Axial-DeepLab: Long-Range Modeling in All Layers for Panoptic Segmentation
August 26, 2020
Posted by Huiyu Wang, Student Researcher and Yukun Zhu, Software Engineer, Google Research
Quick links
The success of convolutional neural networks (CNNs) mainly comes from two properties of convolution: translation equivariance and locality. Translation equivariance, although not exact, ensures that the model functions well for objects at different positions in an image or for images of different sizes. Locality ensures efficient computation, but at the cost of making the modeling of long-range spatial relations challenging for panoptic segmentation of large images. For example, segmenting a large object requires modeling the shape of it, which could potentially cover a very large pixel area, and context that could be helpful for segmenting the object may come from farther away. In such cases, the inability to inform the model from context far from the convolution kernel could negatively impact the performance.
A rich set of literature has discussed approaches to solving the limitation of locality and enabling long-range interactions in CNNs. Some employ atrous convolutions, or image pyramids, which expand the receptive field somewhat, but it is still limited to a small local region. Another line of work adopts self-attention mechanisms, e.g., non-local neural networks, which allow the receptive field to cover the entire input image, as opposed to local convolutions. Unfortunately, such approaches are computationally expensive, especially for large inputs. Recent works enable building fully attentional models, but at a cost of applying local constraints to non-local neural networks. These restrictions limit the model receptive field, which is harmful to tasks such as segmentation, especially on high-resolution inputs.
In our recent ECCV 2020 paper, “Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation”, we propose to adopt axial-attention (or criss-cross attention), which recovers large receptive field in fully attentional models. The core idea is to separate 2D attention into two steps that apply 1D attention in the height and width axes sequentially. The efficiency of this approach enables attention over large regions, allowing models that learn long-range, or even global, interactions. Additionally, we propose a novel formulation for self-attention modules, which is more sensitive to the position of relevant context in a large receptive field with marginal costs. We evaluate our position-sensitive axial-attention method on panoptic segmentation by applying it to Panoptic-DeepLab, a simple and efficient method for panoptic segmentation. The effectiveness of our model is demonstrated on ImageNet, COCO, and Cityscapes. Axial-DeepLab achieves state-of-the-art results on panoptic segmentation and semantic segmentation, outperforming Panoptic-DeepLab by a large margin.
Axial-Attention Architecture
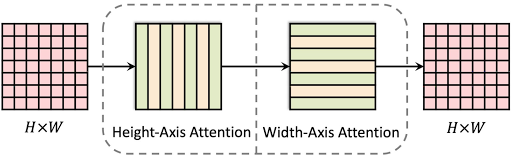
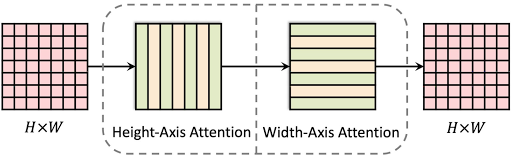
Axial-DeepLab consists of an Axial-ResNet backbone and Panoptic-DeepLab output heads, which produce panoptic segmentation results. Our Axial-ResNet is built on a ResNet architecture, in which all the 3×3 local convolutions in the ResNet bottleneck blocks are replaced by our proposed global position-sensitive axial-attention, thus enabling both a large receptive field and precise positional information.
 |
| An axial-attention block consists of two position-sensitive axial-attention layers operating along height- and width-axis sequentially. |
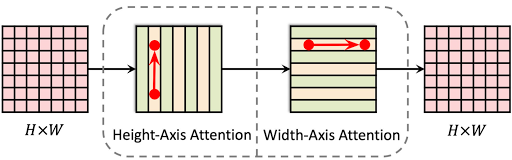
The Axial-DeepLab height axial attention layer provides 1-dimensional self-attention globally, propagating information within individual columns — it does not transfer information between columns. The second 1D attention layer operating in the horizontal direction allows one to capture both column-wise and row-wise information. This separation reduces the complexity of self-attention from quadratic (2D) to linear (1D), which enables using a much larger (65×65 vs. previously 3×3) or even global context in all layers for long-range modeling in panoptic segmentation.
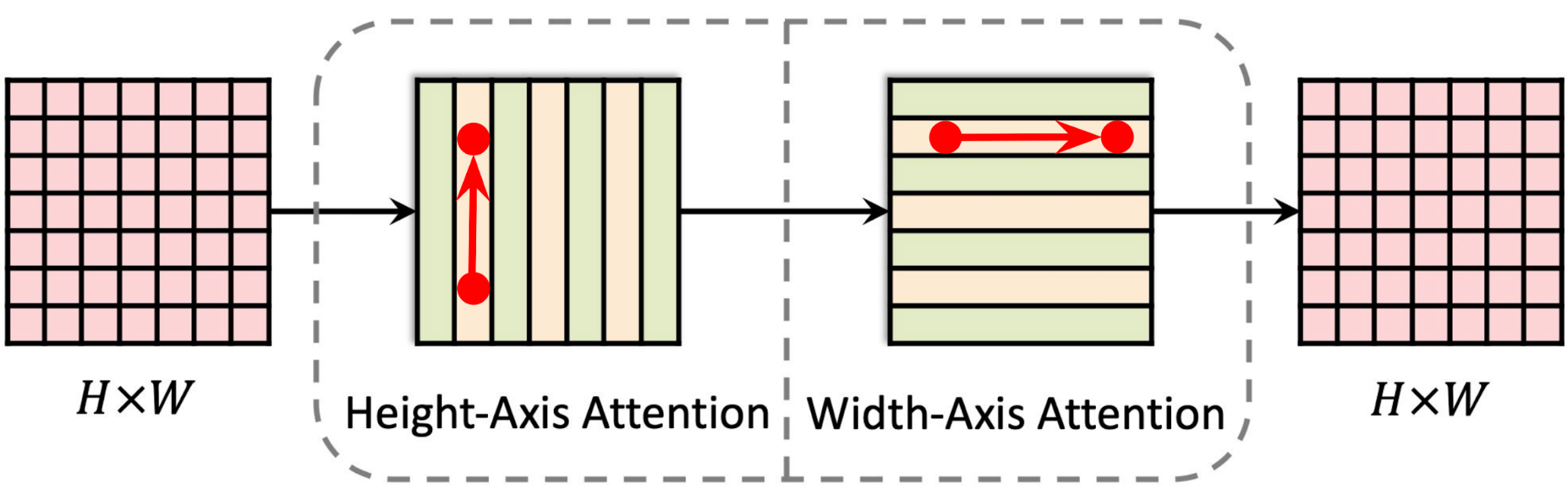 |
| A message can be passed globally with two hops. |
Note that a message or feature vector at (x1, y1) can always be passed globally on a 2D lattice to any position (x2, y2), with one hop on the height-axis (x1, y1 →x1, y2), followed by another hop on the width axis (x1, y2 → x2, y2). In this way, we are able to model 2D long-range relations in a single residual block. This axial-attention design also reduces the complexity from quadratic to linear and enables global receptive fields in all layers of a model.
Position-Sensitive Self-Attention
Additionally, we propose a position-sensitive formulation for self-attention. Previous self-attention formulations enabled a given pixel A to aggregate long-range context B, but provided no information about where in the receptive field the context originated. For example, perhaps the feature at pixel A represents the eye of a cat, and the context B might be the nose and another eye. In this case, the aggregated feature at pixel A would be a nose and two eyes, regardless of the geometric structure of a face. This could cause a false indication of the presence of a face when the two eyes are on the bottom-left of an image and the nose is on the top-right. A recently proposed solution is to impose a positional bias on where in the receptive field the context can originate. This bias depends on the feature at A only, (an eye), but not the feature at B, which contains important contextual information.
In this work, we let this bias also depend on the context feature at B (i.e., the nose and another eye). This change enables a more accurate positional bias when a pixel and the context informing it are far away from one another and thus contains different information about the bias. In addition, when pixel A aggregates the context feature B, we also include a feature that indicates the relative position from A to B. This change enables A to know precisely where B originated. These two changes make self-attention position-sensitive, especially in the situation of long-range modeling.
Results
We have tested Axial-DeepLab on COCO, and Cityscapes for panoptic segmentation. Improvements over the state-of-the-art Panoptic-DeepLab for each dataset can be seen in the table below. In particular, our Axial-DeepLab outperforms Panoptic-DeepLab by 2.8% Panoptic Quality (PQ) on the COCO test-dev set. Our single-scale small model performs better than multi-scale Panoptic-DeepLab while improving computational efficiency by 27x and using only 1/4 the number of parameters. We also show state-of-the-art results on Cityscapes. Moreover, we find that the performance increases as the block receptive field increases from 5 × 5 to 65 × 65. Our model is also more robust to out-of-distribution scales, on which the model was not trained.
| Model | COCO | Citiscapes | ||
| Panoptic-DeepLab | 39.7 | 65.3 | ||
| Axial-DeepLab (ours) | 43.4 (+3.7) | 66.5 (+1.2) |
| Single scale comparison with Panoptic-DeepLab on validation sets |
Besides our main results on panoptic segmentation, our full axial-attention model, Axial-ResNet, also performs better than the previous best stand-alone self-attention model on ImageNet.
| Model | Params | M-Adds | Top-1 | |||
| ResNet-50 | 25.6M | 4.1B | 76.9 | |||
| Stand-Alone | 18.0M | 3.6B | 77.6 | |||
| Full Axial-Attention (ours) | 12.5M | 3.3B | 78.1 |
| Full Axial-Attention also works well on ImageNet. |
Conclusion
We have proposed and demonstrated the effectiveness of position-sensitive axial-attention on image classification and panoptic segmentation. On ImageNet, our Axial-ResNet, formed by stacking axial-attention blocks, achieves state-of-the-art results among stand-alone self-attention models. We further convert Axial-ResNet to Axial-DeepLab for bottom-up panoptic segmentation, and also show state-of-the-art performance on several benchmarks, including COCO, and Cityscapes. We hope our promising results could establish that axial-attention is an effective building block for modern computer vision models.
Acknowledgements
This post reflects the work of the authors as well as Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. We also thank Niki Parmar for discussion and support; Ashish Vaswani, Xuhui Jia, Raviteja Vemulapalli, Zhuoran Shen for their insightful comments and suggestions; Maxwell Collins and Blake Hechtman for technical support.
-
Labels:
- Machine Perception
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

October 23, 2025
Google Earth AI: Unlocking geospatial insights with foundation models and cross-modal reasoning- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Machine Perception