Announcing YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research
September 28, 2016
Posted by Sudheendra Vijayanarasimhan and Paul Natsev, Software Engineers
Quick links
Many recent breakthroughs in machine learning and machine perception have come from the availability of large labeled datasets, such as ImageNet, which has millions of images labeled with thousands of classes. Their availability has significantly accelerated research in image understanding, for example on detecting and classifying objects in static images.
Video analysis provides even more information for detecting and recognizing objects, and understanding human actions and interactions with the world. Improving video understanding can lead to better video search and discovery, similarly to how image understanding helped re-imagine the photos experience. However, one of the key bottlenecks for further advancements in this area has been the lack of real-world video datasets with the same scale and diversity as image datasets.
Today, we are excited to announce the release of YouTube-8M, a dataset of 8 million YouTube video URLs (representing over 500,000 hours of video), along with video-level labels from a diverse set of 4800 Knowledge Graph entities. This represents a significant increase in scale and diversity compared to existing video datasets. For example, Sports-1M, the largest existing labeled video dataset we are aware of, has around 1 million YouTube videos and 500 sports-specific classes--YouTube-8M represents nearly an order of magnitude increase in both number of videos and classes.

 |
| A dataset explorer allows browsing and searching the full vocabulary of Knowledge Graph entities, grouped in 24 top-level verticals, along with corresponding videos. This screenshot depicts a subset of dataset videos annotated with the entity “Guitar”. |
 |
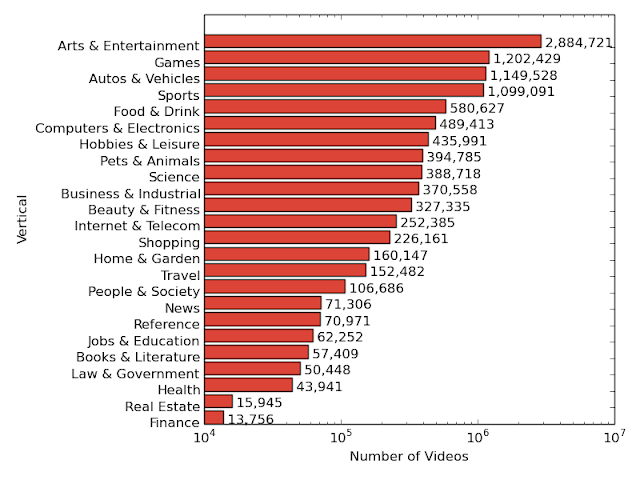
| The distribution of videos in the top-level verticals illustrates the scope and diversity of the dataset and reflects the natural distribution of popular YouTube videos. |
We believe this dataset can significantly accelerate research on video understanding as it enables researchers and students without access to big data or big machines to do their research at previously unprecedented scale. We hope this dataset will spur exciting new research on video modeling architectures and representation learning, especially approaches that deal effectively with noisy or incomplete labels, transfer learning and domain adaptation. In fact, we show that pre-training models on this dataset and applying / fine-tuning on other external datasets leads to state of the art performance on them (e.g. ActivityNet, Sports-1M). You can read all about our experiments using this dataset, along with more details on how we constructed it, in our technical report.
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯