Autonomous visual information seeking with large language models
August 18, 2023
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team
Quick links
There has been great progress towards adapting large language models (LLMs) to accommodate multimodal inputs for tasks including image captioning, visual question answering (VQA), and open vocabulary recognition. Despite such achievements, current state-of-the-art visual language models (VLMs) perform inadequately on visual information seeking datasets, such as Infoseek and OK-VQA, where external knowledge is required to answer the questions.
 |
| Examples of visual information seeking queries where external knowledge is required to answer the question. Images are taken from the OK-VQA dataset. |
In “AVIS: Autonomous Visual Information Seeking with Large Language Models”, we introduce a novel method that achieves state-of-the-art results on visual information seeking tasks. Our method integrates LLMs with three types of tools: (i) computer vision tools for extracting visual information from images, (ii) a web search tool for retrieving open world knowledge and facts, and (iii) an image search tool to glean relevant information from metadata associated with visually similar images. AVIS employs an LLM-powered planner to choose tools and queries at each step. It also uses an LLM-powered reasoner to analyze tool outputs and extract key information. A working memory component retains information throughout the process.
 |
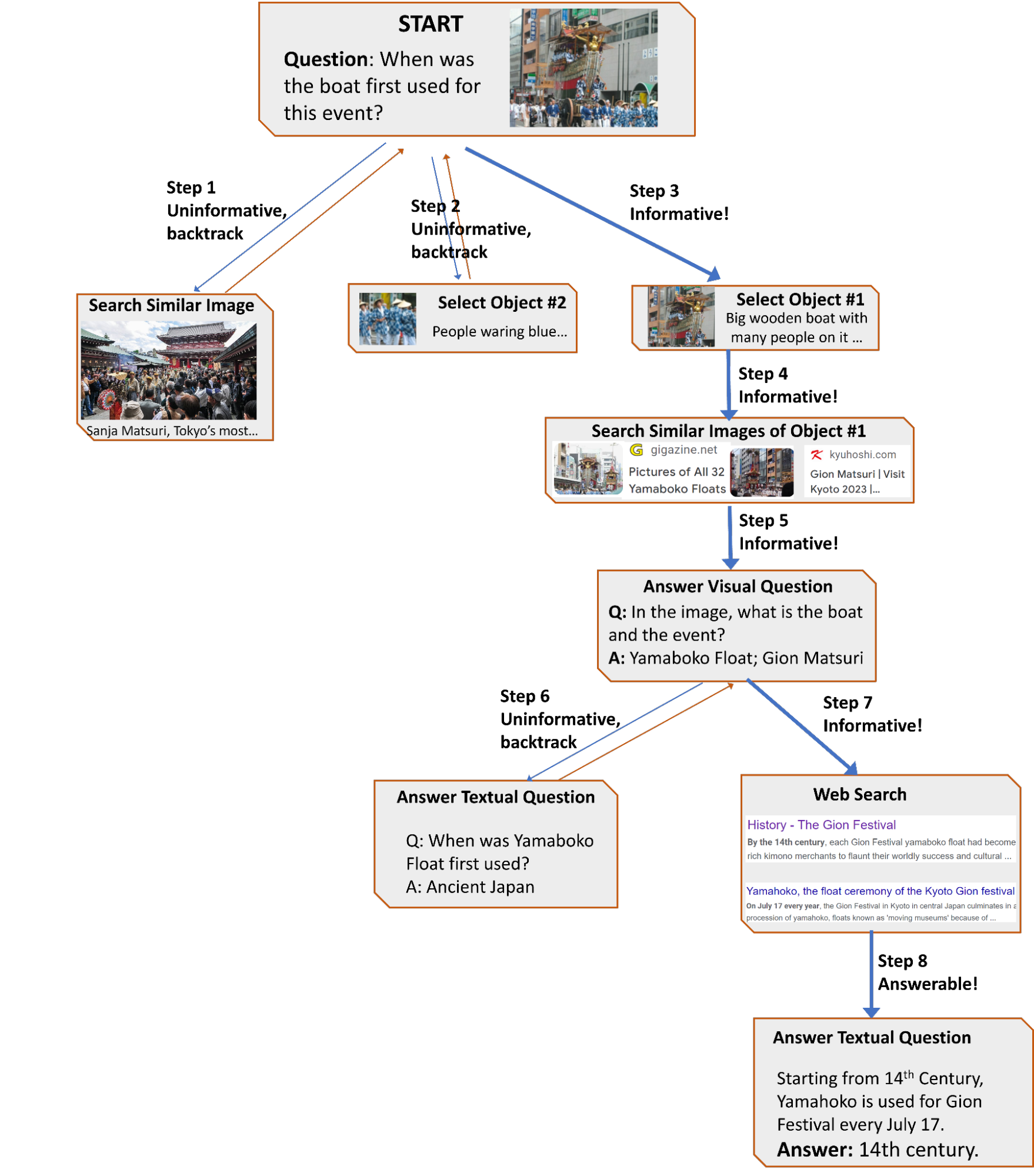
| An example of AVIS’s generated workflow for answering a challenging visual information seeking question. The input image is taken from the Infoseek dataset. |
Comparison to previous work
Recent studies (e.g., Chameleon, ViperGPT and MM-ReAct) explored adding tools to LLMs for multimodal inputs. These systems follow a two-stage process: planning (breaking down questions into structured programs or instructions) and execution (using tools to gather information). Despite success in basic tasks, this approach often falters in complex real-world scenarios.
There has also been a surge of interest in applying LLMs as autonomous agents (e.g., WebGPT and ReAct). These agents interact with their environment, adapt based on real-time feedback, and achieve goals. However, these methods do not restrict the tools that can be invoked at each stage, leading to an immense search space. Consequently, even the most advanced LLMs today can fall into infinite loops or propagate errors. AVIS tackles this via guided LLM use, influenced by human decisions from a user study.
Informing LLM decision making with a user study
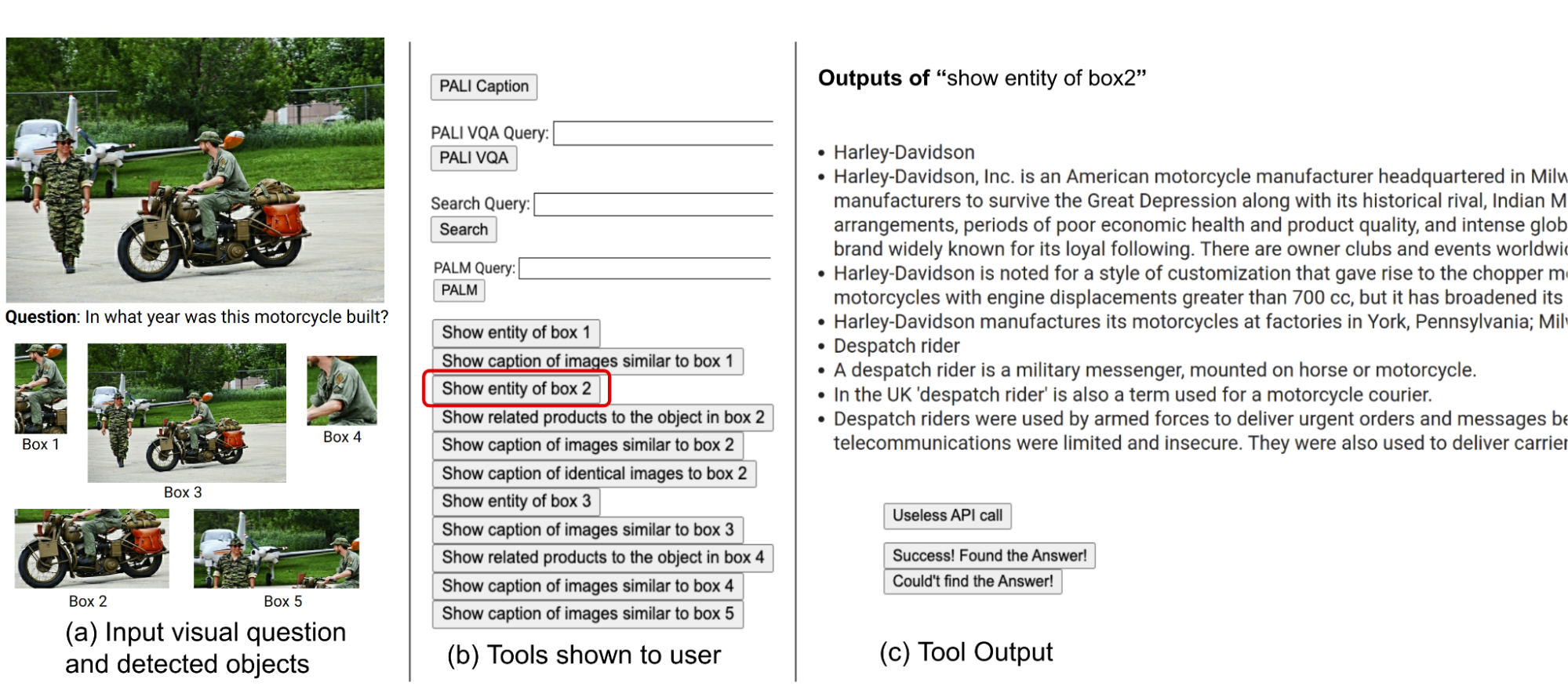
Many of the visual questions in datasets such as Infoseek and OK-VQA pose a challenge even for humans, often requiring the assistance of various tools and APIs. An example question from the OK-VQA dataset is shown below. We conducted a user study to understand human decision-making when using external tools.
 |
| We conducted a user study to understand human decision-making when using external tools. Image is taken from the OK-VQA dataset. |
The users were equipped with an identical set of tools as our method, including PALI, PaLM, and web search. They received input images, questions, detected object crops, and buttons linked to image search results. These buttons offered diverse information about the detected object crops, such as knowledge graph entities, similar image captions, related product titles, and identical image captions.
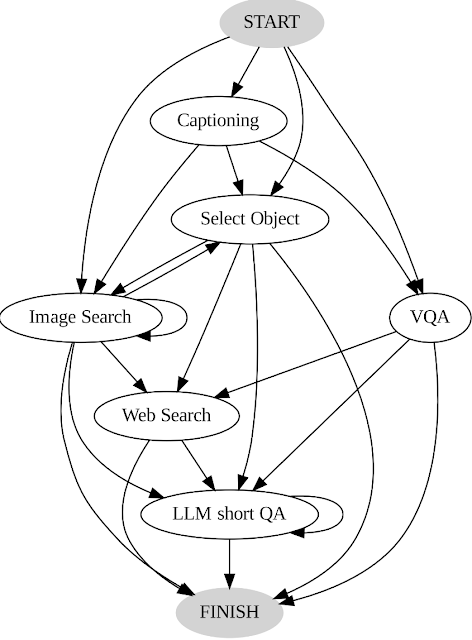
We record user actions and outputs and use it as a guide for our system in two key ways. First, we construct a transition graph (shown below) by analyzing the sequence of decisions made by users. This graph defines distinct states and restricts the available set of actions at each state. For example, at the start state, the system can take only one of these three actions: PALI caption, PALI VQA, or object detection. Second, we use the examples of human decision-making to guide our planner and reasoner with relevant contextual instances to enhance the performance and effectiveness of our system.
 |
| AVIS transition graph. |
General framework
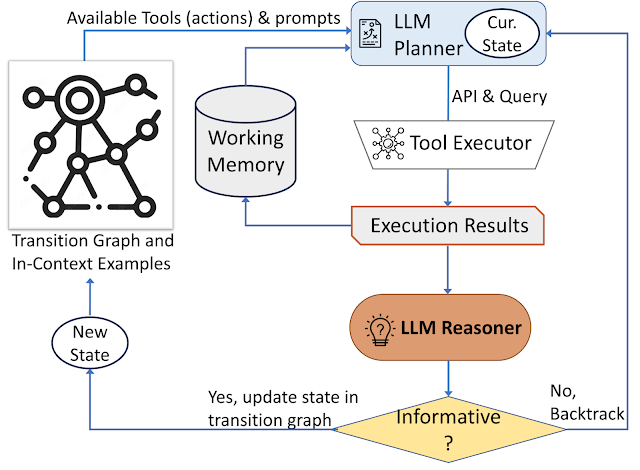
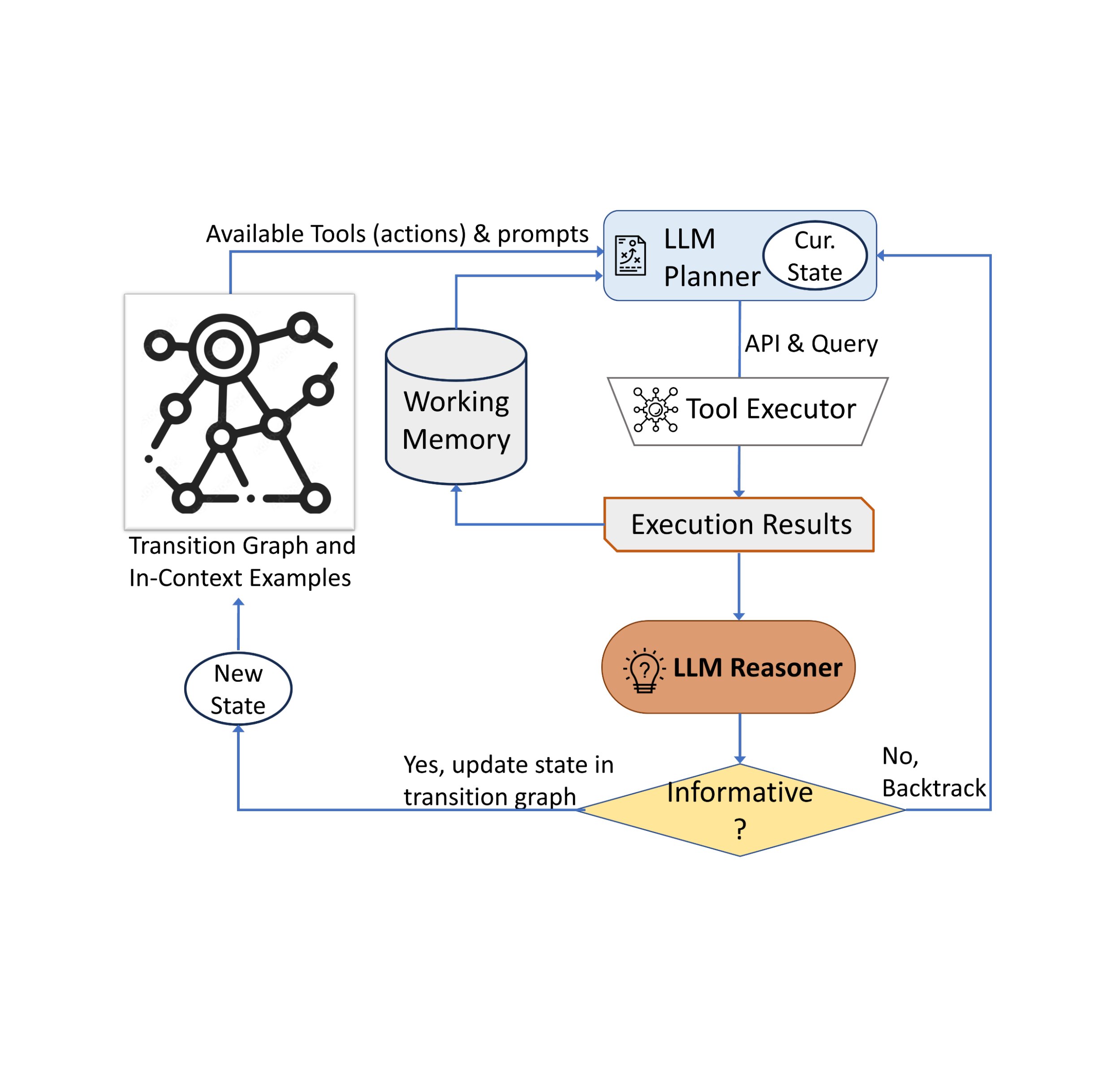
Our approach employs a dynamic decision-making strategy designed to respond to visual information-seeking queries. Our system has three primary components. First, we have a planner to determine the subsequent action, including the appropriate API call and the query it needs to process. Second, we have a working memory that retains information about the results obtained from API executions. Last, we have a reasoner, whose role is to process the outputs from the API calls. It determines whether the obtained information is sufficient to produce the final response, or if additional data retrieval is required.
The planner undertakes a series of steps each time a decision is required regarding which tool to employ and what query to send to it. Based on the present state, the planner provides a range of potential subsequent actions. The potential action space may be so large that it makes the search space intractable. To address this issue, the planner refers to the transition graph to eliminate irrelevant actions. The planner also excludes the actions that have already been taken before and are stored in the working memory.
Next, the planner collects a set of relevant in-context examples that are assembled from the decisions previously made by humans during the user study. With these examples and the working memory that holds data collected from past tool interactions, the planner formulates a prompt. The prompt is then sent to the LLM, which returns a structured answer, determining the next tool to be activated and the query to be dispatched to it. This design allows the planner to be invoked multiple times throughout the process, thereby facilitating dynamic decision-making that gradually leads to answering the input query.
We employ a reasoner to analyze the output of the tool execution, extract the useful information and decide into which category the tool output falls: informative, uninformative, or final answer. Our method utilizes the LLM with appropriate prompting and in-context examples to perform the reasoning. If the reasoner concludes that it’s ready to provide an answer, it will output the final response, thus concluding the task. If it determines that the tool output is uninformative, it will revert back to the planner to select another action based on the current state. If it finds the tool output to be useful, it will modify the state and transfer control back to the planner to make a new decision at the new state.
 |
| AVIS employs a dynamic decision-making strategy to respond to visual information-seeking queries. |
Results
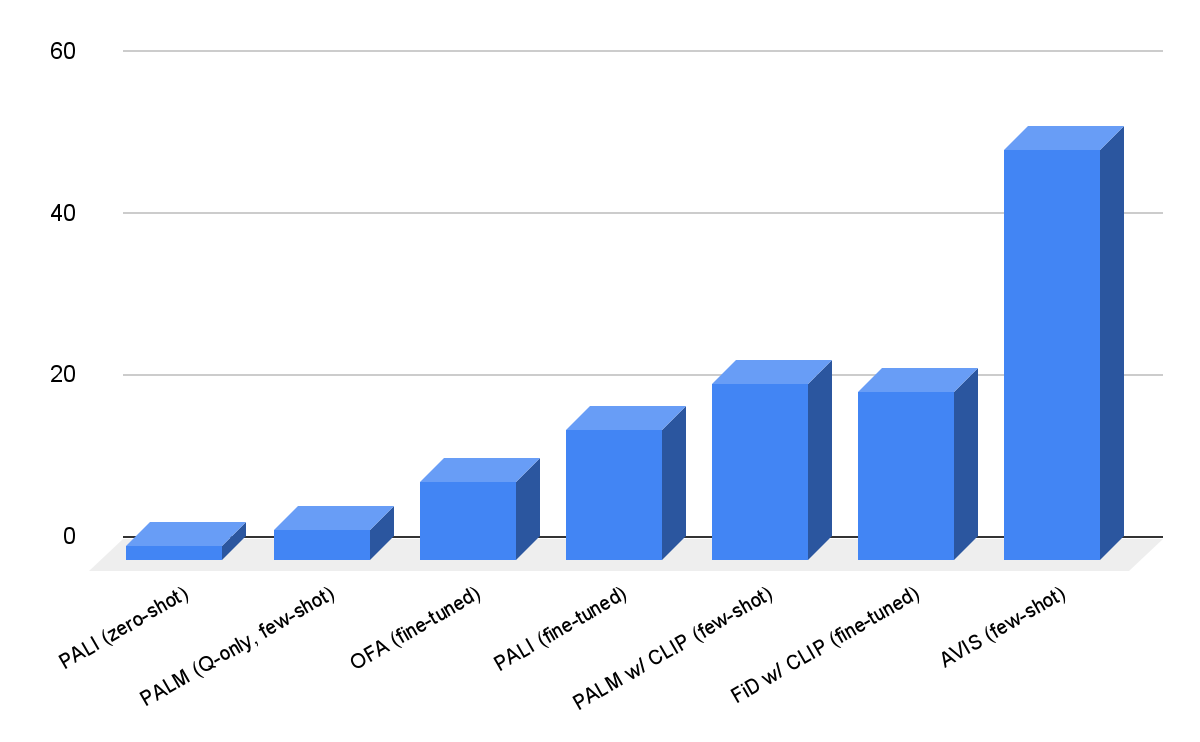
We evaluate AVIS on Infoseek and OK-VQA datasets. As shown below, even robust visual-language models, such as OFA and PaLI, fail to yield high accuracy when fine-tuned on Infoseek. Our approach (AVIS), without fine-tuning, achieves 50.7% accuracy on the unseen entity split of this dataset.
 |
| AVIS visual question answering results on Infoseek dataset. AVIS achieves higher accuracy in comparison to previous baselines based on PaLI, PaLM and OFA. |
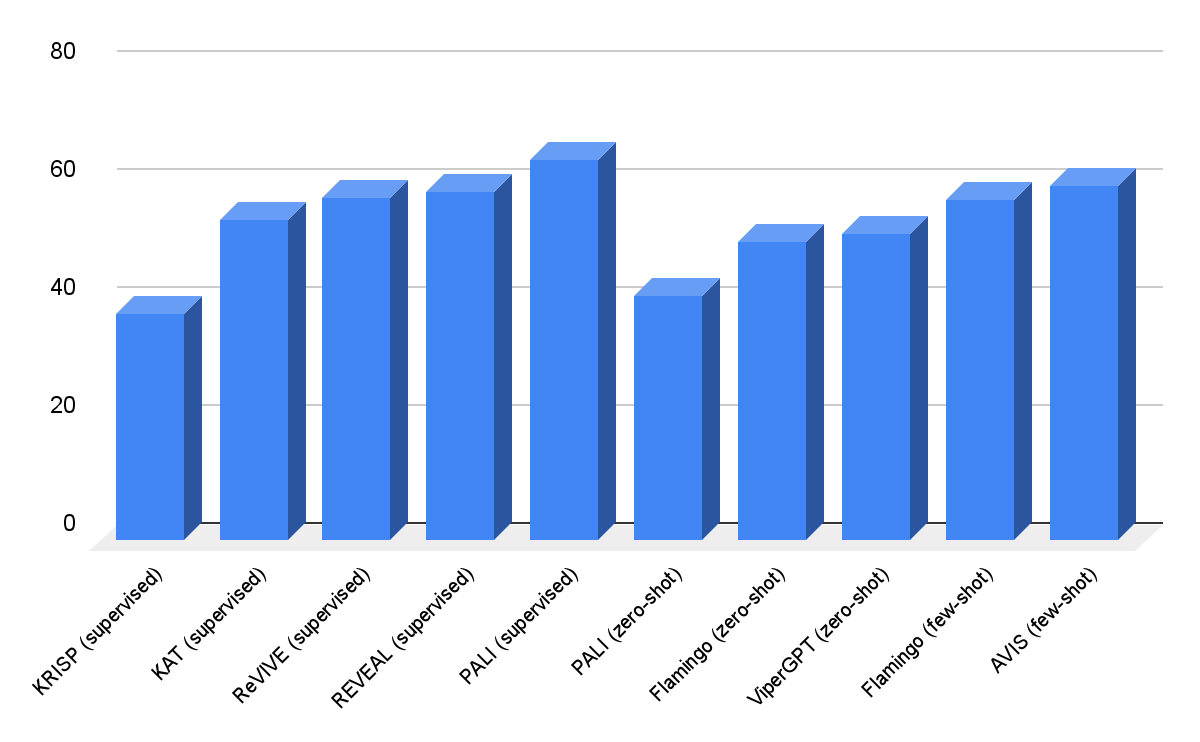
Our results on the OK-VQA dataset are shown below. AVIS with few-shot in-context examples achieves an accuracy of 60.2%, higher than most of the previous works. AVIS achieves lower but comparable accuracy in comparison to the PALI model fine-tuned on OK-VQA. This difference, compared to Infoseek where AVIS outperforms fine-tuned PALI, is due to the fact that most question-answer examples in OK-VQA rely on common sense knowledge rather than on fine-grained knowledge. Therefore, PaLI is able to encode such generic knowledge in the model parameters and doesn’t require external knowledge.
 |
| Visual question answering results on A-OKVQA. AVIS achieves higher accuracy in comparison to previous works that use few-shot or zero-shot learning, including Flamingo, PaLI and ViperGPT. AVIS also achieves higher accuracy than most of the previous works that are fine-tuned on OK-VQA dataset, including REVEAL, ReVIVE, KAT and KRISP, and achieves results that are close to the fine-tuned PaLI model. |
Conclusion
We present a novel approach that equips LLMs with the ability to use a variety of tools for answering knowledge-intensive visual questions. Our methodology, anchored in human decision-making data collected from a user study, employs a structured framework that uses an LLM-powered planner to dynamically decide on tool selection and query formation. An LLM-powered reasoner is tasked with processing and extracting key information from the output of the selected tool. Our method iteratively employs the planner and reasoner to leverage different tools until all necessary information required to answer the visual question is amassed.
Acknowledgements
This research was conducted by Ziniu Hu, Ahmet Iscen, Chen Sun, Kai-Wei Chang, Yizhou Sun, David A. Ross, Cordelia Schmid and Alireza Fathi.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence