Building Efficient Multiple Visual Domain Models with Multi-path Neural Architecture Search
August 3, 2022
Posted by Qifei Wang, Senior Software Engineer, and Feng Yang, Senior Staff Software Engineer, Google Research
Quick links
Deep learning models for visual tasks (e.g., image classification) are usually trained end-to-end with data from a single visual domain (e.g., natural images or computer generated images). Typically, an application that completes visual tasks for multiple domains would need to build multiple models for each individual domain, train them independently (meaning no data is shared between domains), and then at inference time each model would process domain-specific input data. However, early layers between these models generate similar features, even for different domains, so it can be more efficient — decreasing latency and power consumption, lower memory overhead to store parameters of each model — to jointly train multiple domains, an approach referred to as multi-domain learning (MDL). Moreover, an MDL model can also outperform single domain models due to positive knowledge transfer, which is when additional training on one domain actually improves performance for another. The opposite, negative knowledge transfer, can also occur, depending on the approach and specific combination of domains involved. While previous work on MDL has proven the effectiveness of jointly learning tasks across multiple domains, it involved a hand-crafted model architecture that is inefficient to apply to other work.
In “Multi-path Neural Networks for On-device Multi-domain Visual Classification”, we propose a general MDL model that can: 1) achieve high accuracy efficiently (keeping the number of parameters and FLOPS low), 2) learn to enhance positive knowledge transfer while mitigating negative transfer, and 3) effectively optimize the joint model while handling various domain-specific difficulties. As such, we propose a multi-path neural architecture search (MPNAS) approach to build a unified model with heterogeneous network architecture for multiple domains. MPNAS extends the efficient neural architecture search (NAS) approach from single path search to multi-path search by finding an optimal path for each domain jointly. Also, we introduce a new loss function, called adaptive balanced domain prioritization (ABDP) that adapts to domain-specific difficulties to help train the model efficiently. The resulting MPNAS approach is efficient and scalable; the resulting model maintains performance while reducing the model size and FLOPS by 78% and 32%, respectively, compared to a single-domain approach.
Multi-path Neural Architecture Search
To encourage positive knowledge transfer and avoid negative transfer, traditional solutions build an MDL model so that domains share most of the layers that learn the shared features across domains (called feature extraction), then have a few domain-specific layers on top. However, such a homogenous approach to feature extraction cannot handle domains with significantly different features (e.g., objects in natural images and art paintings). On the other hand, handcrafting a unified heterogeneous architecture for each MDL model is time-consuming and requires domain-specific knowledge.
NAS is a powerful paradigm for automatically designing deep learning architectures. It defines a search space, made up of various potential building blocks that could be part of the final model. The search algorithm finds the best candidate architecture from the search space that optimizes the model objectives, e.g., classification accuracy. Recent NAS approaches (e.g., TuNAS) have meaningfully improved search efficiency by using end-to-end path sampling, which enables us to scale NAS from single domains to MDL.
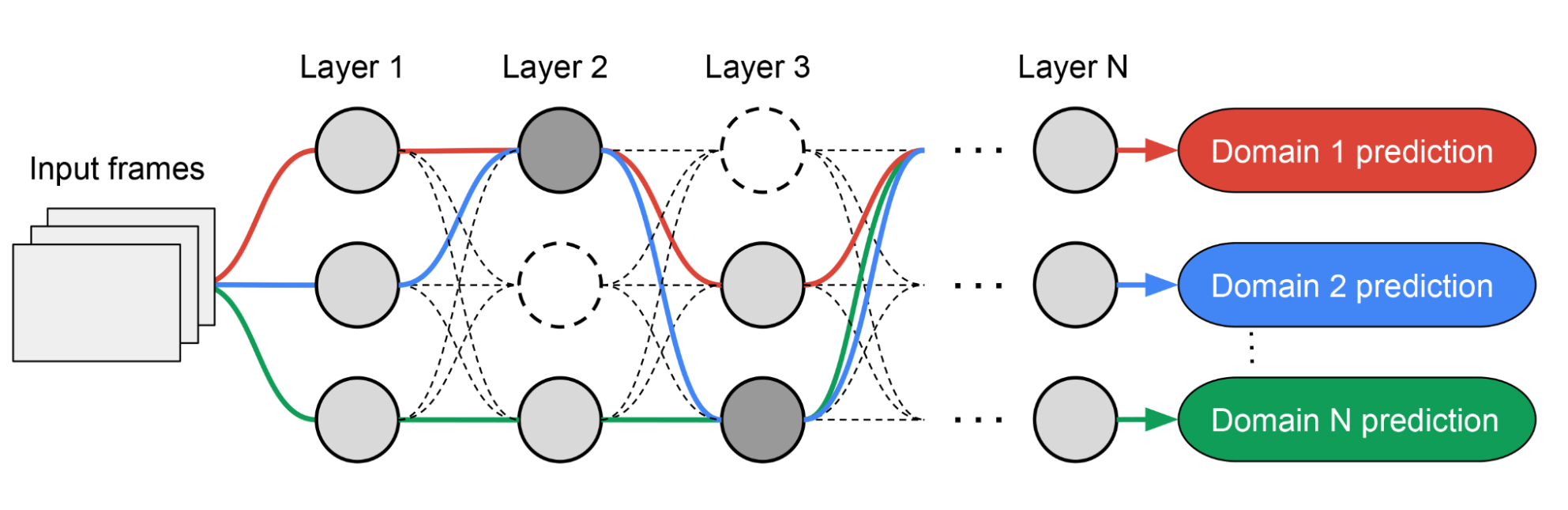
Inspired by TuNAS, MPNAS builds the MDL model architecture in two stages: search and training. In the search stage, to find an optimal path for each domain jointly, MPNAS creates an individual reinforcement learning (RL) controller for each domain, which samples an end-to-end path (from input layer to output layer) from the supernetwork (i.e., the superset of all the possible subnetworks between the candidate nodes defined by the search space). Over multiple iterations, all the RL controllers update the path to optimize the RL rewards across all domains. At the end of the search stage, we obtain a subnetwork for each domain. Finally, all the subnetworks are combined to build a heterogeneous architecture for the MDL model, shown below.
Since the subnetwork for each domain is searched independently, the building block in each layer can be shared by multiple domains (i.e., dark gray nodes), used by a single domain (i.e., light gray nodes), or not used by any subnetwork (i.e., dotted nodes). The path for each domain can also skip any layer during search. Given the subnetwork can freely select which blocks to use along the path in a way that optimizes performance (rather than, e.g., arbitrarily designating which layers are homogenous and which are domain-specific), the output network is both heterogeneous and efficient.
 |
| Example architecture searched by MPNAS. Dashed paths represent all the possible subnetworks. Solid paths represent the selected subnetworks for each domain (highlighted in different colors). Nodes in each layer represent the candidate building blocks defined by the search space. |
The figure below demonstrates the searched architecture of two visual domains among the ten domains of the Visual Domain Decathlon challenge. One can see that the subnetwork of these two highly related domains (one red, the other green) share a majority of building blocks from their overlapping paths, but there are still some differences.
 |
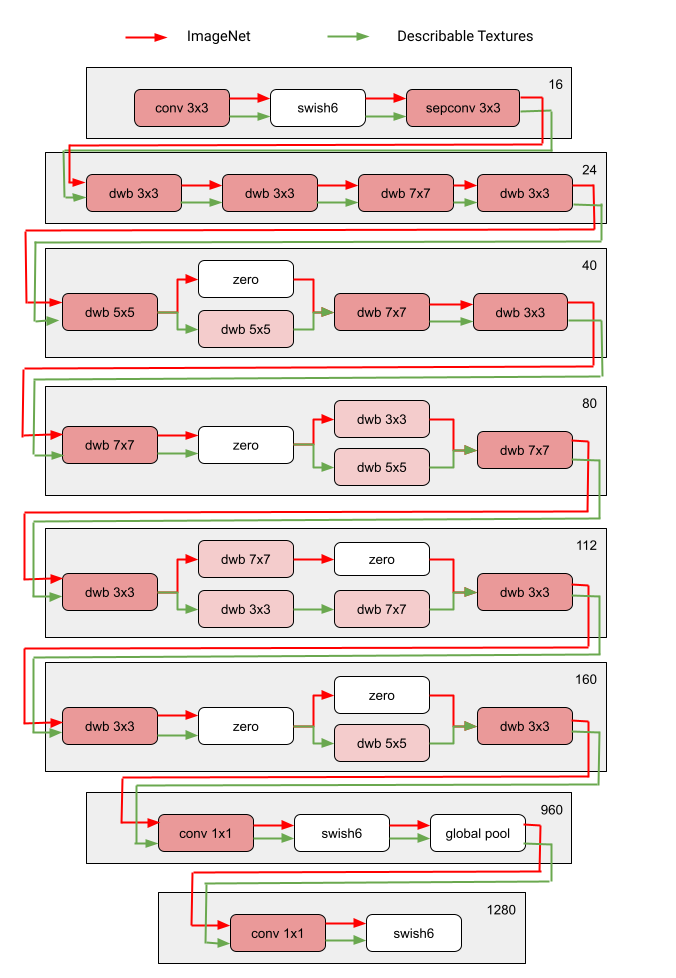
| Architecture blocks of two domains (ImageNet and Describable Textures) among the ten domains of the Visual Domain Decathlon challenge. Red and green path represents the subnetwork of ImageNet and Describable Textures, respectively. Dark pink nodes represent the blocks shared by multiple domains. Light pink nodes represent the blocks used by each path. The model is built based on MobileNet V3-like search space. The “dwb” block in the figure represents the dwbottleneck block. The “zero” block in the figure indicates the subnetwork skips that block. |
Below we show the path similarity between domains among the ten domains of the Visual Domain Decathlon challenge. The similarity is measured by the Jaccard similarity score between the subnetworks of each domain, where higher means the paths are more similar. As one might expect, domains that are more similar share more nodes in the paths generated by MPNAS, which is also a signal of strong positive knowledge transfer. For example, the paths for similar domains (like ImageNet, CIFAR-100, and VGG Flower, which all include objects in natural images) have high scores, while the paths for dissimilar domains (like Daimler Pedestrian Classification and UCF101 Dynamic Images, which include pedestrians in grayscale images and human activity in natural color images, respectively) have low scores.
 |
| Confusion matrix for the Jaccard similarity score between the paths for the ten domains. Score value ranges from 0 to 1. A greater value indicates two paths share more nodes. |
Training a Heterogeneous Multi-domain Model
In the second stage, the model resulting from MPNAS is trained from scratch for all domains. For this to work, it is necessary to define a unified objective function for all the domains. To successfully handle a large variety of domains, we designed an algorithm that adapts throughout the learning process such that losses are balanced across domains, called adaptive balanced domain prioritization (ABDP).
Below we show the accuracy, model size, and FLOPS of the model trained in different settings. We compare MPNAS to three other approaches:
- Domain independent NAS: Searching and training a model for each domain separately.
- Single path multi-head: Using a pre-trained model as a shared backbone for all domains with separated classification heads for each domain.
- Multi-head NAS: Searching a unified backbone architecture for all domains with separated classification heads for each domain.
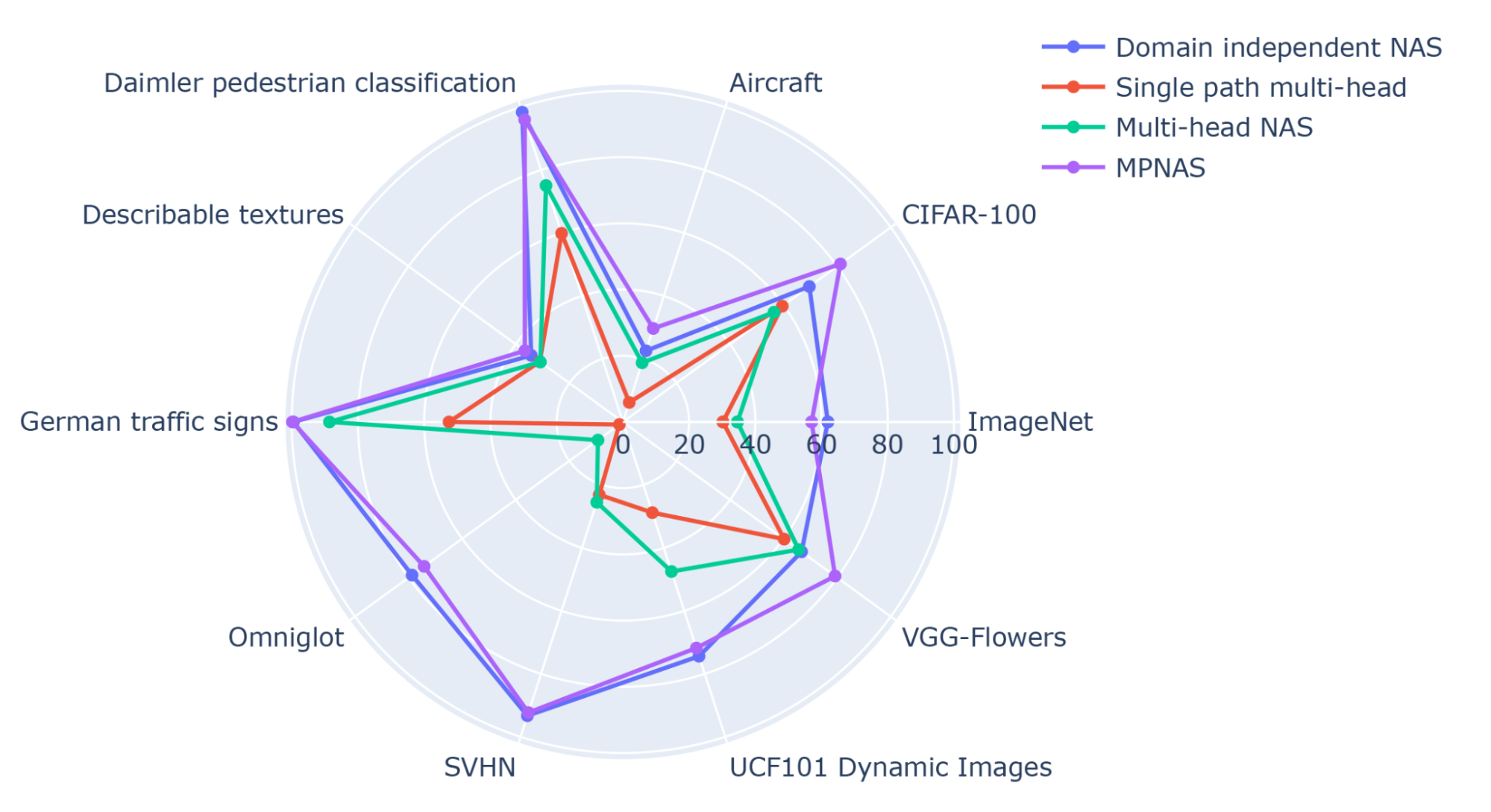
From the results, we can observe that domain independent NAS requires building a bundle of models for each domain, resulting in a large model size. Although single path multi-head and multi-head NAS can reduce the model size and FLOPS significantly, forcing the domains to share the same backbone introduces negative knowledge transfer, decreasing overall accuracy.
| Model | Number of parameters ratio | GFLOPS | Average Top-1 accuracy |
| Domain independent NAS | 5.7x | 1.08 | 69.9 |
| Single path multi-head | 1.0x | 0.09 | 35.2 |
| Multi-head NAS | 0.7x | 0.04 | 45.2 |
| MPNAS | 1.3x | 0.73 | 71.8 |
| Number of parameters, gigaFLOPS, and Top-1 accuracy (%) of MDL models on the Visual Decathlon dataset. All methods are built based on the MobileNetV3-like search space. |
MPNAS can build a small and efficient model while still maintaining high overall accuracy. The average accuracy of MPNAS is even 1.9% higher than the domain independent NAS approach since the model enables positive knowledge transfer. The figure below compares per domain top-1 accuracy of these approaches.
 |
| Top-1 accuracy of each Visual Decathlon domain. |
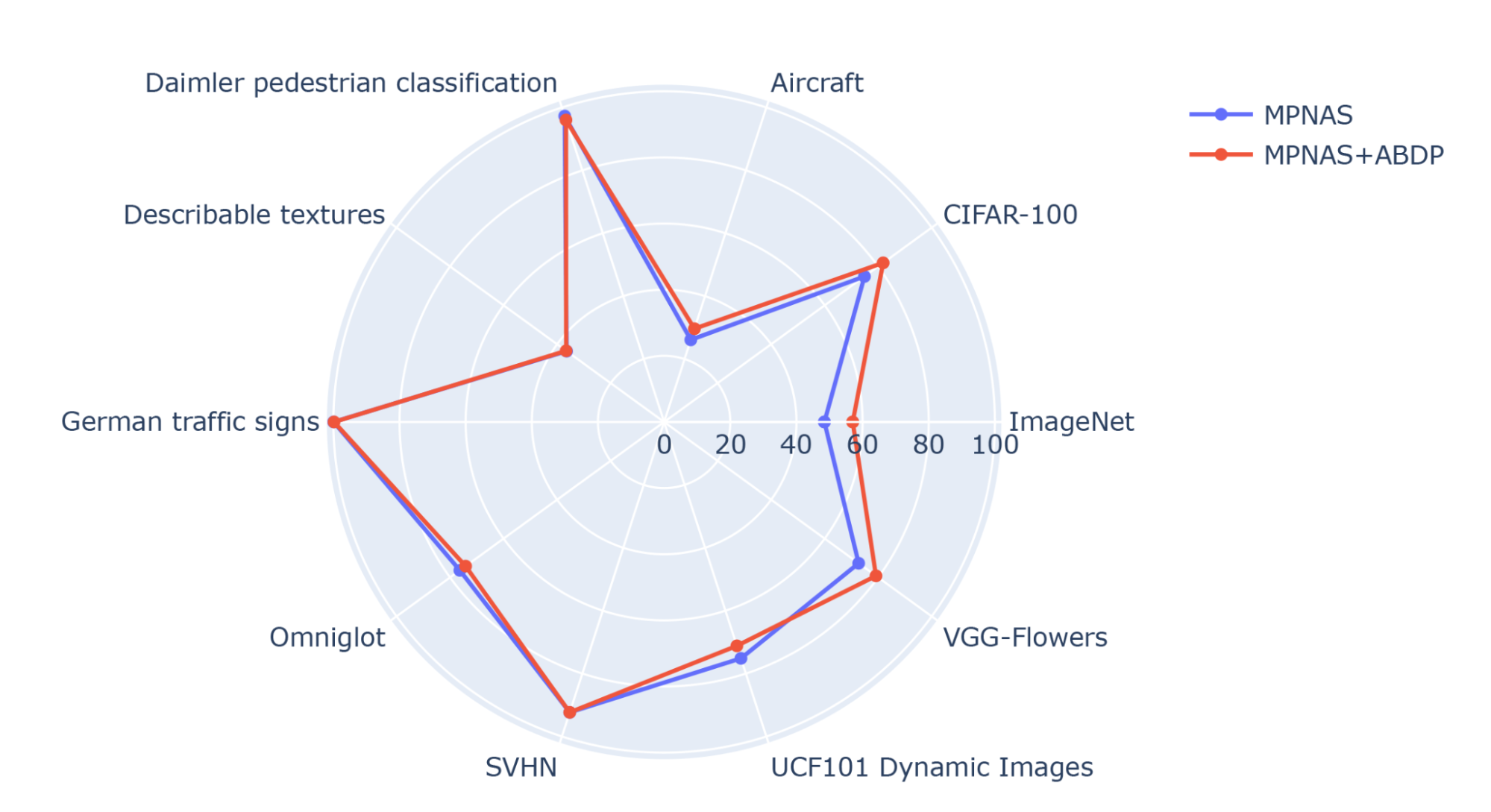
Our evaluation shows that top-1 accuracy is improved from 69.96% to 71.78% (delta: +1.81%) by using ABDP as part of the search and training stages.
 |
| Top-1 accuracy for each Visual Decathlon domain trained by MPNAS with and without ABDP. |
Future Work
We find MPNAS is an efficient solution to build a heterogeneous network to address the data imbalance, domain diversity, negative transfer, domain scalability, and large search space of possible parameter sharing strategies in MDL. By using a MobileNet-like search space, the resulting model is also mobile friendly. We are continuing to extend MPNAS for multi-task learning for tasks that are not compatible with existing search algorithms and hope others might use MPNAS to build a unified multi-domain model.
Acknowledgements
This work is made possible through a collaboration spanning several teams across Google. We’d like to acknowledge contributions from Junjie Ke, Joshua Greaves, Grace Chu, Ramin Mehran, Gabriel Bender, Xuhui Jia, Brendan Jou, Yukun Zhu, Luciano Sbaiz, Alec Go, Andrew Howard, Jeff Gilbert, Peyman Milanfar, and Ming-Hsuan Yang.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence