
CodecLM: Aligning language models with tailored synthetic data
May 30, 2024
Zifeng Wang and Chen-Yu Lee, Research Scientists, Cloud AI Research Team
Quick links
Instruction tuning is a critical step in LLM alignment, i.e., shaping the behavior of large language models (LLMs) to better align with the intended objective. It involves fine-tuning a pre-trained LLM on a varied set of instructions, each paired with a desired output. This process enables the model to generalize across various tasks and formats, ultimately improving its performance in understanding and responding to user instructions. In essence, instruction tuning empowers LLMs to follow instructions more effectively, thereby making them more useful and reliable tools for a wide range of applications. Recent progress in instruction tuning highlights the critical role of high-quality data in enhancing LLMs' instruction-following capabilities. However, acquiring such data through human annotation remains cost-prohibitive and difficult to scale, hindering further progress.
Alternatively, recent work explores synthesizing instruction–response pairs for LLM alignment by prompting models with example data and iteratively refining the results. While these methods are effective at generating varied instructions for LLM alignment broadly, real-world applications often prioritize tailoring the LLM to specific downstream tasks such as individual enterprise applications or personal assistant agents, which often involve different instruction distributions. This need for task-specific alignment brings us to a core question for data synthesis: how can we tailor synthetic data to align LLMs for different instruction-following tasks?
In “CodecLM: Aligning Language Models with Tailored Synthetic Data”, presented at NAACL 2024, we present a novel framework, CodecLM, that systematically generates tailored high-quality data to align LLMs for specific downstream tasks. Inspired by the principles of the encode-decode process, we leverage a strong LLM (i.e., an LLM that has strong instruction-following capability for data synthesis, such as Gemini Pro or text-unicorn) as a codec, to encode seed instructions from our target task into instruction metadata (keywords that capture the use case of the instruction, and the skills required for an LLM to respond to the instruction). We then decode the metadata into tailored synthetic instructions. In the decoding process, we propose two complementary strategies, Self-Rubrics and Contrastive Filtering, to enhance synthetic data quality. Self-Rubrics leverages the strong LLM to generate rubrics and actions to make synthetic instruction more challenging. Contrastive Filtering further selects the instructions to which the target LLM (the LLM to be aligned) fails to respond well. CodecLM achieves state-of-the-art performance on open-domain instruction-following benchmarks with various LLMs, demonstrating its effectiveness in LLM alignment for varied instruction distributions.
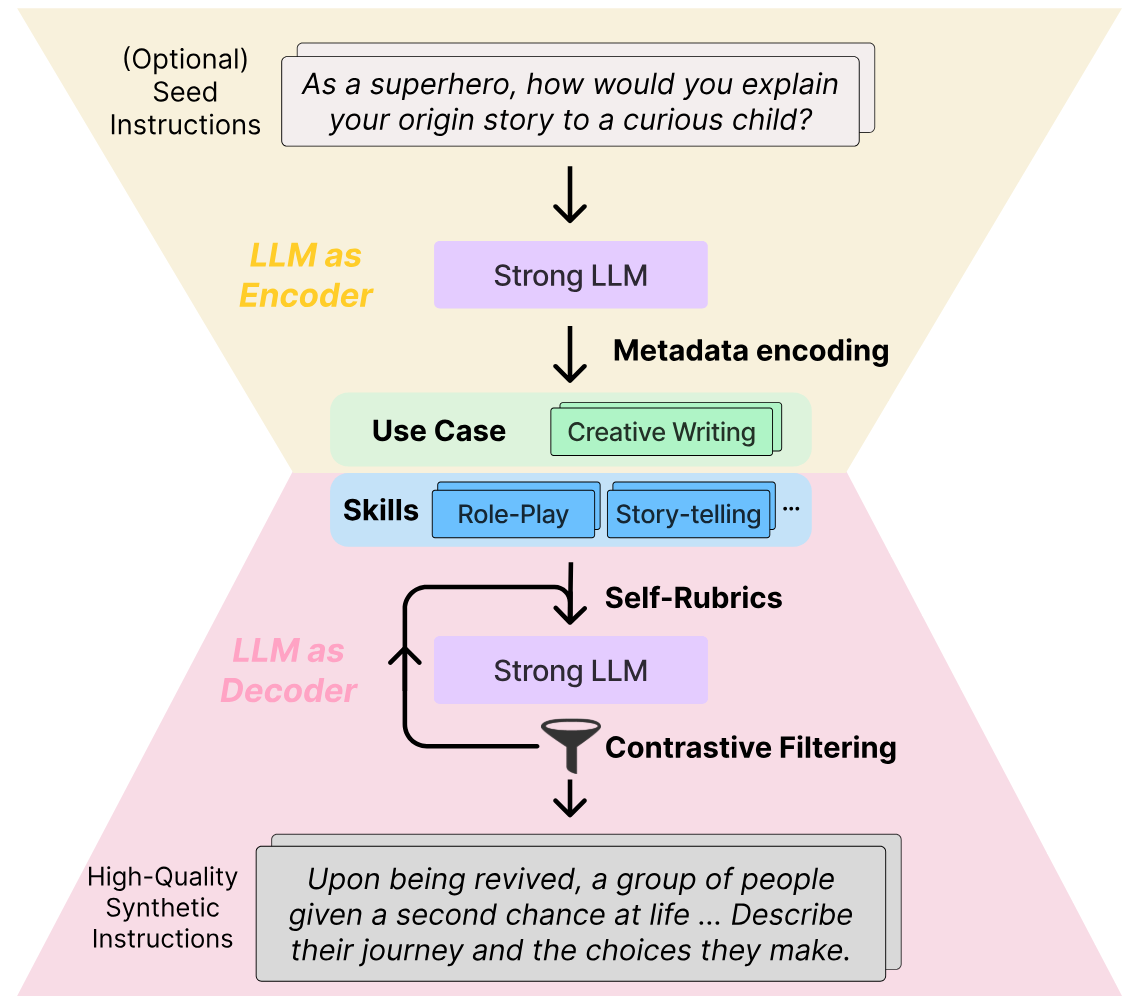
Overview of CodecLM. We first encode seed instructions into metadata to capture the underlying distribution of instructions. This metadata is then decoded through two complementary strategies, Self-Rubrics and Contrastive Filtering, to tailor high-quality synthetic instructions that are aligned with the target instruction distribution. Intermediate instructions and responses are omitted in the figure for clarity.
CodecLM
The core idea of CodecLM is to customize synthetic data for different downstream tasks, which can then be used to fine-tune an LLM for the tasks of interest. To achieve this goal, we need to make sure 1) the synthetic data’s distribution is similar to that of the real downstream data, and 2) the quality of synthetic data is high enough to improve the target LLM to be tuned.
First, the strong LLM encodes the seed instruction into instruction metadata, specifying its use case and skills required for responses. Next, the strong LLM decodes metadata into basic instructions. Meanwhile, Self-Rubrics (more below) leverages the strong LLM to generate rubrics and actions to improve the basic instruction, tailoring them for the downstream task. Finally, Contrastive Filtering (more below) uses a scoring function to compare answers from both the strong and target LLMs. The most effective pairs are selected for aligning the LLM, while less effective instructions are sent for further improvement. Animated below, the strong LLM's (refined) answer is winning against the target LLM's (simplistic) answer, indicating the improved synthetic instruction is challenging enough for the target LLM. Hence, we select the corresponding pair for instruction tuning the target LLM.
Detailed workflow of CodecLM.
Encoding instructions via metadata
To capture the underlying instruction distribution from the downstream task, we extract a word-level abstraction of the input instruction distribution through instruction metadata. We define the metadata as encompassing two key aspects: use case and skills. The use case describes the intended task (e.g., question answering or creative writing), while the skills are the knowledge the LLM must have to successfully respond to the given instruction (e.g., algorithms or communication). With the metadata from the seed instruction, we can readily prompt the strong LLM to generate synthetic instructions based on the extracted metadata.
Tailoring instructions via Self-Rubrics
With the above method, however, the quality of the synthetic instructions generated by simply prompting the LLM with the metadata may not be high. A recent study found that tuning LLMs with more complex instructions can improve performance, indicating that complex instructions are often considered high quality. A common practice is to work with human experts to craft general guidance to complicate instructions, such as “add reasoning steps” (more below). However, this strategy falls short for tailoring guidance to different tasks, like solving calculus problems versus writing news articles. Therefore, we introduce Self-Rubrics, which leverages the strong LLM to tailor instructions by adjusting their complexity according to the extracted metadata.
Self-Rubrics first guides the LLM to generate distinct rubrics for assessing the instruction complexity of each metadatum. Then, informed by these rubrics, the LLM generates a corresponding set of actions to enhance the instruction’s complexity. Such actions generated by Self-Rubrics are domain-specific and unambiguous — for example, for the use case of “business plan development” and skills of “market research and planning”, generic rules like “add reasoning steps” are vague. On the contrary, Self-Rubrics is able to generate actions like “add SWOT analysis” and “include comparison with market competitors” to complicate the instruction. With these instructions, one can iteratively prompt the strong LLM to tailor higher quality instructions.
Selecting instructions via Contrastive Filtering
While Self-Rubrics tailors complex instructions based on instruction metadata, not all instructions, regardless of their complexity, are equally effective for instruction tuning. Intuitively, identifying instructions an LLM finds challenging can expose opportunities for improvement. We therefore introduce Contrastive Filtering, a method to select the instructions that can enhance the target LLM.
Given an input instruction, we obtain two responses from the strong LLM (the one used for data synthesis) and the target LLM (the one we target for tuning), respectively. We then measure the quality gap between the two responses using LLM-as-a-Judge: we prompt the strong LLM to generate numerical scores (e.g., from 1 to 10) reflecting each response’s quality, and define the absolute difference between two scores as the quality gap. Intuitively, a larger gap often means the target LLM produces a worse response than the strong LLM. In this case, we add the instruction and the higher-scoring response to our final pool of high-quality synthetic data. On the other hand, a smaller quality gap indicates that such instructions are unlikely to improve performance. We then save such instructions for the next iteration of Self-Rubrics for further improvement.
Effectiveness of CodecLM
We demonstrate the effectiveness of CodecLM with PaLM 2 LLMs. In particular, we use text-unicorn as the strong LLM for data synthesis, and text-bison as the target LLM for instruction tuning. We conduct experiments on multiple widely-used open domain instruction-following benchmarks, which contain instructions for various forms and complexities of task types to test LLMs’ instruction-following ability. Here we focus on the results on the Vicuna (Benchmark 1) and Evol-Instruct (Benchmark 2) test sets. We compare CodecLM with representative baselines, including Alpagasus and WizardLM+ (an enhanced version of WizardLM). Inspired by the LLM-as-a-Judge approach, we conduct LLM-based pairwise comparisons between the instruction-tuned target LLM and the strong LLM to measure how much capacity the target LLM recovers from the strong LLM. We name this metric capacity recovery ratio (CRR), where 100% CRR means the tuned target LLM performs as good as the strong LLM on the specific test set.
Consistently better performance
CodecLM outperforms comparable methods consistently on all benchmarks, highlighting its generalizability to different downstream instruction distributions. Note that common data synthesis approaches do not take the downstream instruction distribution into account, while CodecLM is able to tailor instructions for different downstream tasks, thanks to the synergy between instruction metadata, Self-Rubrics and Contrastive Filtering. Our paper has more results and in-depth analysis.
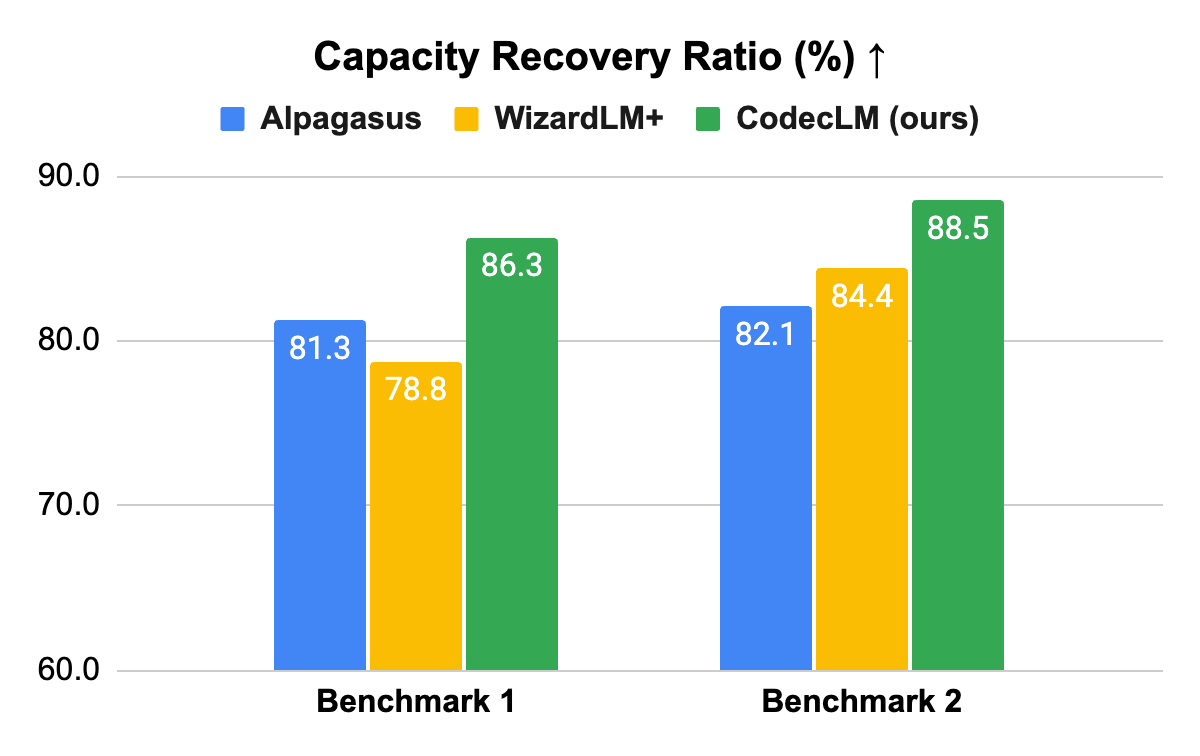
Results with PaLM 2–based target models on two open-domain instruction-following benchmarks. Each method trains a target model with synthetic data based on text-bison, and compares against the strong model, text-unicorn. Larger CRR means better performance.
Conclusion
Our proposed CodecLM is able to generate synthetic instruction-tuning data that is tailored to specific domains. We show that CodecLM effectively captures the underlying instruction distribution via instruction metadata, and further tailors the most effective instruction-response pairs through the novel strategies of Self-Rubrics and Contrastive Filtering. CodecLM provides a potent solution towards adapting LLMs for customized uses, without the necessity of human annotation. We believe CodecLM serves as a general framework for targeted LLM alignment, which opens the door to multiple promising research directions within the framework, such as richer metadata definition, better prompt design, and more reliable LLM-based scorers.
Acknowledgments
This research was conducted by Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister. Thanks to Chih-Kuan Yeh and Sergey Ioffe for their valuable feedback.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
Overview of CodecLM. We first encode seed instructions into metadata to capture the underlying distribution of instructions. This metadata is then decoded through two complementary strategies, Self-Rubrics and Contrastive Filtering, to tailor high-quality synthetic instructions that are aligned with the target instruction distribution. Intermediate instructions and responses are omitted in the figure for clarity.

Results with PaLM 2–based target models on two open-domain instruction-following benchmarks. Each method trains a target model with synthetic data based on text-bison, and compares against the strong model, text-unicorn. Larger CRR means better performance.