Automating Drug Discoveries Using Computer Vision
July 12, 2018
Vincent Vanhoucke, Principal Scientist, Google Brain Team
Quick links
“Every time you miss a protein crystal, because they are so rare, you risk missing on an important biomedical discovery.”
- Patrick Charbonneau, Duke University Dept. of Chemistry and Lead Researcher, MARCO initiative.
Protein crystallization is a key step to biomedical research concerned with discovering the structure of complex biomolecules. Because that structure determines the molecule’s function, it helps scientists design new drugs that are specifically targeted to that function. However, protein crystals are rare and difficult to find. Hundreds of experiments are typically run for each protein, and while the setup and imaging are mostly automated, finding individual protein crystals remains largely performed through visual inspection and thus prone to human error. Critically, missing these structures can result in lost opportunity for important biomedical discoveries for advancing the state of medicine.
In collaboration with researchers from the MAchine Recognition of Crystallization Outcomes (MARCO) initiative, we have published “Classification of Crystallization Outcomes using Deep Convolutional Neural Networks” in PLOS One (ArXiv preprint), in which we discuss how we used some of the most recent architectures of deep convolutional networks and customized them to achieve an accuracy of more than 94% on the visual recognition task of identifying protein crystals. In order to spur further research in this area, we have made the data freely accessible, and open-sourced our model as part of the TensorFlow research model repository, and available to researchers as a Cloud ML Engine endpoint.
 |
| Image of protein crystal, courtesy of the MARCO repository (CC-BY-4.0 license) |
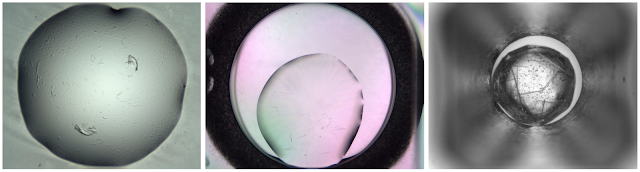
Due to the large variability between imaging technologies and data acquisition approaches, coming up with a single approach to the visual recognition problem may appear daunting. Crystals can be very small, which makes them rare structures in a large image containing otherwise undifferentiated visual clutter.
 |
| Samples from the MARCO repository, illustrating the degree of variability between data sources. |
This work is a great example of the effectiveness of multi-institutional collaborations aimed at solving problems that require data in amounts and level of diversity that no single collaborator has access to. We invite researchers to take advantage of these resources that are the result of this work and share what they learn. This research was conducted as a personal 20% project by the author. To learn more about this work, please see our paper here and read the recent Duke Research Blog post.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯