Conceptual Captions: A New Dataset and Challenge for Image Captioning
September 5, 2018
Posted by Piyush Sharma, Software Engineer and Radu Soricut, Research Scientist, Google AI
Quick links
The web is filled with billions of images, helping to entertain and inform the world on a countless variety of subjects. However, much of that visual information is not accessible to those with visual impairments, or with slow internet speeds that prohibit the loading of images. Image captions, manually added by website authors using Alt-text HTML, is one way to make this content more accessible, so that a natural-language description for images that can be presented using text-to-speech systems. However, existing human-curated Alt-text HTML fields are added for only a very small fraction of web images. And while automatic image captioning can help solve this problem, accurate image captioning is a challenging task that requires advancing the state of the art of both computer vision and natural language processing.
 |
| Image captioning can help millions with visual impairments by converting images captions to text. Image by Francis Vallance (Heritage Warrior), used under CC BY 2.0 license. |
 |
| Illustration of images and captions in the Conceptual Captions dataset. Clockwise from top left, images by Jonny Hunter, SigNote Cloud, Tony Hisgett, ResoluteSupportMedia. All images used under CC BY 2.0 license |
To generate the Conceptual Captions dataset, we start by sourcing images from the web that have Alt-text HTML attributes. We automatically screen these for certain properties to ensure image quality while also avoiding undesirable content such as adult themes. We then apply text-based filtering, removing captions with non-descriptive text (such as hashtags, poor grammar or added language that does not relate to the image); we also discard texts with high sentiment polarity or adult content (for more details on the filtering criteria, please see our paper). We use existing image classification models to make sure that, for any given image, there is overlap between its Alt-text (allowing for word variations) and the labels that the image classifier outputs for that image.
From Specific Names to General Concepts
While candidates passing the above filters tend to be good Alt-text image descriptions, a large majority use proper names (for people, venues, locations, organizations etc.). This is problematic because it is very difficult for an image captioning model to learn such fine-grained proper name inference from input image pixels, and also generate natural-language descriptions simultaneously1.
To address the above problems we wrote software that automatically replaces proper names with words representing the same general notion, i.e., with their concept. In some cases, the proper names are removed to simplify the text. For example, we substitute people names (e.g., “Former Miss World Priyanka Chopra on the red carpet” becomes “actor on the red carpet”), remove locations names (“Crowd at a concert in Los Angeles” becomes “Crowd at a concert”), remove named modifiers (e.g., “Italian cuisine” becomes just “cuisine”) and correct newly formed noun phrases if needed (e.g., “artist and artist” becomes “artists”, see the example illustration below).
 |
| Illustration of text modification. Image by Rockoleando used under CC BY 2.0 license. |
In the end, it required roughly one billion (English) webpages containing over 5 billion candidate images to obtain a clean and learnable image caption dataset of over 3M samples (a rejection rate of 99.94%). Our control parameters were biased towards high precision, although these can be tuned to generate an order of magnitude more examples with lower precision.
Dataset Impact
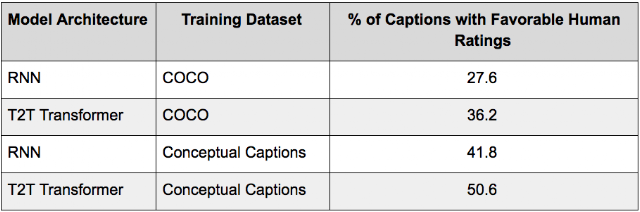
To test the usefulness of our dataset, we independently trained both RNN-based, and Transformer-based image captioning models implemented in Tensor2Tensor (T2T), using the MS-COCO dataset (using 120K images with 5 human annotated-captions per image) and the new Conceptual Captions dataset (using over 3.3M images with 1 caption per image). See our paper for more details on model architectures.
These models were tested using images from Flickr30K dataset (which are out-of-domain for both MS-COCO and Conceptual Captions), and the resulting captions evaluated using 3 human raters per test case. The results are reported in the table below.

Get Involved
It is our hope that this dataset will help the machine learning community advance the state of the art in image captioning models. Importantly, since no human annotators were involved in its creation, this dataset is highly scalable, potentially allowing the expansion of the dataset to enable automatic creation of Alt-text-HTML-like descriptions for an even wider variety of images. We encourage all those interested to partake in the Conceptual Captions Challenge, and we look forward to seeing what the community can do! For more details and the latest results please visit the challenge website.
Acknowledgements
Thanks to Nan Ding, Sebastian Goodman and Bo Pang for training models with Conceptual Captions dataset, and to Amol Wankhede for driving the public release efforts for the dataset.
1 In our paper, we posit that if automatic determination of names, locations, brands, etc. from the image is needed, it should be done as a separate task that may leverage image meta-information (e.g. GPS info), or complementary techniques such as OCR.↩
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯