Better table search through Machine Learning and Knowledge
August 23, 2012
Posted By Johnny Chen, Product Manager, Google Research
Quick links
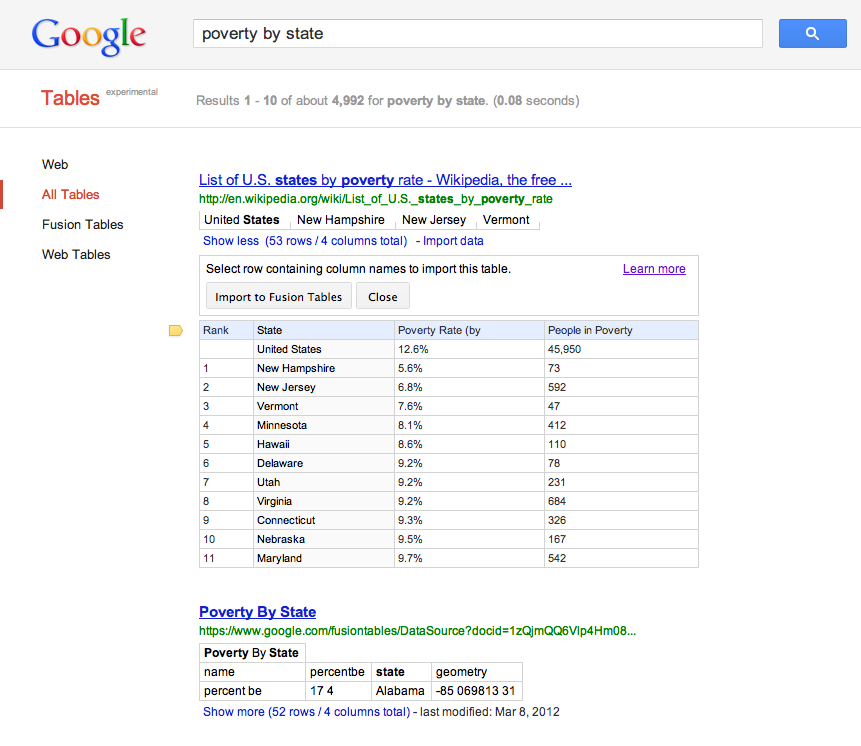
The Web offers a trove of structured data in the form of tables. Organizing this collection of information and helping users find the most useful tables is a key mission of Table Search from Google Research. While we are still a long way away from the perfect table search, we made a few steps forward recently by revamping how we determine which tables are "good" (one that contains meaningful structured data) and which ones are "bad" (for example, a table that hold the layout of a Web page). In particular, we switched from a rule-based system to a machine learning classifier that can tease out subtleties from the table features and enables rapid quality improvement iterations. This new classifier is a support vector machine (SVM) that makes use of multiple kernel functions which are automatically combined and optimized using training examples. Several of these kernel combining techniques were in fact studied and developed within Google Research [1,2].
We are also able to achieve a better understanding of the tables by leveraging the Knowledge Graph. In particular, we improved our algorithms for identifying the context and topics of each table, the entities represented in the table and the properties they have. This knowledge not only helps our classifier make a better decision on the quality of the table, but also enables better matching of the table to the user query.
Finally, you will notice that we added an easy way for our users to import Web tables found through Table Search into their Google Drive account as Fusion Tables. Now that we can better identify good tables, the import feature enables our users to further explore the data. Once in Fusion Tables, the data can be visualized, updated, and accessed programmatically using the Fusion Tables API.
These enhancements are just the start. We are continually updating the quality of our Table Search and adding features to it.
Stay tuned for more from Boulos Harb, Afshin Rostamizadeh, Fei Wu, Cong Yu and the rest of the Structured Data Team.
[1] Algorithms for Learning Kernels Based on Centered Alignment
[2] Generalization Bounds for Learning Kernels
-
Labels:
- Data Management
Quick links
Other posts of interest
-

February 8, 2023
Unsupervised and semi-supervised anomaly detection with data-centric ML- Data Management ·
- Machine Intelligence
-

December 21, 2022
EHR-Safe: Generating high-fidelity and privacy-preserving synthetic electronic health records- Data Management ·
- Health & Bioscience ·
- Machine Intelligence ·
- Security, Privacy and Abuse Prevention
-
June 12, 2020
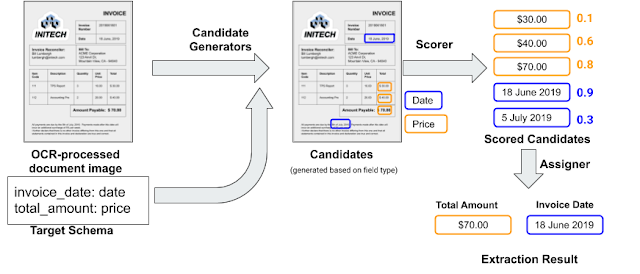
Extracting Structured Data from Templatic Documents- Conferences & Events ·
- Data Management ·
- Distributed Systems & Parallel Computing ·
- Machine Perception
×
❮
❯