for Images and Text
May 6, 2021
Posted by Zarana Parekh, Software Engineer and Jason Baldridge, Staff Research Scientist, Google Research
Quick links
The past decade has seen remarkable progress on automatic image captioning, a task in which a computer algorithm creates written descriptions for images. Much of the progress has come through the use of modern deep learning methods developed for both computer vision and natural language processing, combined with large scale datasets that pair images with descriptions created by people. In addition to supporting important practical applications, such as providing descriptions of images for visually impaired people, these datasets also enable investigations into important and exciting research questions about grounding language in visual inputs. For example, learning deep representations for a word like “car”, means using both linguistic and visual contexts.
Image captioning datasets that contain pairs of textual descriptions and their corresponding images, such as MS-COCO and Flickr30k, have been widely used to learn aligned image and text representations and to build captioning models. Unfortunately, these datasets have limited cross-modal associations: images are not paired with other images, captions are only paired with other captions of the same image (also called co-captions), there are image-caption pairs that match but are not labeled as a match, and there are no labels that indicate when an image-caption pair does not match. This undermines research into how inter-modality learning (connecting captions to images, for example) impacts intra-modality tasks (connecting captions to captions or images to images). This is important to address, especially because a fair amount of work on learning from images paired with text is motivated by arguments about how visual elements should inform and improve representations of language.
To address this evaluation gap, we present "Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO", which was recently presented at EACL 2021. The Crisscrossed Captions (CxC) dataset extends the development and test splits of MS-COCO with semantic similarity ratings for image-text, text-text and image-image pairs. The rating criteria are based on Semantic Textual Similarity, an existing and widely-adopted measure of semantic relatedness between pairs of short texts, which we extend to include judgments about images as well. In all, CxC contains human-derived semantic similarity ratings for 267,095 pairs (derived from 1,335,475 independent judgments), a massive extension in scale and detail to the 50k original binary pairings in MS-COCO’s development and test splits. We have released CxC’s ratings, along with code to merge CxC with existing MS-COCO data. Anyone familiar with MS-COCO can thus easily enhance their experiments with CxC.
 |
| Crisscrossed Captions extends the MS-COCO evaluation sets by adding human-derived semantic similarity ratings for existing image-caption pairs and co-captions (solid lines), and it increases rating density by adding human ratings for new image-caption, caption-caption and image-image pairs (dashed lines).* |
Creating the CxC Dataset
If a picture is worth a thousand words, it is likely because there are so many details and relationships between objects that are generally depicted in pictures. We can describe the texture of the fur on a dog, name the logo on the frisbee it is chasing, mention the expression on the face of the person who has just thrown the frisbee, or note the vibrant red on a large leaf in a tree above the person’s head, and so on.
The CxC dataset extends the MS-COCO evaluation splits with graded similarity associations within and across modalities. MS-COCO has five captions for each image, split into 410k training, 25k development, and 25k test captions (for 82k, 5k, 5k images, respectively). An ideal extension would rate every pair in the dataset (caption-caption, image-image, and image-caption), but this is infeasible as it would require obtaining human ratings for billions of pairs.
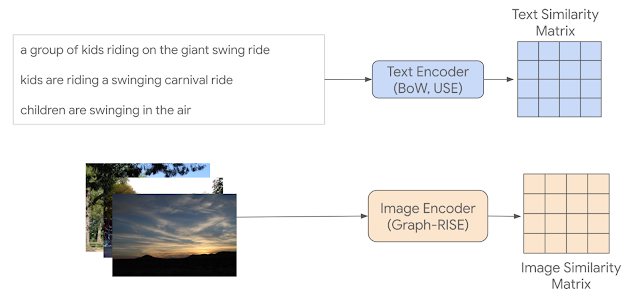
Given that randomly selected pairs of images and captions are likely to be dissimilar, we came up with a way to select items for human rating that would include at least some new pairs with high expected similarity. To reduce the dependence of the chosen pairs on the models used to find them, we introduce an indirect sampling scheme (depicted below) where we encode images and captions using different encoding methods and compute the similarity between pairs of same modality items, resulting in similarity matrices. Images are encoded using Graph-RISE embeddings, while captions are encoded using two methods — Universal Sentence Encoder (USE) and average bag-of-words (BoW) based on GloVe embeddings. Since each MS-COCO example has five co-captions, we average the co-caption encodings to create a single representation per example, ensuring all caption pairs can be mapped to image pairs (more below on how we select intermodality pairs).
 |
| Top: Text similarity matrix (each cell corresponds to a similarity score) constructed using averaged co-caption encodings, so each text entry corresponds to a single image, resulting in a 5k x 5k matrix. Two different text encoding methods were used, but only one text similarity matrix has been shown for simplicity. Bottom: Image similarity matrix for each image in the dataset, resulting in a 5k x 5k matrix. |
The next step of the indirect sampling scheme is to use the computed similarities of images for a biased sampling of caption pairs for human rating (and vice versa). For example, we select two captions with high computed similarities from the text similarity matrix, then take each of their images, resulting in a new pair of images that are different in appearance but similar in what they depict based on their descriptions. For example, the captions “A dog looking bashfully to the side” and “A black dog lifts its head to the side to enjoy a breeze” would have a reasonably high model similarity, so the corresponding images of the two dogs in the figure below could be selected for image similarity rating. This step can also start with two images with high computed similarities to yield a new pair of captions. We now have indirectly sampled new intramodal pairs — at least some of which are highly similar — for which we obtain human ratings.
 |
| Top: Pairs of images are picked based on their computed caption similarity. Bottom: Pairs of captions are picked based on the computed similarity of the images they describe. |
Last, we then use these new intramodal pairs and their human ratings to select new intermodal pairs for human rating. We do this by using existing image-caption pairs to link between modalities. For example, if a caption pair example ij was rated by humans as highly similar, we pick the image from example i and caption from example j to obtain a new intermodal pair for human rating. And again, we use the intramodal pairs with the highest rated similarity for sampling because this includes at least some new pairs with high similarity. Finally, we also add human ratings for all existing intermodal pairs and a large sample of co-captions.
The following table shows examples of semantic image similarity (SIS) and semantic image-text similarity (SITS) pairs corresponding to each rating, with 5 being the most similar and 0 being completely dissimilar.
 |
 |
 |
 |
 |
 |
| Examples for each human-derived similarity score (left: 5 to 0, 5 being very similar and 0 being completely dissimilar) of image pairs based on SIS (middle) and SITS (right) tasks. Note that these examples are for illustrative purposes and are not themselves in the CxC dataset. |
Evaluation
MS-COCO supports three retrieval tasks:
- Given an image, find its matching captions out of all other captions in the evaluation set.
- Given a caption, find its corresponding image out of all other images in the evaluation set.
- Given a caption, find its other co-captions out of all other captions in the evaluation set.
MS-COCO’s pairs are incomplete because captions created for one image at times apply equally well to another, yet these associations are not captured in the dataset. CxC enhances these existing retrieval tasks with new positive pairs, and it also supports a new image-image retrieval task. With its graded similarity judgements, CxC also makes it possible to measure correlations between model and human rankings. Retrieval metrics in general focus only on positive pairs, while CxC’s correlation scores additionally account for the relative ordering of similarity and include low-scoring items (non-matches). Supporting these evaluations on a common set of images and captions makes them more valuable for understanding inter-modal learning compared to disjoint sets of caption-image, caption-caption, and image-image associations.
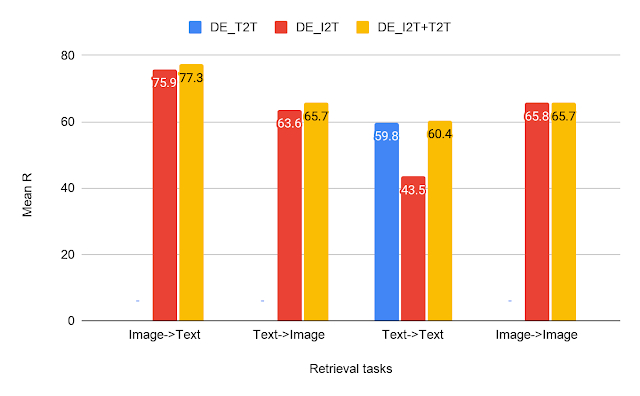
We ran a series of experiments to show the utility of CxC’s ratings. For this, we constructed three dual encoder (DE) models using BERT-base as the text encoder and EfficientNet-B4 as the image encoder:
- A text-text (DE_T2T) model that uses a shared text encoder for both sides.
- An image-text model (DE_I2T) that uses the aforementioned text and image encoders, and includes a layer above the text encoder to match the image encoder output.
- A multitask model (DE_I2T+T2T) trained on a weighted combination of text-text and image-text tasks.
 |
| CxC retrieval results — a comparison of our text-text (T2T), image-text (I2T) and multitask (I2T+T2T) dual encoder models on all the four retrieval tasks. |
From the results on the retrieval tasks, we can see that DE_I2T+T2T (yellow bar) performs better than DE_I2T (red bar) on the image-text and text-image retrieval tasks. Thus, adding the intramodal (text-text) training task helped improve the intermodal (image-text, text-image) performance. As for the other two intramodal tasks (text-text and image-image), DE_I2T+T2T shows strong, balanced performance on both of them.
 |
| CxC correlation results for the same models shown above. |
For the correlation tasks, DE_I2T performs the best on SIS and DE_I2T+T2T is the best overall. The correlation scores also show that DE_I2T performs well only on images: it has the highest SIS but has much worse STS. Adding the text-text loss to DE_I2T training (DE_I2T+T2T) produces more balanced overall performance.
The CxC dataset provides a much more complete set of relationships between and among images and captions than the raw MS-COCO image-caption pairs. The new ratings have been released and further details are in our paper. We hope to encourage the research community to push the state of the art on the tasks introduced by CxC with better models for jointly learning inter- and intra-modal representations.
Acknowledgments
The core team includes Daniel Cer, Yinfei Yang and Austin Waters. We thank Julia Hockenmaier for her inputs on CxC’s formulation, the Google Data Compute Team, especially Ashwin Kakarla and Mohd Majeed for their tooling and annotation support, Yuan Zhang, Eugene Ie for their comments on the initial versions of the paper and Daphne Luong for executive support for the data collection.
*All the images in the article have been taken from the Open Images dataset under the CC-by 4.0 license. ↩
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence