
Assessing ASR performance with meaning preservation
July 9, 2024
Katrin Tomanek, Software Engineer, and Alicia Martín, Program Manager, Google Research
Quick links
Word error rate (WER) and its inverse, word accuracy (WACC), are established metrics for assessing the syntactic accuracy of automatic speech recognition (ASR) models. However, these metrics do not measure a critical aspect of ASR performance: comprehensibility. This limitation is especially pronounced for users with atypical speech patterns where WER often exceeds 20% and can surpass 60% for certain severities. Despite this, individuals with atypical speech patterns can still benefit from ASR models that have relatively high WER, as long as the comprehensibility, or meaning, of their speech is preserved. This is particularly relevant for use cases like live conversations, voice input for text messages, home automation, and other applications that are tolerant of minor grammatical errors. Indeed, these users and use cases stand to benefit most significantly from ASR models that preserve meaning as they can greatly improve communication.
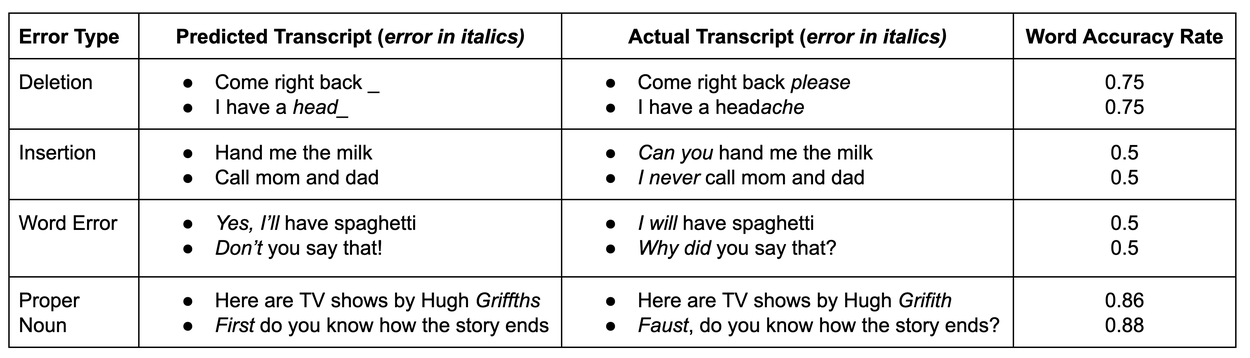
Below are a few examples demonstrating that WACC does not accurately reflect the severity of a transcription error. For several possible error types, we present two examples. While both examples have a similar WACC, the first example has a rather benign error, while the second has a more severe error.
With this in mind, we set out to create a system that will automatically assess the ability of an ASR model to effectively convey the user’s intended message. In our paper “Large Language Models as a Proxy for Human Evaluation in Assessing the Comprehensibility of Disordered Speech Transcription” (ICASSP 2024), we introduce a novel approach using a large language model (LLM) to determine whether a transcript accurately captures the intended meaning compared to a reference text. Building upon this approach, here we also report how using Gemini allows us to both use a significantly smaller model without much loss in performance as well as gain multi-linguality for our meaning assessment task without the need for additional training.
Meaning preservation as an alternative metric
Our research leveraged the Project Euphonia corpus, a repository of disordered speech encompassing over 1.2 million utterances from approximately 2,000 individuals with diverse speech impairments. To expand data collection to Spanish speakers, Project Euphonia partnered with the International Alliance of ALS/MND Associations, which facilitated the contribution of speech samples from individuals living with ALS in Mexico, Colombia, and Peru. Similarly, Project Euphonia expanded to French speakers through a partnership with Romain Gombert from the Paris Brain Institute to collect data from people with atypical speech in France.
For our experiments, we generated a dataset of 4,731 examples consisting of ground truth and transcription error pairs along with a human label identifying whether those pairs would be meaning preserving or not (see details in our paper). We split the dataset into training, test, and validation sets (80% / 10% / 10%, respectively) ensuring the three sets would not overlap on the ground truth phrase level.
With this data, we trained a classifier for meaning preservation on top of a base LLM. Using prompt-tuning — a parameter-efficient method to adapt LLMs — we conditioned our base LLM on our training set to predict the labels “yes” or “no” to indicate whether the meaning has been preserved or not.
We use the following format to represent the data to the LLM:

Two examples of the representation of the training data using curly braces format. The “input sequence” is also what is fed to the model at inference time, and “target sequence” is what the model has learned to predict.
For inference, instead of generating the response, we obtain the LLM’s logits as scores for the tokens corresponding to the two class labels (“yes” and “no”). We can then either pick the label with the higher score, or, for evaluation of our meaning preservation classifier (more below), we take the score of the “yes” class.
In our work on using LLMs to assess meaning preservation, as reported in our original paper, we used a 62B parameter instruction-tuned version of Google’s PaLM language model (called Flan-cont-PaLM), as the base LLM on which then to train the meaning preservation classifier. We evaluated this tuned model on our test set and measured a high AUC ROC (area under the ROC curve) score of 0.9, significantly exceeding other and more traditional approaches to classifiers we had tested.
Meaning preservation assessment with Gemini
While the above reported results on PaLM were encouraging, large improvements in more recent AI models inspired us to assess their applicability to this assessment task. We retrained our meaning preservation classifier, now using Google’s Gemini as an underlying base LLM. There are many use cases that are relevant to this work where the assessment task is best done with a small model (e.g., for on-device applications). Therefore, we chose a small version of Google’s Gemini model (Gemini Nano-1, with 1.8B parameters, as described in detail in the Gemini 1.0 technical report) for more efficient inference, which has fewer than 3% the parameters of the PaLM 62B model that we originally used. Evaluated on our meaning preservation test set, we find the fine-tuned Gemini Nano-1 to be highly competitive, with a AUC ROC score of 0.88, despite its much smaller size.
Multilingual meaning preservation assessment using Gemini
We also created meaning preservation test sets for French and Spanish as part of Project Euphonia’s extended data collection efforts. These test sets helped us investigate the multilingual capabilities of our meaning preservation assessment classifier. These test sets are based on the collected utterances, meta data such as severity and etiology of the speaker’s speech impairment, as well as the true transcript and an ASR transcript obtained from Google’s highly multilingual Universal Speech Model (USM).
For Spanish, the test set consists of 518 examples from six speakers, while the French test set consists of 199 examples from ten speakers. For both languages, different speakers had varying etiologies and levels of speech impairment including mild, moderate, and severe.
Our meaning preservation classifier based on the Gemini Nano-1 model obtains an out-of-the-box performance of about 0.89 ROC AUC on both our French and Spanish test sets. Given that this classifier was only trained with examples for meaning preservation in English, this is a remarkable result. Due to the multilingual capabilities of the underlying Gemini model, these capabilities emerge without having to retrain the model or create training datasets in new languages.
Conclusion
We propose the use of meaning preservation as a more effective metric than WER for evaluating the usefulness of an ASR system, especially in scenarios prone to high error rates, such as atypical speech and other low-resource domains or languages. By focusing on meaning preservation, we can better assess how useful a model would be for individual users, especially when used with assistive technologies like Project Relate, which is designed to enable people with atypical speech to be better understood by training fully personalized speech recognition models.
To further advance our work on meaning preservation and extend its benefits to more users and languages, we have also explored the capabilities of Google’s Gemini model. Gemini Nano-1 allows us to achieve comparable classifier performance for meaning preservation using a significantly smaller model than previously possible. Despite training exclusively on English examples, our classifier demonstrates the ability to generalize and accurately assess meaning preservation in other languages, as tested for French and Spanish. This exciting development opens up new possibilities for building more efficient and versatile models for more users everywhere.
Acknowledgements
We thank and acknowledge the dedicated members of the Project Euphonia team and the speech-language pathologists (SLPs) who have made this research possible. We would like to specifically acknowledge the valuable contributions of Katrin Tomanek, Jimmy Tobin, Subhashini Venugopalan, Julie Cattiau, Richard J.N. Cave, Katie Seaver, Jordan Green, Rus Heywood, Alicia Martín, Marilyn Ladewig, Bob MacDonald and Pan-Pan Jiang.
We also wish to express our appreciation to the International Alliance of ALS/MND Associations as well as the Paris Brain Institute for their unwavering commitment to improving communication for users with atypical speech. Their support has been instrumental in advancing this important work. We would like to especially acknowledge the outstanding contributions of Jessica Mabe, Cathy Cummings, Orlando Ruiz, and Romain Gombert for their exceptional leadership and expertise.
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

June 10, 2026
New framework for auditing machine unlearning- Algorithms & Theory ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention
-

February 5, 2026
How AI tools can redefine universal design to increase accessibility- Education Innovation ·
- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI

Two examples of the representation of the training data using curly braces format. The “input sequence” is also what is fed to the model at inference time, and “target sequence” is what the model has learned to predict.