ATLAS: Practical scaling laws for multilingual models
January 27, 2026
Shayne Longpre, Google Cloud Student Researcher, and Sayna Ebrahimi, Research Scientist, Google DeepMind
We introduce new scaling laws for massively multilingual language models. ATLAS provides guidance on how to mix data and train the most effective models to serve languages beyond English.
Quick links
Over 50% of AI model users speak non-English languages, yet publicly accessible scaling laws are overwhelmingly focused on the English language. This imbalance creates a critical gap in public research, leaving model builders, tasked with serving billions of international and multilingual users, without data-driven guidance for key development decisions about efficiency, quality, and cost when building for non-English languages or with specific language mixtures.
In “ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality”, to be presented at ICLR 2026, we aim to address this gap. We present the largest public multilingual pre-training study to date, spanning 774 training runs across 10M–8B parameter models. It includes data spanning 400+ languages and evaluations in 48 languages. As a result of this study, we estimate the synergies between 1,400 pairs of languages, and introduce adaptive transfer scaling laws (ATLAS) for building multilingual models that enable practitioners to efficiently balance the mix of languages in training data with model size.
ATLAS: A single scaling law that adapts to multilingual mixtures
ATLAS is a simple, practical approach to determining optimal model size, data volume, and language mixtures for training. Unlike traditional scaling laws that focus on monolingual settings, ATLAS provides these recommendations for more complex, multilingual environments. It specifically optimizes performance on a target language (e.g., Catalan) by leveraging data from multiple different languages. ATLAS extends these traditional scaling law principles through three components:
- A cross-lingual transfer matrix used to identify which languages are best to train together
- A scaling law that provides guidance on efficiently expanding model size and data as the number of supported languages increases
- Rules for deciding when to pre-train a model from scratch versus fine-tuning from a multilingual checkpoint
ATLAS accomplishes this by training on hundreds of multilingual experiments (using the MADLAD-400 corpus with over 750 runs across 400+ languages) and accounting for three distinct data sources: 1) the target language, 2) similar transfer languages according to empirical analysis (e.g., Catalan might include Latin languages like Spanish, Portuguese, and Italian), and 3) all other languages. This novel approach enables the law to learn how much each source actually helps or hinders the target language, a capability prior laws did not support.
Evaluation
We used the MADLAD-400 dataset to evaluate how well ATLAS predicts a model’s performance on new model sizes, varying amounts of training data, or new language mixtures. To do this, we measure performance using a vocabulary-insensitive loss across over 750 independent runs in monolingual, bilingual, and massively multilingual settings. Our evaluations show that ATLAS consistently outperforms prior work.
For six languages — English (EN), French (FR), Russian (RU), Chinese (ZH), Hindi (HI), and Swahili (SW) — we analyzed how ATLAS predicted the optimal model size (N) and data size (D) should be scaled. When we compared these optimal scaling trajectories across languages, we made two observations. The curves look strikingly similar, but training with a multilingual vocabulary or fully multilingual data comes with a compute-efficiency tax — especially for English. Low-resource languages show upward bends as they run out of data, and the model struggles to learn from data repetition. ATLAS explicitly models these effects.
These charts show the optimal scaling trajectories (model size (N) and data size (D) determined by ATLAS for each language and model type. The lines represent three configurations: Solid (monolingual vocab/data), Dashed (multilingual vocab/monolingual data), and Dotted (multilingual vocab/multilingual data). The dotted lines are consistently highest, indicating that training with a full multilingual setup requires slightly more compute for the same quality.
The cross-lingual transfer map
Next, we measured language-to-language synergies and interference at scale, producing a matrix that quantifies how much training on language A helps (or hurts) language B. Our results show very intuitive results: Norwegian is helped primarily by Swedish and German, Malay by Indonesian, and Arabic by Hebrew. English, French, and Spanish are the most widely helpful languages with which to train, likely due to the inherent quality, heterogeneity, and quantity of text in these languages found on the web.
The analysis shows that the biggest predictor of positive transfer is sharing a script and/or language family (e.g., Latin script), statistically significant with p < .001. English helps many, but not all, languages; and transfer isn’t always symmetric (A can help B more than B helps A). These measurements turn “hunches” into data-driven language mix choices.
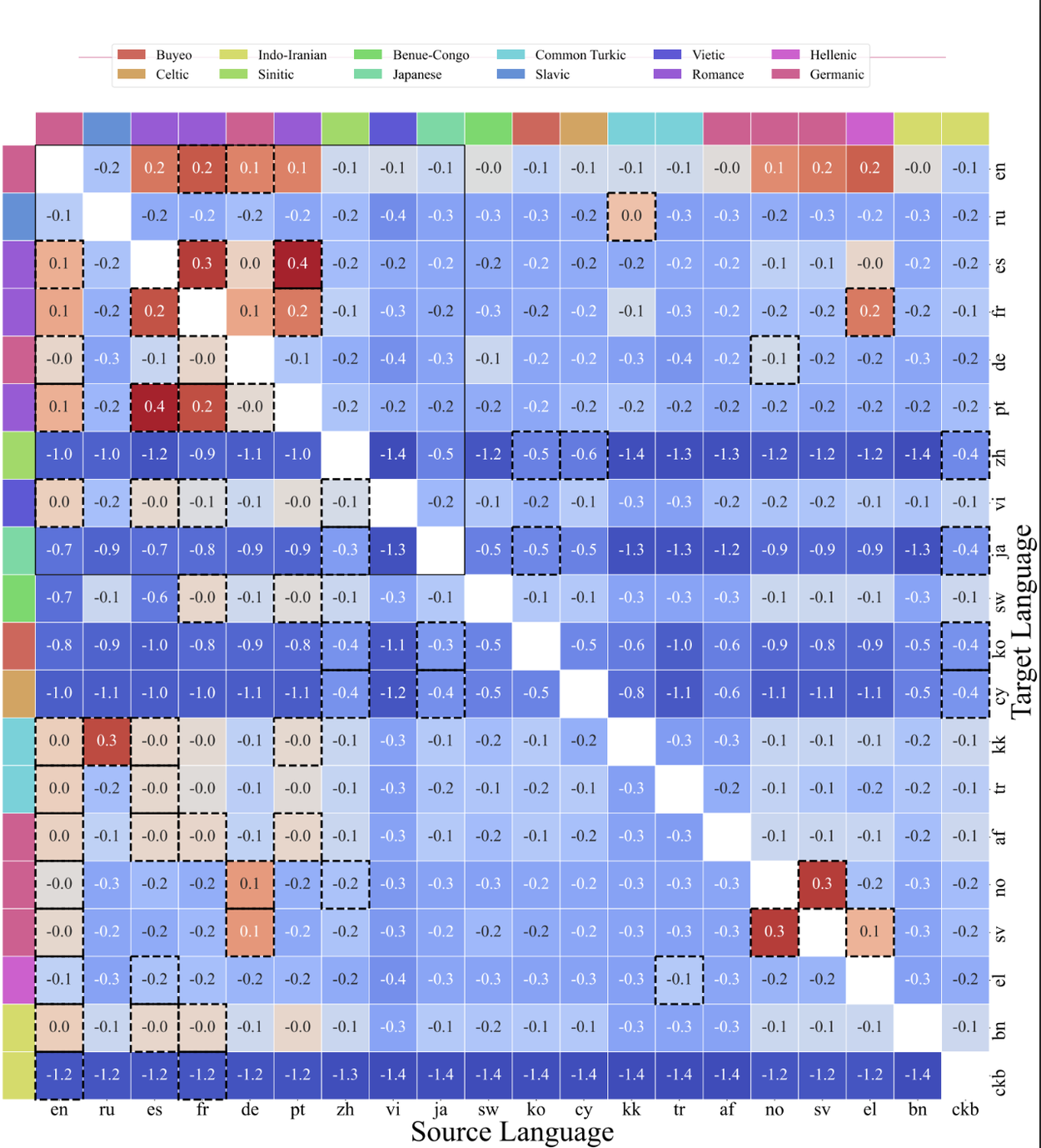
This heatmap shows the cross-lingual transfer matrix, quantifying language-to-language synergies and inference. Red indicates that a language helps and blue indicates it hurts. Boxes highlight each target language’s top-5 helpers. Languages that share the same writing system (e.g., Latin script) are notably more synergistic.
Decoding the “curse of multilinguality” with clear scaling rules
The “curse of multilinguality” is a phenomenon where models trained on multiple languages see a decrease in performance with each new language due to limited model capacity. We formalize this problem with a scaling law that considers not just model size (N), and quantity of training data (D), but the number of languages in that data (K). Fitting this law to many experiments, we found that while adding languages brings a mild capacity tax, there is a high-degree of positive transfer. This means if we want to train a model to support twice as many languages (2·K) then we should increase model size by 1.18x, and total data by 1.66x. This equates to 83% of data in each of the 2K languages. Although there is less data per language, the positive synergies from learning on all of them means the capacity constraints that cause degradation to the performance are offset.
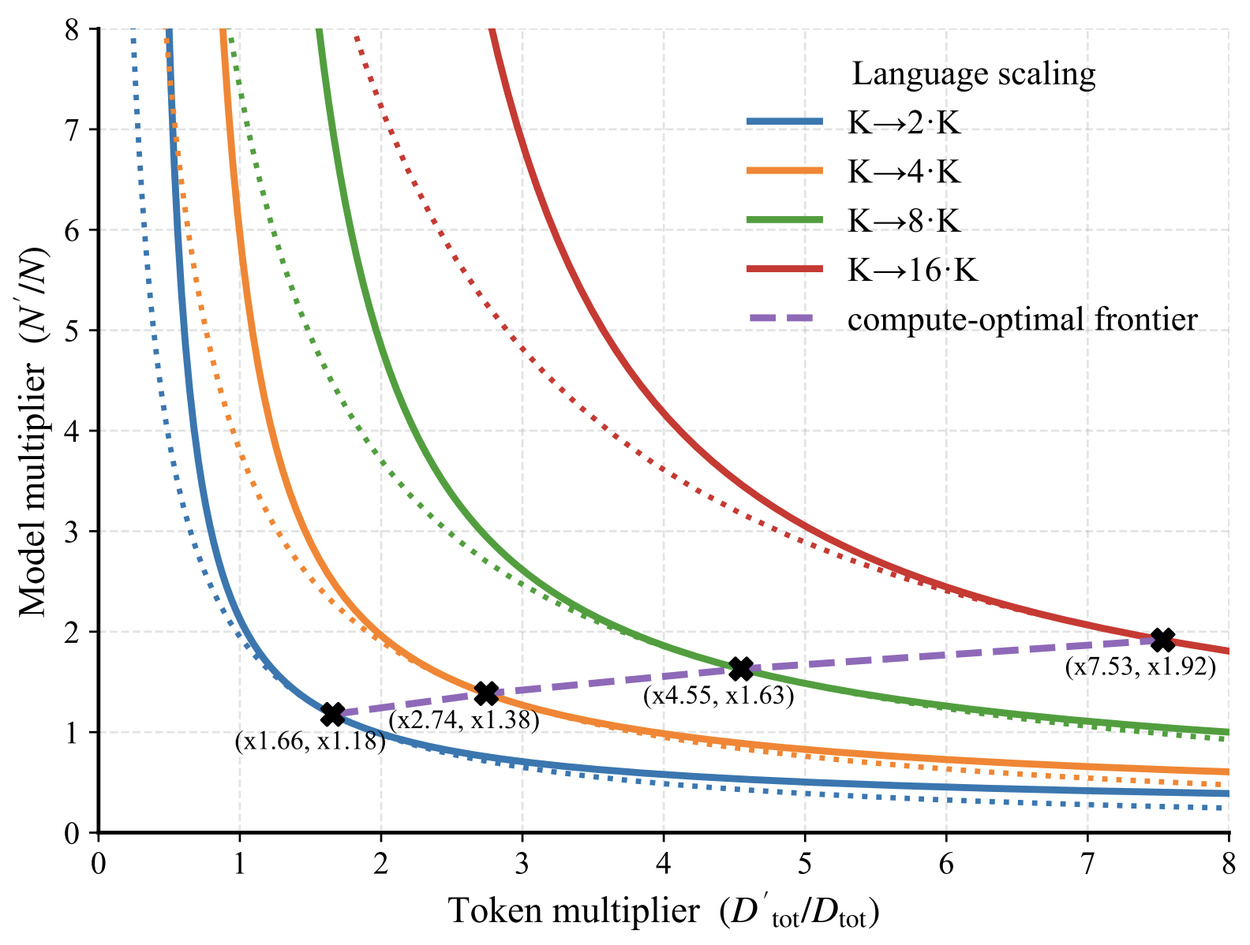
These curves show how much to increase model size N or data size D, when we scale from K to rK training languages. For instance, the blue solid-line curve shows all the possibilities for how much to increase N and/or D to achieve the same performance with 2K as with K languages. The dotted purple line shows the most computationally efficient way to increase N and D, as we increase K.
When to pre-train vs. fine-tune a multilingual checkpoint
For ten languages, we compare two paths to get the best performing model: (a) pre-train from scratch on the target language or (b) fine-tune from a strong multilingual “Unimax” checkpoint. Option (b) is likely to have the best performance with minimal additional compute, as the model is already pretty strong across languages. However, if the model can be trained for much longer, then option (a) can often yield better long-term results. Our goal is to find the crossover point between the two training curves, based on how much compute the model builder has to spend.
Our results show that fine-tuning wins early, but pre-training overtakes once you can afford enough tokens. In our runs, the crossover typically occurs between ~144B and 283B tokens (language-dependent) for models with 2B parameters. Next, we plotted the crossover point as a function of model size. This gives a concrete, budget-aware rule of thumb: if your token and compute budget is below the crossover point for your model size, start from a multilingual checkpoint; otherwise, pre-training from scratch will usually finish ahead. Note that exact thresholds depend on the base model and mixture.
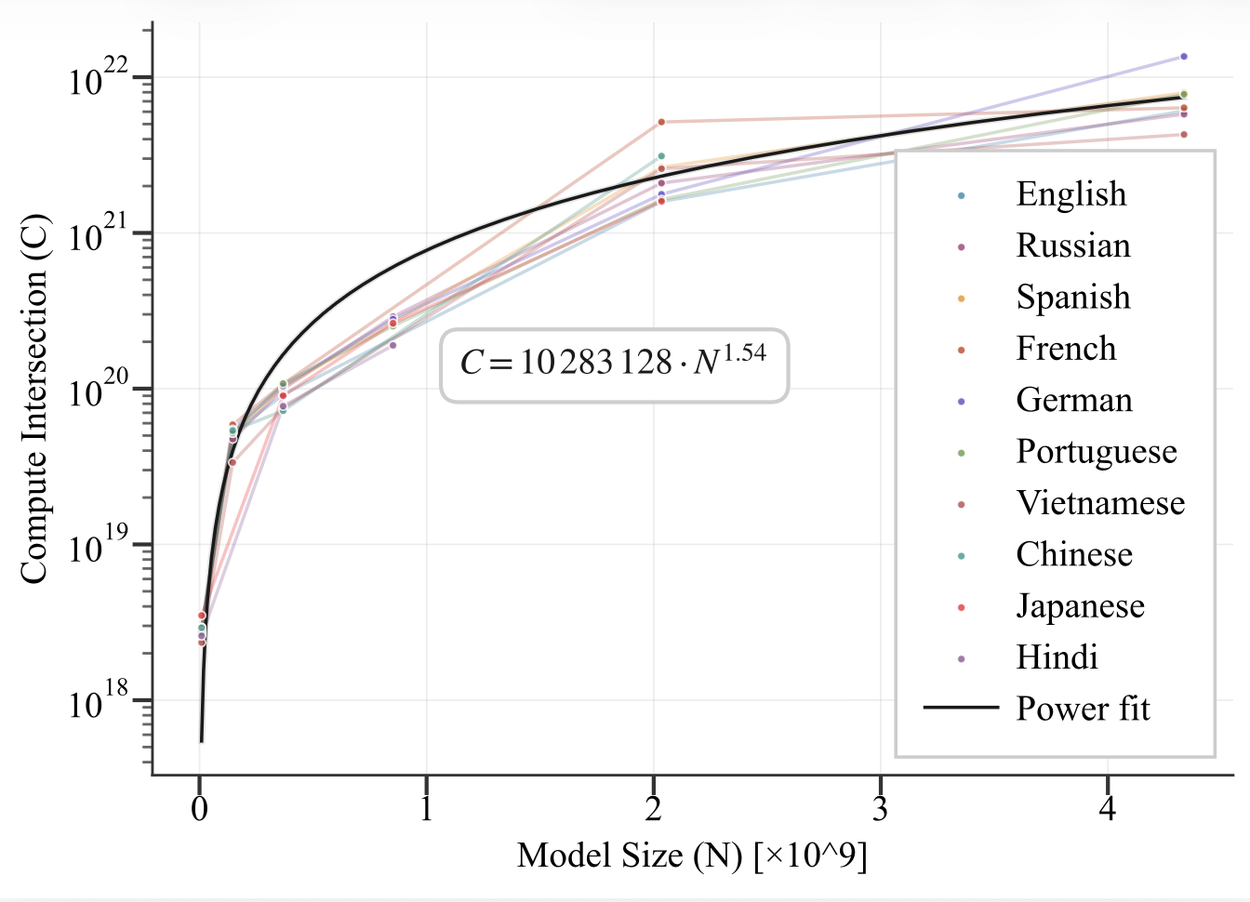
As model size increases, the amount of compute (or training tokens since C=6ND) needed to hit the crossover point (where pre-training from scratch is better than fine-tuning) increases. We estimate a function for the crossover point based on model size. You can see how this estimated rule (black line) approximately fits the cross-over points found for the 10 plotted languages.
Try it yourself
By moving beyond English-centric scaling, ATLAS provides a roadmap for global model developers. It can be directly applied to scale language models beyond English by helping developers:
- Planning to train a new multilingual or non-English model? Use Figure 1 or Table C.1 from the paper to get a sense of the potential scaling laws based on vocabulary or training choices.
- Choosing a new training mix? Consult the transfer matrix (Figure 2) to pick source languages that empirically help your targets — especially those sharing the same script/family.
- Training a new model with more languages? Consult Section 5 to determine how to most efficiently expand your model size and data size to mitigate the effects of the curse of multilinguality.
- Compute-constrained? Consult Section 6 to decide if you should fine-tune a multilingual model or pre-train from scratch.
We hope this work enables a new generation of multilingual models, serving billions of non-English speakers.
Acknowledgements
We thank Luke Zettlemoyer, Catherine Arnett and Stella Biderman for helpful discussions on the paper. We thank Biao Zhang and Xavier Garcia for the technical discussions and feedback on early directions.
Quick links
Other posts of interest
-

April 16, 2026
Designing synthetic datasets for the real world: Mechanism design and reasoning from first principles- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 16, 2026
AI-generated synthetic neurons speed up brain mapping- General Science ·
- Health & Bioscience ·
- Machine Intelligence
-

April 13, 2026
Towards developing future-ready skills with generative AI- Education Innovation ·
- Generative AI