Batch calibration: Rethinking calibration for in-context learning and prompt engineering
October 13, 2023
Posted by Han Zhou, Student Researcher, and Subhrajit Roy, Senior Research Scientist, Google Research
Quick links
Prompting large language models (LLMs) has become an efficient learning paradigm for adapting LLMs to a new task by conditioning on human-designed instructions. The remarkable in-context learning (ICL) ability of LLMs also leads to efficient few-shot learners that can generalize from few-shot input-label pairs. However, the predictions of LLMs are highly sensitive and even biased to the choice of templates, label spaces (such as yes/no, true/false, correct/incorrect), and demonstration examples, resulting in unexpected performance degradation and barriers for pursuing robust LLM applications. To address this problem, calibration methods have been developed to mitigate the effects of these biases while recovering LLM performance. Though multiple calibration solutions have been provided (e.g., contextual calibration and domain-context calibration), the field currently lacks a unified analysis that systematically distinguishes and explains the unique characteristics, merits, and downsides of each approach.
With this in mind, in “Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering”, we conduct a systematic analysis of the existing calibration methods, where we both provide a unified view and reveal the failure cases. Inspired by these analyses, we propose Batch Calibration (BC), a simple yet intuitive method that mitigates the bias from a batch of inputs, unifies various prior approaches, and effectively addresses the limitations in previous methods. BC is zero-shot, self-adaptive (i.e., inference-only), and incurs negligible additional costs. We validate the effectiveness of BC with PaLM 2 and CLIP models and demonstrate state-of-the-art performance over previous calibration baselines across more than 10 natural language understanding and image classification tasks.
Motivation
In pursuit of practical guidelines for ICL calibration, we started with understanding the limitations of current methods. We find that the calibration problem can be framed as an unsupervised decision boundary learning problem. We observe that uncalibrated ICL can be biased towards predicting a class, which we explicitly refer to as contextual bias, the a priori propensity of LLMs to predict certain classes over others unfairly given the context. For example, the prediction of LLMs can be biased towards predicting the most frequent label, or the label towards the end of the demonstration. We find that, while theoretically more flexible, non-linear boundaries (prototypical calibration) tend to be susceptible to overfitting and may suffer from instability for challenging multi-class tasks. Conversely, we find that linear decision boundaries can be more robust and generalizable across tasks. In addition, we find that relying on additional content-free inputs (e.g., “N/A” or random in-domain tokens) as the grounds for estimating the contextual bias is not always optimal and may even introduce additional bias, depending on the task type.
Batch calibration
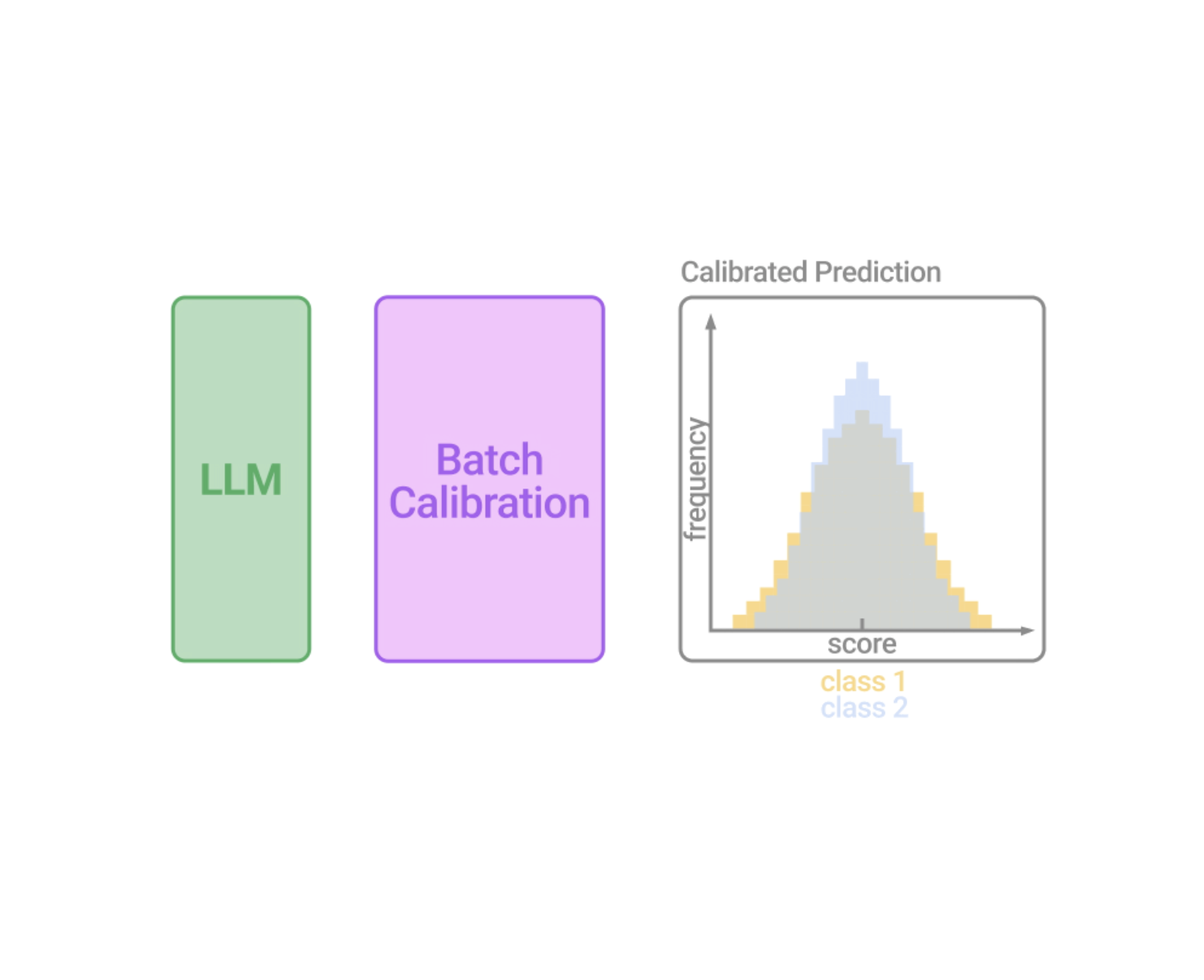
Inspired by the previous discussions, we designed BC to be a zero-shot, inference-only and generalizable calibration technique with negligible computation cost. We argue that the most critical component for calibration is to accurately estimate the contextual bias. We, therefore, opt for a linear decision boundary for its robustness, and instead of relying on content-free inputs, we propose to estimate the contextual bias for each class from a batch in a content-based manner by marginalizing the output score over all samples within the batch, which is equivalent to measuring the mean score for each class (visualized below).
We then obtain the calibrated probability by dividing the output probability over the contextual prior, which is equivalent to aligning the log-probability (LLM scores) distribution to the estimated mean of each class. It is noteworthy that because it requires no additional inputs to estimate the bias, this BC procedure is zero-shot, only involves unlabeled test samples, and incurs negligible computation costs. We may either compute the contextual bias once all test samples are seen, or alternatively, in an on-the-fly manner that dynamically processes the outputs. To do so, we may use a running estimate of the contextual bias for BC, thereby allowing BC's calibration term to be estimated from a small number of mini-batches that is subsequently stabilized when more mini-batches arrive.
 |
| Illustration of Batch Calibration (BC). Batches of demonstrations with in-context examples and test samples are passed into the LLM. Due to sources of implicit bias in the context, the score distribution from the LLM becomes biased. BC is a modular and adaptable layer option appended to the output of the LLM that generates calibrated scores (visualized for illustration only). |
Experiment design
For natural language tasks, we conduct experiments on 13 more diverse and challenging classification tasks, including the standard GLUE and SuperGLUE datasets. This is in contrast to previous works that only report on relatively simple single-sentence classification tasks.. For image classification tasks, we include SVHN, EuroSAT, and CLEVR. We conduct experiments mainly on the state-of-the-art PaLM 2 with size variants PaLM 2-S, PaLM 2-M, and PaLM 2-L. For VLMs, we report the results on CLIP ViT-B/16.
Results
Notably, BC consistently outperforms ICL, yielding a significant performance enhancement of 8% and 6% on small and large variants of PaLM 2, respectively. This shows that the BC implementation successfully mitigates the contextual bias from the in-context examples and unleashes the full potential of LLM in efficient learning and quick adaptation to new tasks. In addition, BC improves over the state-of-the-art prototypical calibration (PC) baseline by 6% on PaLM 2-S, and surpasses the competitive contextual calibration (CC) baseline by another 3% on average on PaLM 2-L. Specifically, BC is a generalizable and cheaper technique across all evaluated tasks, delivering stable performance improvement, whereas previous baselines exhibit varying degrees of performance across tasks.
 |
| Batch Calibration (BC) achieves the best performance on 1-shot ICL over calibration baselines: contextual calibration (CC), domain-context calibration (DC), and prototypical calibration (PC) on an average of 13 NLP tasks on PaLM 2 and outperforms the zero-shot CLIP on image tasks. |
We analyze the performance of BC by varying the number of ICL shots from 0 to 4, and BC again outperforms all baseline methods. We also observe an overall trend for improved performance when more shots are available, where BC demonstrates the best stability.
 |
| The ICL performance on various calibration techniques over the number of ICL shots on PaLM 2-S. We compare BC with the uncalibrated ICL, contextual calibration (CC), domain-context calibration (DC), and prototypical calibration (PC) baselines. |
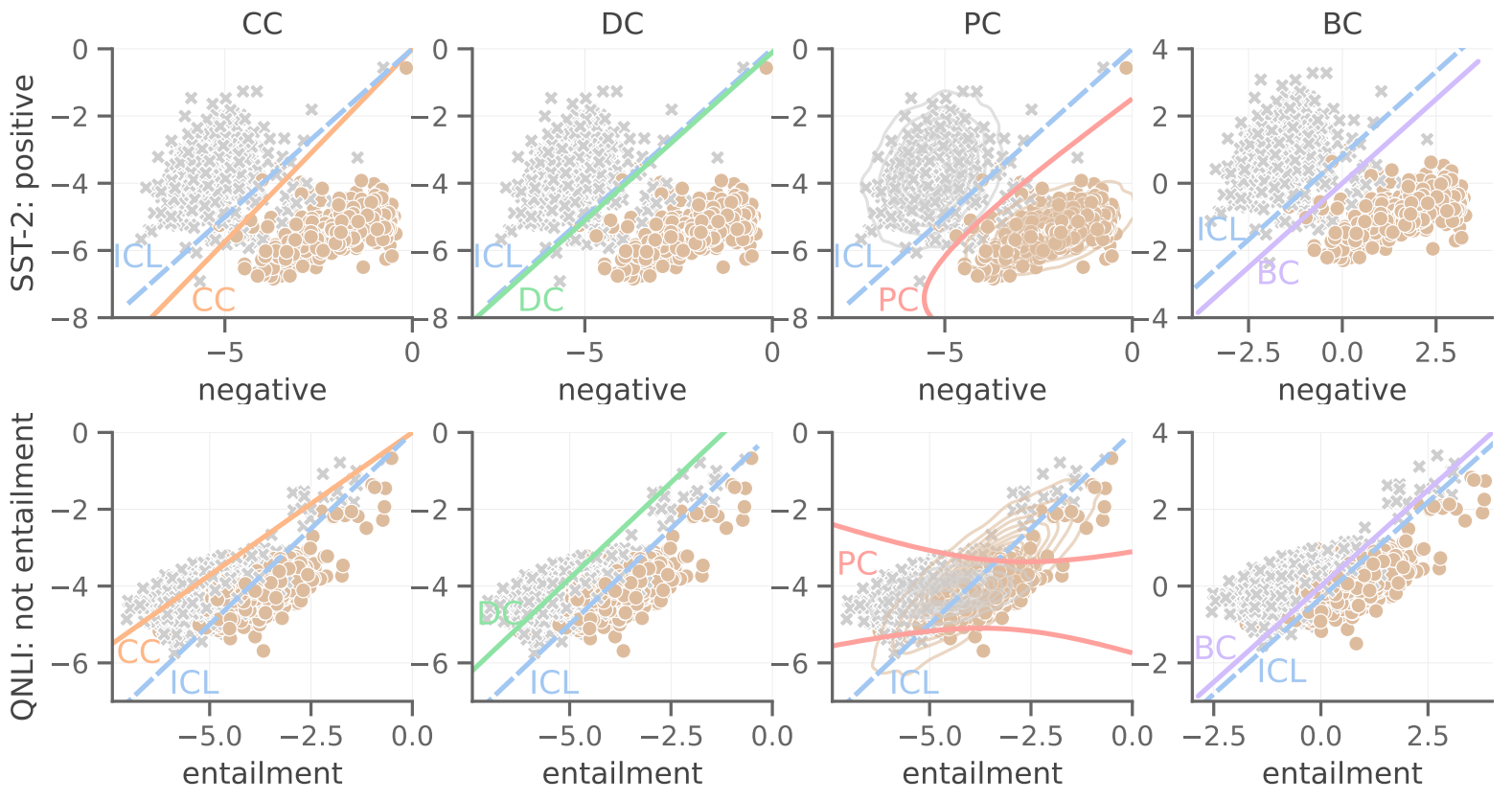
We further visualize the decision boundaries of uncalibrated ICL after applying existing calibration methods and the proposed BC. We show success and failure cases for each baseline method, whereas BC is consistently effective.
 |
| Visualization of the decision boundaries of uncalibrated ICL, and after applying existing calibration methods and the proposed BC in representative binary classification tasks of SST-2 (top row) and QNLI (bottom row) on 1-shot PaLM 2-S. Each axis indicates the LLM score on the defined label. |
Robustness and ablation studies
We analyze the robustness of BC with respect to common prompt engineering design choices that were previously shown to significantly affect LLM performance: choices and orders of in-context examples, the prompt template for ICL, and the label space. First, we find that BC is more robust to ICL choices and can mostly achieve the same performance with different ICL examples. Additionally, given a single set of ICL shots, altering the order between each ICL example has minimal impact on the BC performance. Furthermore, we analyze the robustness of BC under 10 designs of prompt templates, where BC shows consistent improvement over the ICL baseline. Therefore, though BC improves performance, a well-designed template can further enhance the performance of BC. Lastly, we examine the robustness of BC to variations in label space designs (see appendix in our paper). Remarkably, even when employing unconventional choices such as emoji pairs as labels, leading to dramatic oscillations of ICL performance, BC largely recovers performance. This observation demonstrates that BC increases the robustness of LLM predictions under common prompt design choices and makes prompt engineering easier.
 |
| Batch Calibration makes prompt engineering easier while being data-efficient. Data are visualized as a standard box plot, which illustrates values for the median, first and third quartiles, and minimum and maximum. |
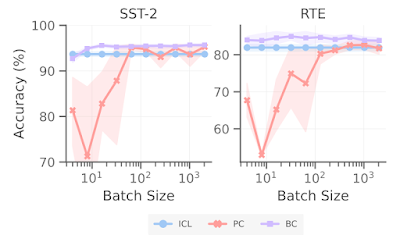
Moreover, we study the impact of batch size on the performance of BC. In contrast to PC, which also leverages an unlabeled estimate set, BC is remarkably more sample efficient, achieving a strong performance with only around 10 unlabeled samples, whereas PC requires more than 500 unlabeled samples before its performance stabilizes.
 |
| Batch Calibration makes prompt engineering easier while being insensitive to the batch size. |
Conclusion
We first revisit previous calibration methods while addressing two critical research questions from an interpretation of decision boundaries, revealing their failure cases and deficiencies. We then propose Batch Calibration, a zero-shot and inference-only calibration technique. While methodologically simple and easy to implement with negligible computation cost, we show that BC scales from a language-only setup to the vision-language context, achieving state-of-the-art performance in both modalities. BC significantly improves the robustness of LLMs with respect to prompt designs, and we expect easy prompt engineering with BC.
Acknowledgements
This work was conducted by Han Zhou, Xingchen Wan, Lev Proleev, Diana Mincu, Jilin Chen, Katherine Heller, Subhrajit Roy. We would like to thank Mohammad Havaei and other colleagues at Google Research for their discussion and feedback.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence