Chain of Agents: Large language models collaborating on long-context tasks
January 23, 2025
Yusen Zhang, Student Researcher, and Ruoxi Sun, Research Scientist
We propose Chain-of-Agents, a training-free, task-agnostic, highly interpretable framework, which leverages LLM collaboration to solve long-context tasks, outperforming both RAG and long context LLMs.
Quick links
Over the past few years large language models (LLMs) have shown remarkable capabilities on various tasks, such as reasoning, knowledge retrieval, and generation. However, it is still challenging for LLMs to solve tasks that require long inputs, because they typically have limitations on input length, and hence, cannot utilize the full context. This issue hinders long context tasks, such as long summarization, question answering, and code completion.
To mitigate this, at NeurIPS 2024 we introduced Chain-of-Agents (CoA), a novel framework that harnesses multi-agent collaboration through natural language to enable information aggregation and context reasoning across various LLMs over long-context tasks. We perform a comprehensive evaluation of CoA on a wide range of long-context tasks, including question answering, summarization, and code completion. We demonstrate significant improvements (up to 10%) over strong baselines: retrieval augmented generation (RAG), multi-agent LLMs, and LLMs that have had their inputs truncated once the context window is full (called “full-context”).
A simple but effective approach to improve long-context understanding
Previous studies have mainly explored two major directions: input reduction and window extension. Input reduction reduces the length of the input context — for example, by directly truncating the input — before feeding to downstream LLMs. RAG extends this direction by breaking the input into chunks and then retrieving answers to the most relevant chunks based on embedding similarity. However, because of low retrieval accuracy, LLMs could receive an incomplete context for solving the task, hurting performance. Window extension extends the context window of LLMs via fine-tuning, training the model to consume longer inputs. For example, Gemini is able to directly process 2M tokens for each input. However, when the window becomes longer even than their extended input capacities, such LLMs still struggle to focus on the needed information to solve the task and suffer from ineffective context utilization. This long context approach is further complicated by the fact that the cost increases quadratically with length due to the design of the transformer architecture that underlies most LLMs.
Motivated by the aforementioned challenges, we designed CoA with inspiration from the way people interleave reading and processing of long contexts under our own limited working memory constraints. Whereas input reduction approaches need to start processing over shorter inputs (“read-then-process”), CoA breaks the input into chunks and then assigns workers to process each chunk sequentially before reading all of the input (“interleaved read-process”). Further, in contrast to context extension, CoA leverages the capacity of LLMs to communicate between agents rather than trying to feed a large number of tokens into the LLM. CoA is also compute cost–effective, significantly improving over full-context approaches, in particular, by reducing time complexity from n2 to nk, where n is the number of input tokens and k is the context limit of the LLM.
A novel approach to input processing
CoA contains two stages. In the first, a series of worker agents in charge of different chunks of long context collaborate and aggregate supporting data that can be used to answer the given query. To this end, the workers read and process sequentially, each receiving the message from the previous worker and transferring the useful updated information to the next. In the second stage, the manager agent receives the complete evidence from the last worker agent and generates the final response. Here is a motivating example:
Stage 1: Worker agent: Segment comprehension and chain-communication
In Stage 1, CoA contains a sequence of worker agents. Each worker receives an heuristically concatenated portion from the source text, the query, instructions for a specific task assigned to that agent, and the message passed from the previous agent. This communication chain is unidirectional, passing from each worker to the next in sequential order. The worker agents process each concatenated block and outputs a message for the next worker.
Stage 2: Manager agent: Information integration and response generation
In Stage 2, after multiple steps of information extraction and comprehension by worker agents, the manager agent produces the final solution. While worker agents extract relevant information in a long-context source, the manager agent synthesizes relevant information accumulated by the end of ‘’worker–agent chain'' to generate the final answer. Specifically, given the instruction for manager and query, the manager agent assesses the accumulated knowledge from the last worker to generate the final answer.
High-level illustration of Chain-of-Agents. It consists of multiple worker agents that sequentially communicate to handle different segmented portions of the text, followed by a manager agent that synthesizes these contributions into a coherent final output.
Experiments
To illustrate the utility of this approach, we conduct intensive experiments on nine datasets, including question answering, summarization, and code completion tasks with six LLMs, PaLM 2 (Text Bison and Text Unicorn), Gemini (Ultra), and Claude 3 (Haiku, Sonnet, and Opus) models. We compare CoA with two strong baselines chosen from input reduction and window extension approaches, respectively: (i) RAG, which uses a state-of-the-art retriever to obtain the most relevant information to feed into the LLM, and (ii) Full-Context, which feeds all input into the LLM until reaching the window limit.
Comparison with a RAG model
The figures show the results on question answering, summarization, and code completion tasks for three models on eight different datasets, including HotpotQA, MuSiQue, RepoBench-P(RepoB) from LongBench, and NarrativeQA (NQA), Qasper, QuALITY, QMSum, GovReport from SCROLLS. CoA (8k) (where “8k” refers to the length of input for the LLM) outperforms Full-Context (8k) by a large margin on all datasets. It also outperforms the RAG (8k) model for all eight datasets.
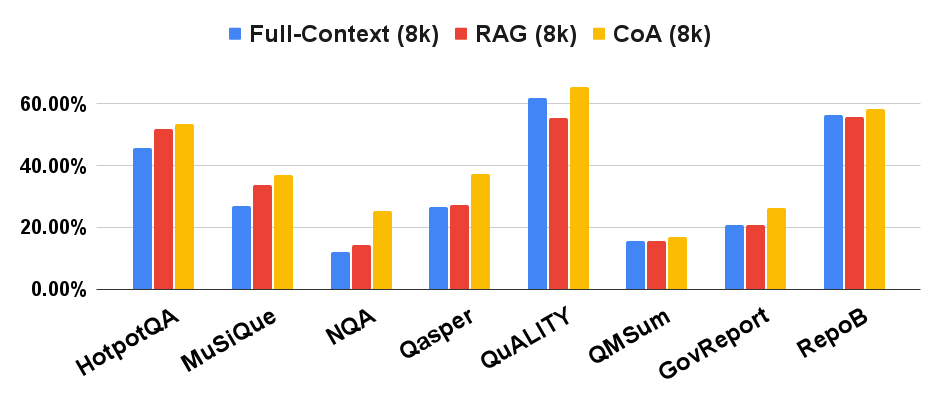
Palm 2 Text Bison
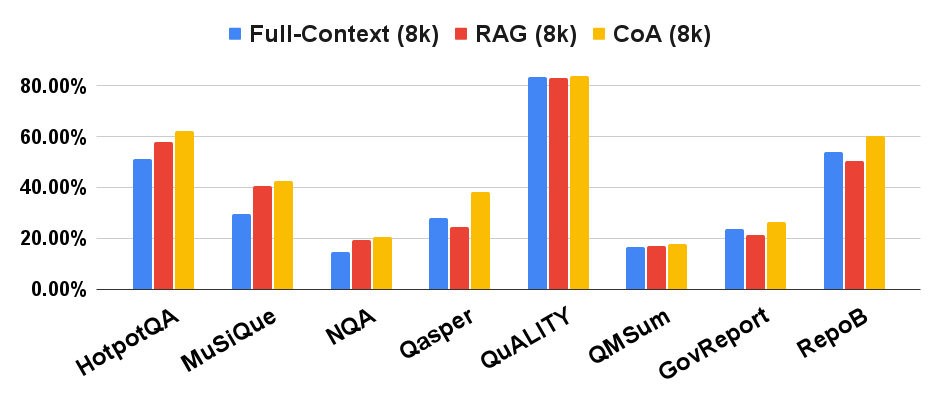
Palm 2 Text Unicorn
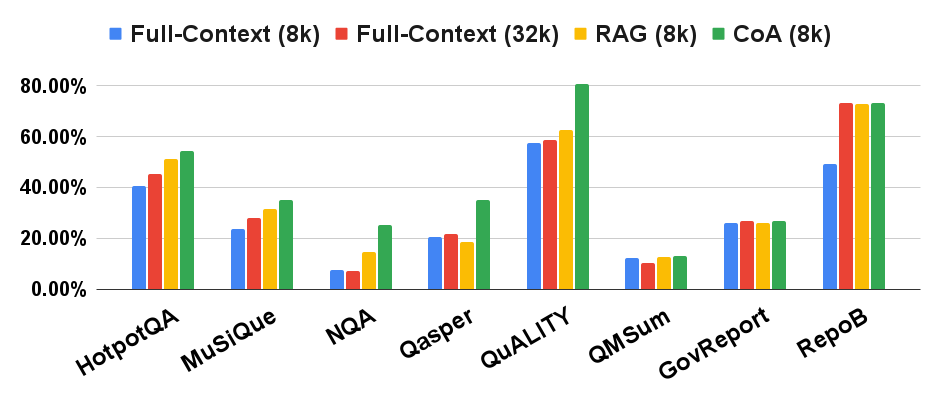
Gemini Ultra
Comparison of three LLMs with RAG and Full-Context baselines. Y-axis is the performance metric on each dataset.
Multi-agent collaboration in CoA enables complex reasoning over long context
Below we present a comparison of outputs from RAG and CoA for a question on the HotpotQA dataset. To find the correct answer, RAG retrieves text chunks with high semantic similarity with the query. However, conducting multi-hop reasoning is challenging as the critical first-hop answer often lacks semantic relevance to the query. In contrast, CoA operates differently: the first agent explores related topics without knowing the query’s answer, aiding subsequent inference. The second agent, also unaware of the answer, broadens the topic scope by incorporating new information. The third agent finally discovers the answer, synthesizing information from earlier agents and new data to complete the reasoning chain. This collaborative approach highlights CoA’s ability to facilitate complex reasoning across long context tasks.

A case study of RAG (left) and CoA (right) on HotpotQA. Sequential agent communication enables CoA to perform complex multi-hop reasoning over long contexts.
Comparison with long context LLMs
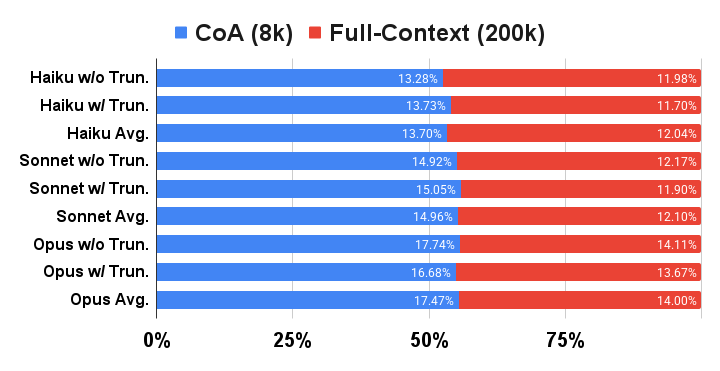
The figure below shows the comparison with long context LLMs on NarrativeQA and BookSum. CoA (8k) significantly outperforms RAG (8k) and Full-Context (200k) baselines with three Claude 3 (Haiku, Sonnet, and Opus) models as backbones, even though the context limit of the latter is 200k.
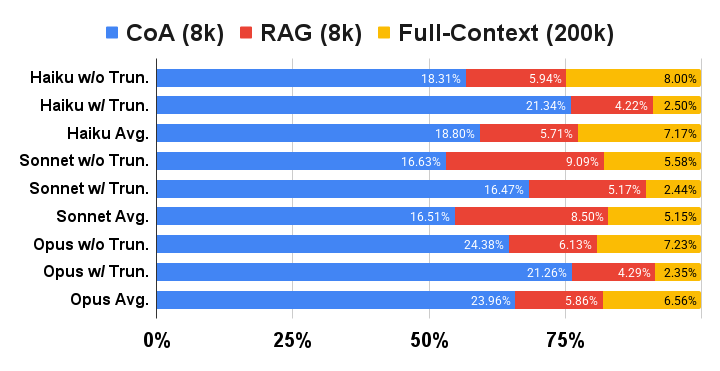
NarrativeQA
BookSum
Comparison with long context LLMs: Claude 3 Haiku, Claude 3 Sonnet and Claude 3 Opus. The number on the bar is the performance. “W” / ”w/o Trun.” indicates the source text in the sample is more/less than 200k tokens, which needs/does not need truncation for the full-context (200k) baseline. “Avg.” is the mean value across all samples.
Greater improvement for long context models with longer inputs
We compare the performance of CoA and Full-Context with Claude 3 on BookSum. As shown in Figure, CoA can outperform the Full-Context baseline by a large margin on various source lengths. It is worth noting that, when the length of the sample increases, the performance even increases for CoA, and the improvement over Full-Context (200k) baseline becomes more significant. The improvement of CoA reaches around 100% when the length is larger than 400k. Thus, we can conclude that 1) CoA can still enhance the LLM performance even though the model has a very long context window limit; and 2) CoA delivers more performance gains when the input is longer.

Conclusion
In this paper, we propose Chain-of-Agents (CoA), a multi-agent LLM collaboration framework for solving long context tasks. It is a training-free, task- and length-agnostic, interpretable, and cost-effective framework. Experiments show that Chain-of-Agents outperforms RAG and long context LLMs by a large margin, despite its simple design. Analysis shows that by integrating information aggregation and context reasoning, CoA performs better on longer samples.
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence






