Beyond billion-parameter burdens: Unlocking data synthesis with a conditional generator
August 14, 2025
Shanshan Wu, Software Engineer, Google Research
We present a novel privacy-preserving synthetic data generation algorithm that enables automatic topic-wise distribution matching, making it accessible even for resource-constrained AI applications.
Quick links
Generating large-scale differentially private (DP) synthetic data is challenging due to the fundamental privacy–computation–utility trade-off, where strong privacy guarantees can either hurt the quality of the synthetic data, or require large amounts of computation. A popular solution is to privately fine-tune a billion-size large language model (LLM) on the “private data” (a standard term referring to the dataset on which one plans to offer privacy guarantees) and then sample from the fine-tuned model to generate synthetic data. This approach is computationally expensive and hence unattainable for resource-constrained applications. So, recently proposed Aug-PE and Pre-Text algorithms have explored generating synthetic data that only requires LLM API access. However, they usually depend heavily on manual prompts to generate the initial dataset and are ineffective in using private information in their iterative data selection process.
In “Synthesizing Privacy-Preserving Text Data via Fine-Tuning Without Fine-Tuning Billion-Scale LLMs”, presented at ICML 2025, we propose CTCL (Data Synthesis with ConTrollability and CLustering), a novel framework for generating privacy-preserving synthetic data without fine-tuning billion-scale LLMs or domain-specific prompt engineering. CTCL uses a lightweight 140 million parameter model, making it practical for resource-constrained applications. By conditioning on the topic information, the generated synthetic data can match the distribution of topics from the private domain. Finally, unlike the Aug-PE algorithm, CTCL allows generating unlimited synthetic data samples without paying additional privacy costs. We evaluated CTCL across diverse datasets, demonstrating that it consistently outperforms baselines, particularly under strong privacy guarantees. Ablation studies confirmed the crucial impact of its pre-training and keyword-based conditioning, while experiments also showed CTCL's improved scalability compared to the Aug-PE algorithm.
Creating the data synthesis framework
The CTCL Framework is designed to generate high-quality synthetic data from private datasets while preserving privacy. It achieves this by breaking down the process into three main steps. Before we dive into the details, it's essential to understand the two core components that make this framework work: CTCL-Topic and CTCL-Generator. CTCL-Topic is a universal topic model that captures the high-level themes of a dataset, while CTCL-Generator is a powerful language model that can create documents based on specific keywords. These two components, developed using large public corpora, are the foundation for learning different private domains and generating synthetic data from them.
Step 1: Developing CTCL-Topic and CTCL-Generator
Both components are developed only once using large-scale public corpora and can then be used later for learning different private domains. CTCL-Topic is a topic model extracted from Wikipedia, a diverse corpus containing around 6 million documents. We follow BERTopic to embed each document, cluster them into around 1K clusters (i.e., 1K topics), and represent each cluster by 10 keywords.
CTCL-Generator is a lightweight (140M-parameter) conditional language model that accepts free-form document descriptions as inputs (e.g., document type, keywords, etc.) and generates documents satisfying the input conditions. To construct the pre-training data, for each document in SlimPajama, we prompt Gemma-2-2B to “Describe the document in multiple aspects.” The result is a dataset comprising 430M description–document pairs. We then use this dataset to perform continual pre-training on top of BART-base (a 140M-parameter language model), yielding the CTCL-Generator.
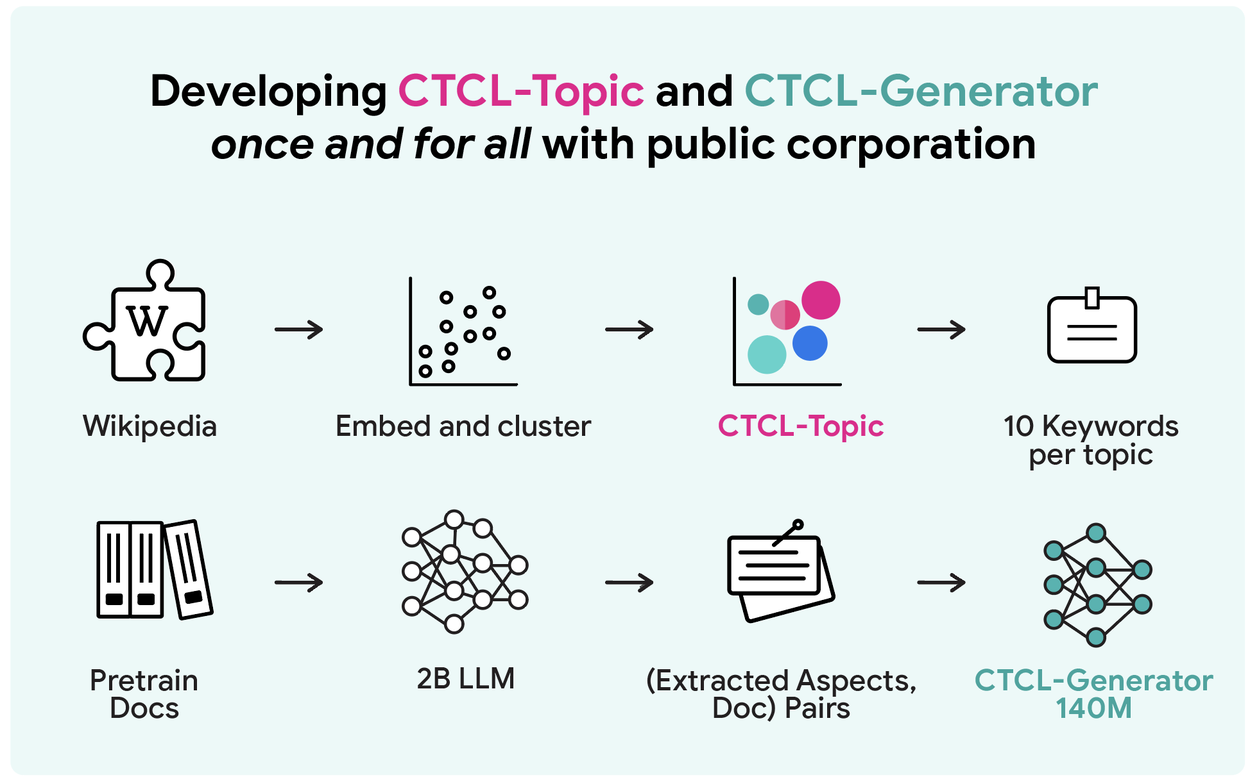
Step 1: A universal topic model CTCL-Topic and a lightweight 140M-parameter CTCL-Generator with strong controllability are developed using large-scale public corpora.
Step 2: Learning the private domain
We then use CTCL-Topic to capture the high-level distributional information from the entire private corpus. This is done by collecting a private histogram representing the topic-wise distribution of the private data, i.e., the percentage of each topic in the private data. This topic histogram will be used later in Step 3 for sampling.
While collecting the topic histogram, each document in the private dataset has been associated with a topic. We then transform the private dataset into a dataset of keywords and document pairs, the 10 keywords for each document are obtained from their corresponding topic in CTCL-Topic. We then fine-tune the CTCL-Generator with DP on this dataset.

Step 2: To learn the private domain, we collect a DP topic histogram from the private data, and fine-tune the CTCL-Generator with DP on the private data.
Step 3: Generating synthetic data
The DP fine-tuned CTCL-Generator is sampled proportionally for each topic according to the DP topic histogram. Specifically, given the desired size of the synthetic dataset (say, N) and the DP topic histogram (say, x% for Topic 1, y% for Topic 2, etc.), we know the number of target samples for each topic (i.e., x%*N for Topic 1, y%*N for Topic 2, etc.). For each topic, we use the corresponding 10 keywords as input to the DP fine-tuned CTCL-Generator to generate data. An arbitrary amount of synthetic data can be generated by CTCL-Generator without paying additional privacy costs, following the post-processing property of DP.
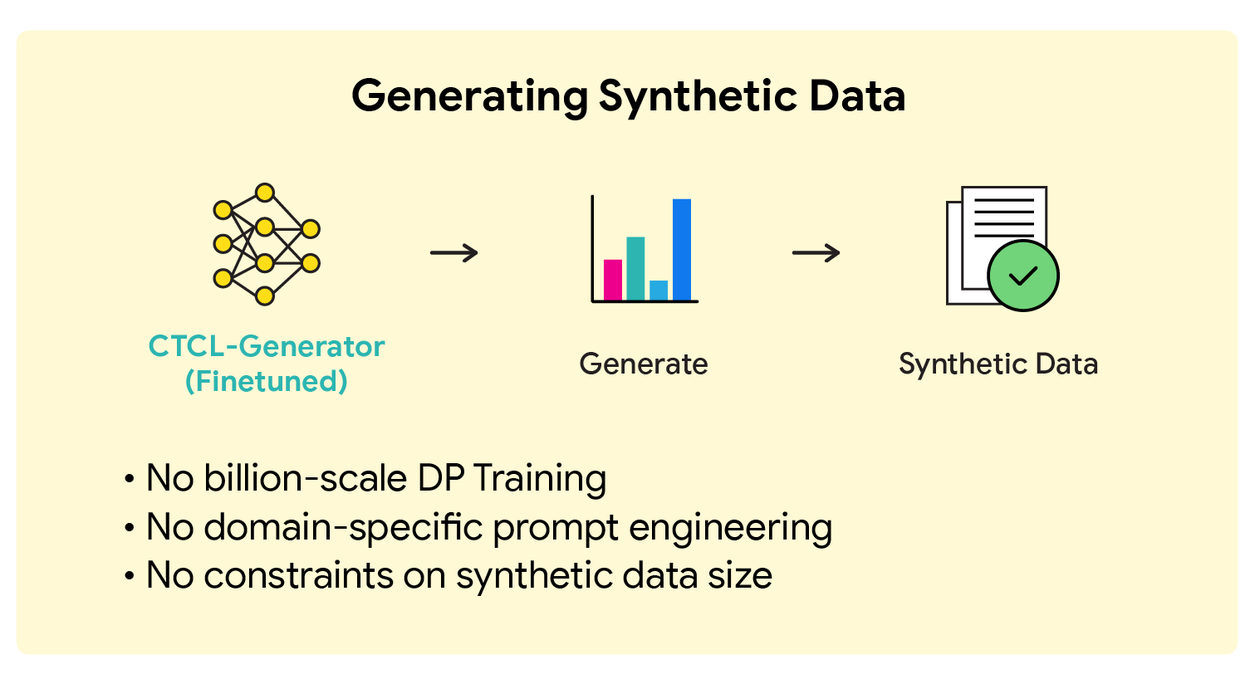
Step 3: Privacy-preserving synthetic data is generated based on the DP topic histogram and the DP fine-tuned CTCL-Generator.
Experiments
We conducted experiments on four datasets, where three datasets correspond with downstream generative tasks and one dataset with a classification task. Generative tasks are typically more challenging than classification tasks. This is because the generative tasks are evaluated by the next-token prediction accuracy, which requires the synthetic data to preserve fine-grained textual information from the private data. In contrast, the classification tasks only require maintaining the co-occurrence patterns between labels and words in the private data.
The three generative tasks are chosen to cover a diverse set of practical scenarios: PubMed (medical paper abstracts), Chatbot Arena (human-to-machine interactions), and Multi-Session Chat (human-to-human daily dialogues). To evaluate the quality of the generated synthetic data, we followed the setup of Aug-PE to train a small downstream language model on the synthetic data and then compute the next-token prediction accuracy on the real test data.
The classification task is performed on the OpenReview (academic paper reviews) dataset. To evaluate the quality of the generated synthetic data, we train a downstream classifier on the synthetic data, and compute the classification accuracy on the real test data.
To mitigate concerns regarding data contamination, we carefully analyzed our selected datasets. Our analysis showed no overlap between our pre-training data and the downstream datasets.
Results
CTCL consistently outperforms the other baselines, especially in the strong privacy guarantee regime. The plot below compares CTCL and the following baseline algorithms: Downstream DPFT (i.e., directly DP fine-tuning downstream model on the private data without using synthetic data), Aug-PE (an augmented version of the Private Evolution algorithm), DP fine-tuning an LLM of similar size to CTCL to generate synthetic data, with post-generation resampling. The plot below illustrates CTCL's improved performance, particularly for the more challenging setting that satisfies a stronger privacy guarantee (i.e., smaller ε value). This demonstrates CTCL’s strong ability to effectively capture useful information from the private data while maintaining privacy.

CTCL demonstrates improved performance over other baselines across the four datasets, especially in the challenging regime with stronger privacy guarantees (as shown by smaller ε).
Also, compared to Aug-PE, CTCL has better scalability in terms of both the privacy budget and synthetic data size. As shown by the left plot below, CTCL improves with an increased privacy budget while Aug-PE does not. This limitation may stem from Aug-PE’s constrained capacity (i.e., only via the nearest neighbors) to effectively capture information in the private data. The right plot shows that accuracy increases as the downstream model is given access to more CTCL-generated samples, while the performance of Aug-PE saturates around 10K examples. These results align with the intuition that fine-tuning–based methods (e.g., CTCL) can better capture fine-grained statistics than prompting-based methods (e.g., Aug-PE).
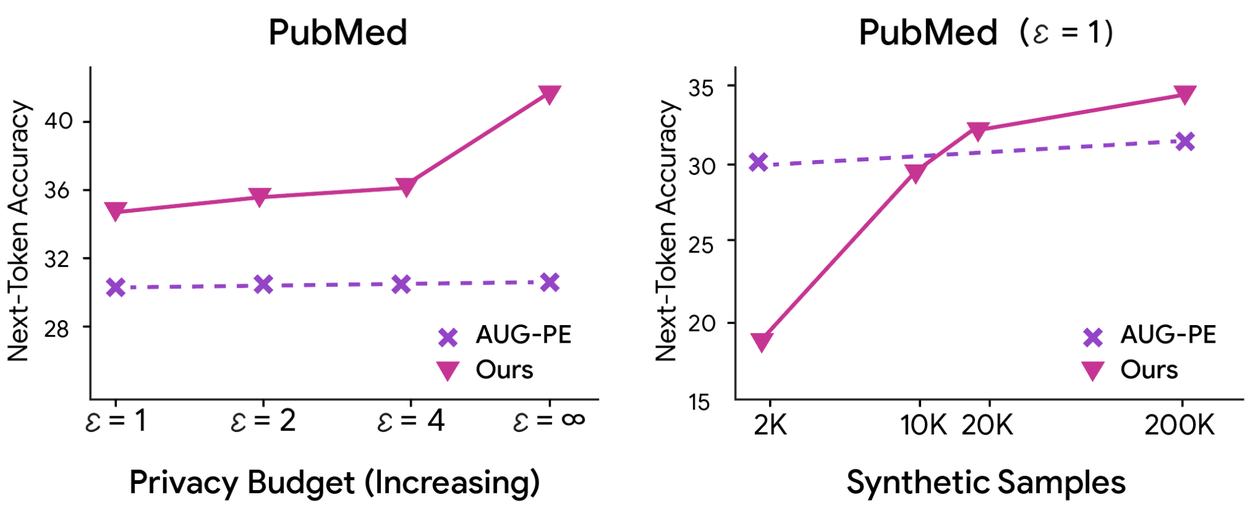
CTCL has better scalability than Aug-PE in terms of privacy budget (left) and continues to improve as the downstream tasks are trained on more synthetic data (right).
And finally, ablation studies validate the importance of two key components in our framework: 1) pre-training the CTCL-Generator on public corpus, and 2) incorporating keyword-based conditions during DP fine-tuning. Specifically, starting from the standard DP fine-tuning, we sequentially introduce these components and measure the downstream model’s test loss. For a fixed privacy budget, our results show that incorporating keywords during DP fine-tuning reduces the test loss by 50%, and adding pre-training gives another 50% reduction. This demonstrates that both components are crucial in our framework design.
Future Work
Our experiments synthesizing data with ConTrollability and CLustering (CTCL) uses a generator of only 140M parameters. But the key idea of CTCL, i.e., using clustering information or LLM extracted metadata as input instructions, can be easily extended to larger size models. We are actively working on exploring this idea to help improve real-world applications.
Acknowledgements
This work was primarily done by Bowen Tan during his internship at Google Research, under the guidance of Shanshan Wu and Zheng Xu. We thank Daniel Ramage and Brendan McMahan for leadership support, external academic partners Eric Xing and Zhiting Hu for helpful feedback on the ICML paper, Zachary Garrett and Michael Riley for reviewing an early draft, Taylor Montgomery for reviewing the dataset usage, Mark Simborg and Kimberly Schwede for help editing the blogpost and graphics. We are grateful to the ICML reviewers for their valuable time and insightful comments on our paper.
Quick links
Other posts of interest
-

June 5, 2026
Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG- Data Management ·
- Machine Intelligence ·
- Natural Language Processing ·
- Product
-

June 3, 2026
The next chapter in flood resilience: Open sourcing Google’s hydrology framework- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

May 28, 2026
A New Era of Discovery: Google Research at I/O 2026- General Science ·
- Generative AI ·
- Global ·
- Quantum




