Automatically making sense of data
December 2, 2014
Posted by Kevin Murphy, Research Scientist and David Harper, Head of University Relations, EMEA
Quick links
While the availability and size of data sets across a wide range of sources, from medical to scientific to commercial, continues to grow, there are relatively few people trained in the statistical and machine learning methods required to test hypotheses, make predictions, and otherwise create interpretable knowledge from this data. But what if one could automatically discover human-interpretable trends in data in an unsupervised way, and then summarize these trends in textual and/or visual form?
To help make progress in this area, Professor Zoubin Ghahramani and his group at the University of Cambridge received a Google Focused Research Award in support of The Automatic Statistician project, which aims to build an "artificial intelligence for data science".
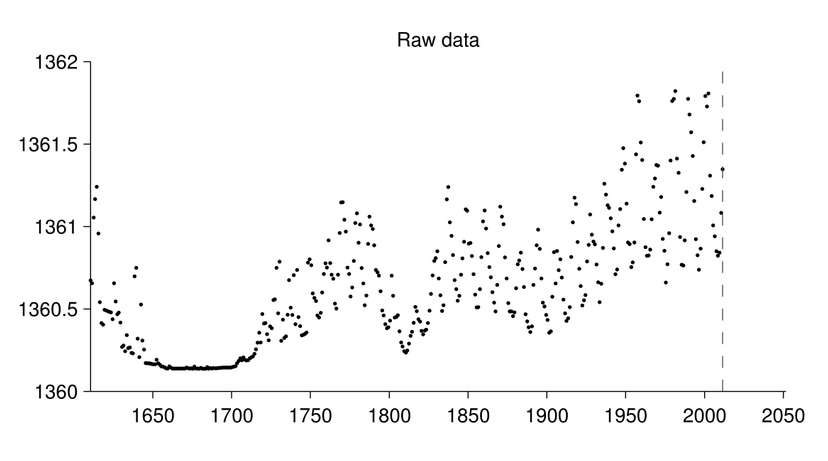
So far, the project has mostly been focussing on finding trends in time series data. For example, suppose we measure the levels of solar irradiance over time, as shown in this plot:
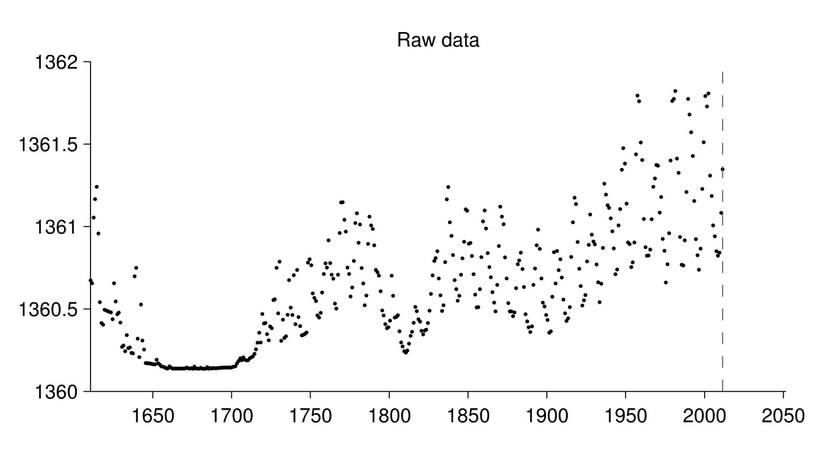 This time series clearly exhibits several sources of variation: it is approximately periodic (with a period of about 11 years, known as the Schwabe cycle), but with notably low levels of activity in the late 1600s. It would be useful to automatically discover these kinds of regularities (as well as irregularities), to help further basic scientific understanding, as well as to help make more accurate forecasts in the future.
This time series clearly exhibits several sources of variation: it is approximately periodic (with a period of about 11 years, known as the Schwabe cycle), but with notably low levels of activity in the late 1600s. It would be useful to automatically discover these kinds of regularities (as well as irregularities), to help further basic scientific understanding, as well as to help make more accurate forecasts in the future.We can model such data using non-parametric statistical models based on Gaussian processes. Such methods require the specification of a kernel function which characterizes the nature of the underlying function that can accurately model the data (e.g., is it periodic? is it smooth? is it monotonic?). While the parameters of this kernel function are estimated from data, the form of the kernel itself is typically specified by hand, and relies on the knowledge and experience of a trained data scientist.
Prof Ghahramani's group has developed an algorithm that can automatically discover a good kernel, by searching through an open-ended space of sums and products of kernels as well as other compositional operations. After model selection and fitting, the Automatic Statistician translates each kernel into a text description describing the main trends in the data in an easy-to-understand form.
The compositional structure of the space of statistical models neatly maps onto compositionally constructed sentences allowing for the automatic description of the statistical models produced by any kernel. For example, in a product of kernels, one kernel can be mapped to a standard noun phrase (e.g. ‘a periodic function’) and the other kernels to appropriate modifiers of this noun phrase (e.g. ‘whose shape changes smoothly’, ‘with growing amplitude’). The end result is an automatically generated 5-15 page report describing the patterns in the data with figures and tables supporting the main claims. Here is an extract of the report produced by their system for the solar irradiance data:
 |
| Extract of the report for the solar irradiance data, automatically generated by the automatic statistician. |
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯