
ChatDirector: Enhancing video conferencing with space-aware scene rendering and speech-driven layout transition
May 29, 2024
Xun Qian, Research Scientist, and Ruofei Du, Interactive Perception & Graphics Lead, Google Augmented Reality
Quick links
Video conferencing systems are commonly used in both personal and professional settings. They allow individuals to participate in virtual meetings using standard devices, like laptops, displaying all attendees' live video feeds in a grid layout on a 2D screen. Despite their widespread adoption, this method of communication often lacks the fluidity and nuance of face-to-face interactions. Participants frequently face challenges in maintaining smooth communication and tracking the flow of conversation topics, largely due to missing vital spatial visual cues like eye contact.
We previously presented Visual Captions and open-sourced ARChat to facilitate verbal communication with real-time visuals. In “ChatDirector: Enhancing Video Conferencing with Space-Aware Scene Rendering and Speech-Driven Layout Transition”, presented at CHI 2024, we introduce a new prototype that enhances the traditional 2D-screen-based video conferencing experience by providing all participants with speech-driven visual assistance within a space-aware shared meeting environment.

ChatDirector facilitates verbal communication with spatialized video avatars, virtual environments, and automatic layout transitions.
Design considerations
We invited ten internal participants from varied roles across Google, including software engineers, researchers, and UX designers, to discuss factors that reduce the quality of virtual meetings. This discussion analyzed the traits of both video conferencing systems and face-to-face interactions that we distilled into five essential considerations for our prototype system (labeled DC1 to DC5, below).
- DC1: Enhance the virtual meeting environment with a space-aware visualization
Co-presence is crucial to improving the video conferencing experience. The system should adopt a typical in-person meeting setting by positioning attendees around a table with designated seats to foster a tangible sense of co-presence and spatial orientation. - DC2: Deliver speech-driven assistance that goes beyond simply replicating real-world gatherings
Given the frequent shifts in speakers and rapid topic transitions in group conversations, the system should offer additional digital features for participants to maintain awareness of the conversation flow and stay actively engaged in the meeting. - DC3: Reproduce visual cues from in-person interactions
Participants typically remain stationary in front of their computers during virtual meetings. The system should enhance their on-screen behaviors to mimic dynamic physical actions such as head turns and eye contact, which serve as subtle cues for following the conversation more effectively. - DC4: Minimize cognitive load
The system should avoid displaying excessive information simultaneously, or demanding frequent user actions. This approach would help prevent distractions and would allow participants to focus more effectively on listening and speaking. - DC5: Ensure compatibility and scalability
The system should be compatible with standard video conferencing equipment (e.g., laptops equipped with webcams) to promote widespread adoption. This compatibility will also facilitate the seamless integration of additional productivity features and tools, such as screen sharing and other applications, to enhance the overall utility of the system.
Space-aware scene rendering pipeline
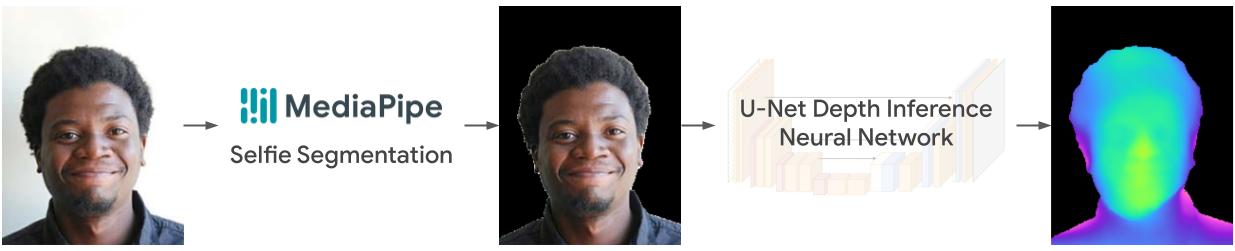
To address DC1 (“Enhance the virtual meeting environment with a space-aware visualization”) and DC5 (“Ensure compatibility and scalability”), we first designed a rendering pipeline to reconstruct one’s visual presence as a 3D portrait avatar. We built this on U-Net, a lightweight depth inference neural network, combined with a custom rendering approach, which takes the RGB and depth images as input and outputs a 3D portrait avatar mesh.
The pipeline starts from a deep learning (DL) network that infers the depth from the real-time RGB web camera video. It segments the foreground using the MediaPipe selfie segmentation model, and feeds the processed image to the U-Net neural network. An encoder gradually downscales the image, while a decoder increases the feature resolution back to the original resolution. DL features from the encoder are concatenated to the corresponding layers with the same resolution to aid in the recovery of geometrical details, e.g., depth boundaries and thin structures.
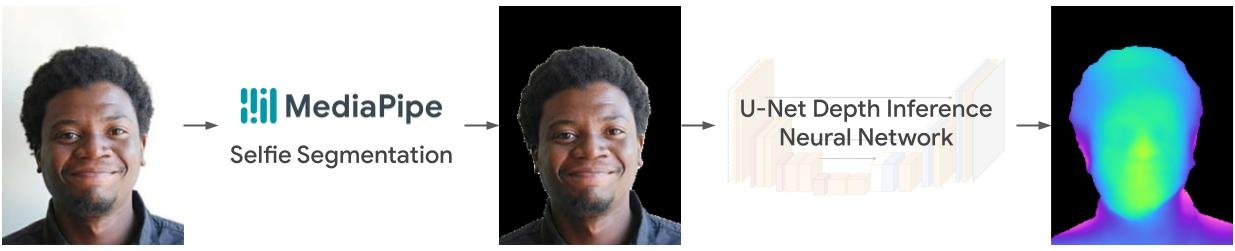
A real-time lightweight U-Net neural network infers the depth from a single RGB video stream.
Then, the custom rendering approach, shown below, takes in the RGB and depth images as input, and reconstructs a 3D portrait avatar.
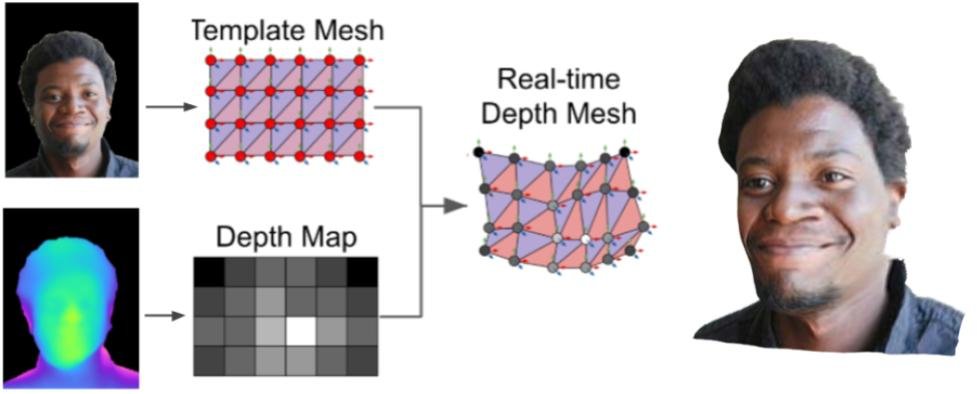
A custom rendering approach reconstructs a 3D portrait avatar using RGB and depth images.
We developed a space-aware video conferencing environment that displays remote participants’ 3D portrait avatars in a 3D meeting environment. On each local user’s device, ChatDirector streams out (1) the audio input together with the speech text recognized by the Web Speech API, and (2) the RGB image along with the depth image inferred by the U-Net neural network. Meanwhile, each remote user’s data is received, the 3D portrait avatar is reconstructed and displayed on the local user’s screen. To enable the visual parallax effect, we adjust the virtual rendering camera according to the local user’s head movement detected using MediaPipe Face Detection. The audio is used as the input to the speech-driven layout transition algorithm that will be explained in the next section. The data communication is achieved by WebRTC.
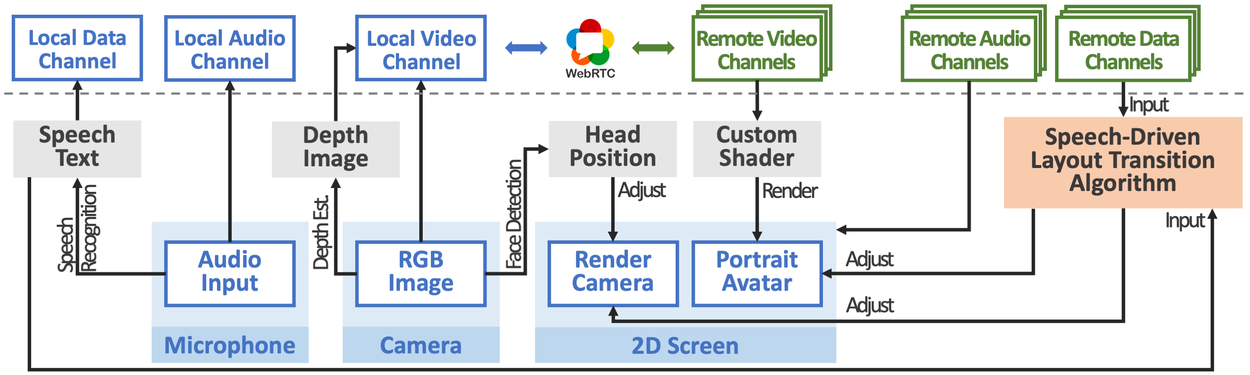
System architecture of ChatDirector.
A local user’s view of the space-aware video conferencing environment with 3D portrait avatars.
Speech-driven layout transition algorithm
To address DC2 (“Deliver speech-driven assistance that goes beyond simply replicating real-world gatherings”) and DC3 (“Reproduce visual cues from in-person interactions”), we developed a decision-tree algorithm that adjusts the layout of the rendered scene and the behaviors of the avatars based on ongoing conversations, allowing users to follow these conversations by receiving automatic visual assistance without additional effort per DC4 (“Minimize cognitive load”).
For the algorithm input, we model a group chat as a sequence of speech turns. At each moment, each attendee is in one of the three Speech States. (1) Quiet: the attendee is listening to others; (2) Talk-To: the attendee is talking to one specific person; or (3) Announce: the attendee is speaking to everyone. We use keyword detection to identify the Speech State via the Web Speech API. Talk-To is detected by listening for the participants’ names (which they entered when they joined the meeting room), and Announce is detected by user-defined and default keywords such as ‘everyone’, ‘ok, everybody’.
The algorithm produces two key outputs that enhance visual assistance (DC3). The first component, the Layout State, dictates the overall visualization of the meeting scene. This includes several modes: 'One-on-One', displaying only a single remote participant for direct interactions with the local user; 'Pairwise', which arranges two remote participants side-by-side to signify their one-on-one dialogue; and 'Full-view', the default setting that shows all participants, indicating general discourse.
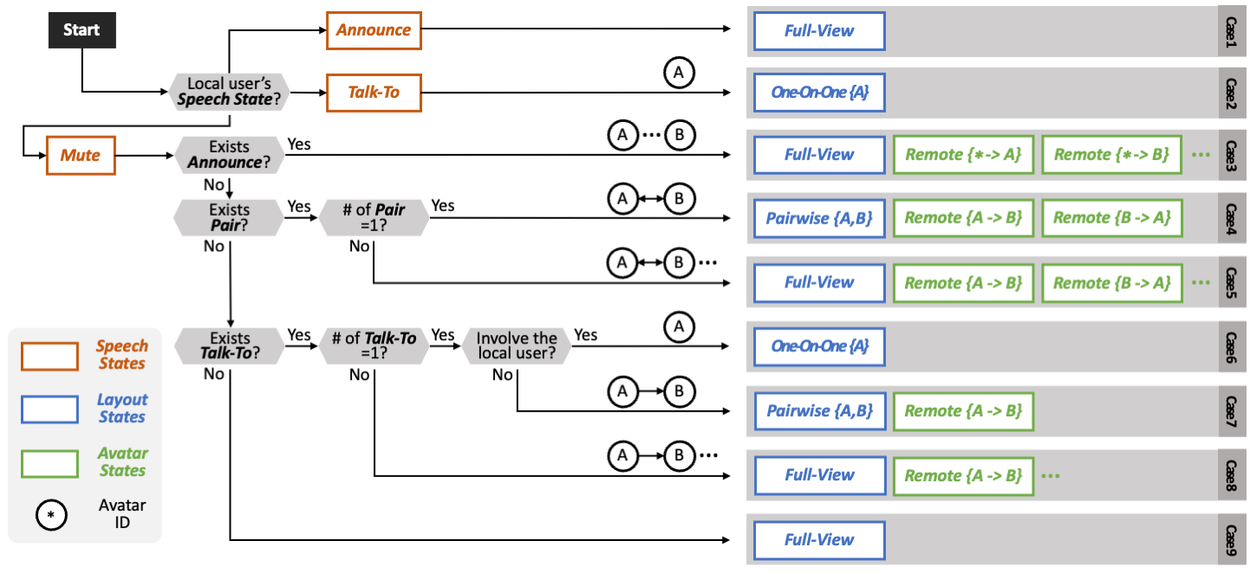
Layout transition algorithm of ChatDirector.

Algorithm Output: Layout State. Left: ‘One-on-One’ state. Center: ‘Pairwise’ state. Right: ‘Full-View’ state.
Thanks to our 3D portrait avatar rendering capability, we can simulate eye contact similar to that found in in-person meetings by manipulating the behaviors of remote avatars. We established the Avatar State as an additional output of the algorithm to control each avatar’s orientation. In this setup, each avatar can be in one of two states: the ‘Local’ state, where the avatar rotates to face the local user, and the ‘Remote’ state, where the avatar rotates to engage with another remote participant.
Algorithm output: Avatar State. When the left user talks to the right user, the Avatar State transitions from ‘Local’ state to ‘Remote’ state, where the left avatar rotates towards the right avatar.
Qualitative performance evaluation: User studies
To evaluate the performance of the speech-driven layout transition algorithm and the overall effectiveness of the space-aware meeting scene, we conducted a lab study involving 16 participants that were grouped into four teams. Using conventional video conferencing as a baseline, the study found that ChatDirector significantly improved issues related to speech handling, as evidenced by positive user ratings on attention transition assistance. A Wilcoxon Signed-Rank Test was conducted on the survey results.
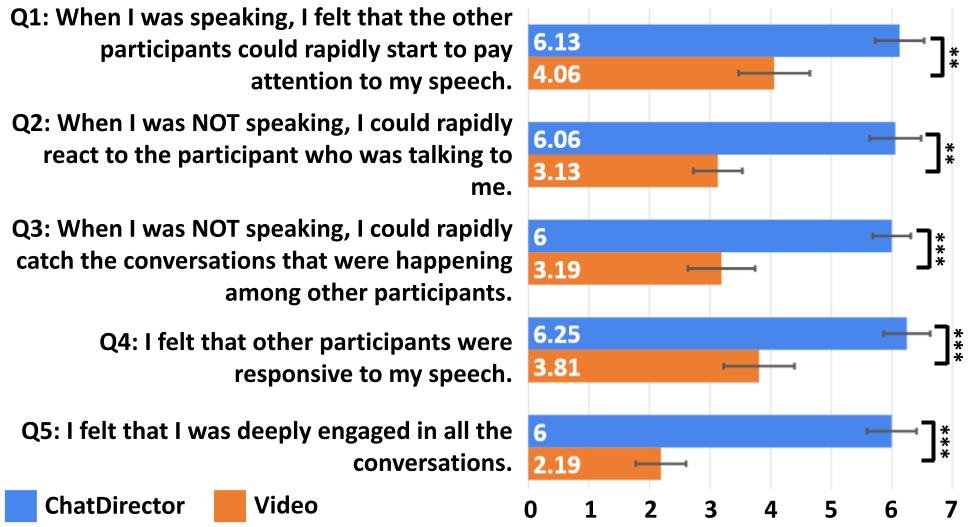
User study results of the space-aware meeting environment and the speech-driven layout transition algorithm (N=16). (*: p<.05, **: p<.01, ***: p< .001)
Additionally, it boosted co-presence and engagement compared to standard 2D-based video conferencing systems, as supported by the Temple Presence Inventory (TPI) ratings.
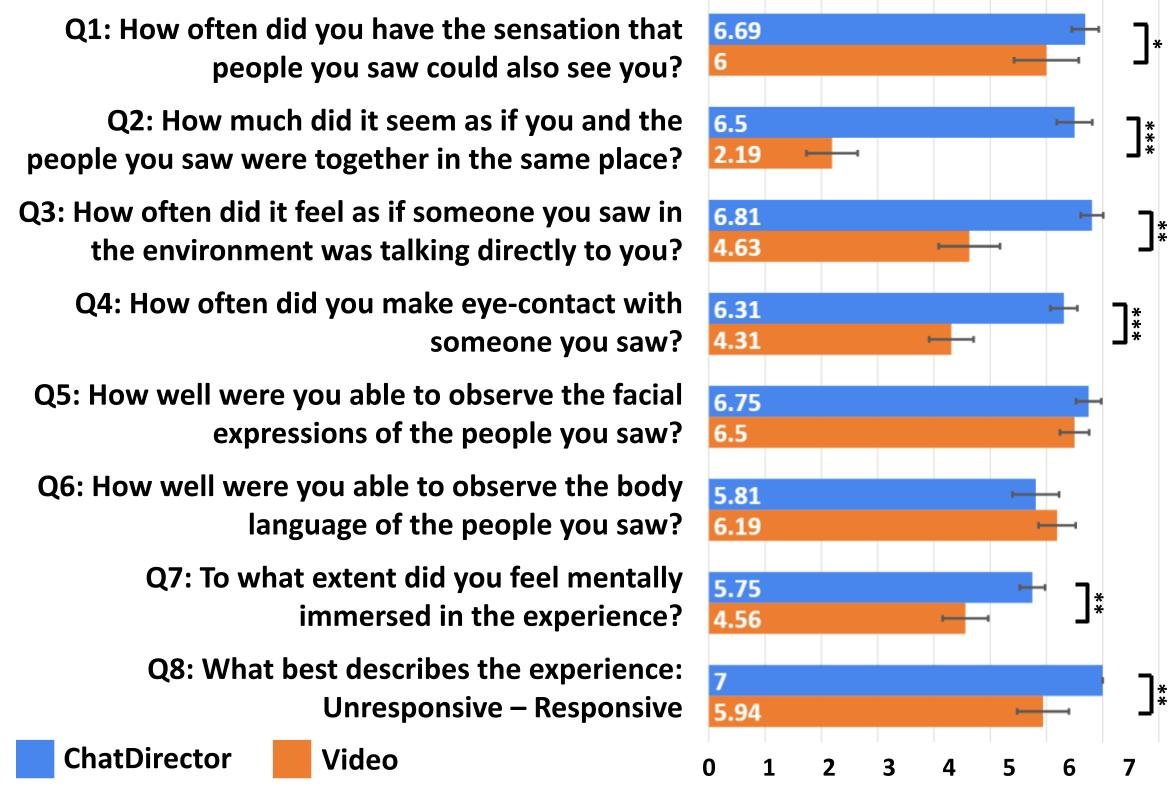
Temple Presence Inventory (TPI) results that indicate the social presence ratings of the ChatDirector system. (N=16). (*: p<.05, **: p<.01, ***: p< .001)
Conclusions and future directions
We introduce ChatDirector, a novel video conferencing prototype, designed to make video meetings more engaging and to enhance the feeling of co-presence using speech-driven visual cues in a space-aware scene. We present a real-time technical pipeline that renders remote participants as 3D portrait avatars in a shared 3D virtual environment without specialized equipment. Our contribution includes a speech-aware algorithm that dynamically adjusts the on-screen arrangement of remote participants and their behaviors, providing visual assistance to help in tracking and shifting attention. We hope that ChatDirector will inspire continued innovation in everyday computing platforms that leverage advanced perception and interaction techniques to increase the sense of co-presence and engagement. Meanwhile, it is important to address responsible AI considerations and the implications of digital likeness. Transforming users' video in this way can raise questions about their control over their likeness, requiring further research and careful consideration. It is crucial for such tools, when deployed, to operate based on user consent and adhere to ethical guidelines.
See a video that demonstrates ChatDirector’s interaction techniques below.
Acknowledgements
This research has been largely conducted by Xun Qian, Feitong Tan, Yinda Zhang, Brian Moreno Collins, Alex Olwal, David Kim, and Ruofei Du. We would like to extend our thanks to Benjamin Hersh, Eric Turner, Guru Somadder, Federico Tombari, Adarsh Kowdle, Zhengzhe Zhu, Liyun Xia, and Xiangyu Qu for providing feedback or assistance for the manuscript and the blog post.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product

System architecture of ChatDirector.
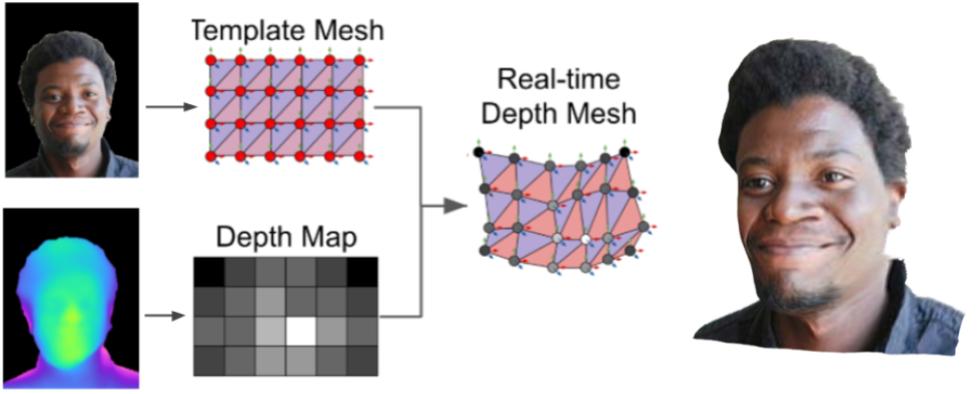
A custom rendering approach reconstructs a 3D portrait avatar using RGB and depth images.

User study results of the space-aware meeting environment and the speech-driven layout transition algorithm (N=16). (*: p<.05, **: p<.01, ***: p< .001)
A local user’s view of the space-aware video conferencing environment with 3D portrait avatars.

Algorithm Output: Layout State. Left: ‘One-on-One’ state. Center: ‘Pairwise’ state. Right: ‘Full-View’ state.

Temple Presence Inventory (TPI) results that indicate the social presence ratings of the ChatDirector system. (N=16). (*: p<.05, **: p<.01, ***: p< .001)
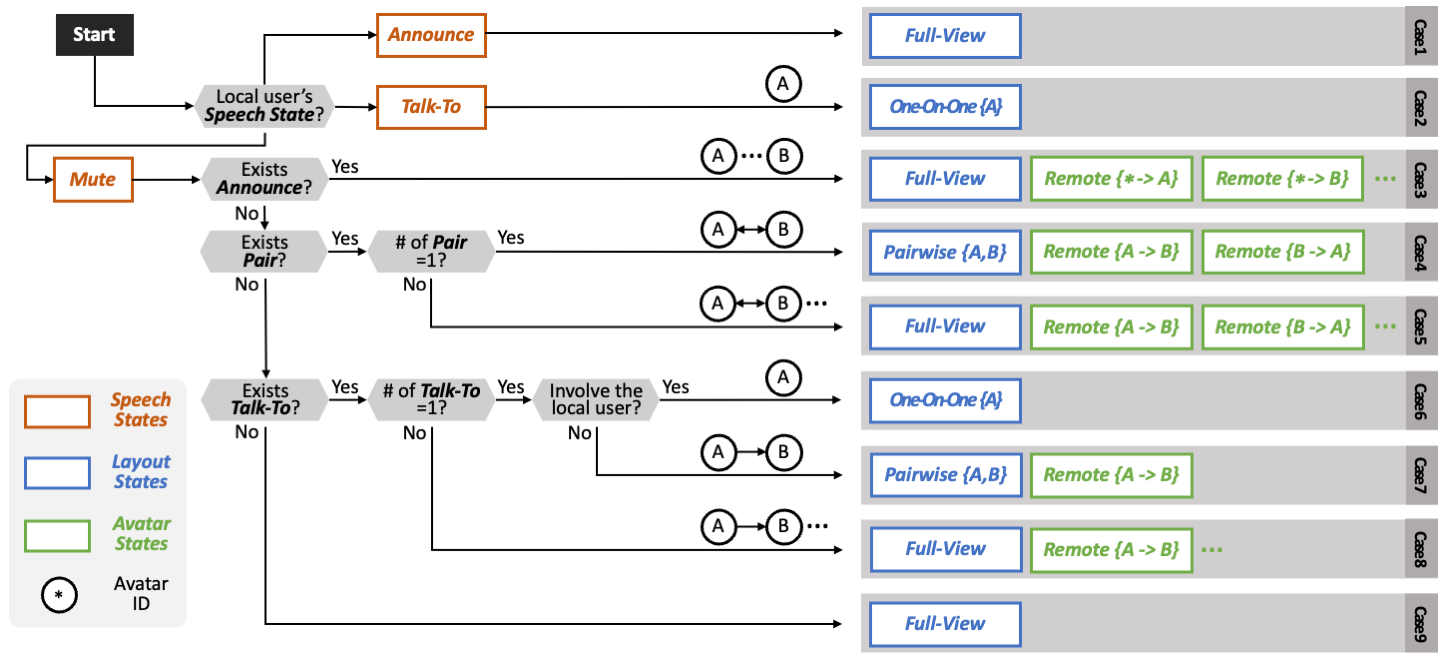
Layout transition algorithm of ChatDirector.
A real-time lightweight U-Net neural network infers the depth from a single RGB video stream.

ChatDirector facilitates verbal communication with spatialized video avatars, virtual environments, and automatic layout transitions.