Announcing TensorFlow Fold: Deep Learning With Dynamic Computation Graphs
February 7, 2017
Posted by Moshe Looks, Marcello Herreshoff and DeLesley Hutchins, Software Engineers
Quick links
In much of machine learning, data used for training and inference undergoes a preprocessing step, where multiple inputs (such as images) are scaled to the same dimensions and stacked into batches. This lets high-performance deep learning libraries like TensorFlow run the same computation graph across all the inputs in the batch in parallel. Batching exploits the SIMD capabilities of modern GPUs and multi-core CPUs to speed up execution. However, there are many problem domains where the size and structure of the input data varies, such as parse trees in natural language understanding, abstract syntax trees in source code, DOM trees for web pages and more. In these cases, the different inputs have different computation graphs that don't naturally batch together, resulting in poor processor, memory, and cache utilization.
Today we are releasing TensorFlow Fold to address these challenges. TensorFlow Fold makes it easy to implement deep-learning models that operate over data of varying size and structure. Furthermore, TensorFlow Fold brings the benefits of batching to such models, resulting in a speedup of more than 10x on CPU, and more than 100x on GPU, over alternative implementations. This is made possible by dynamic batching, introduced in our paper Deep Learning with Dynamic Computation Graphs.
 |
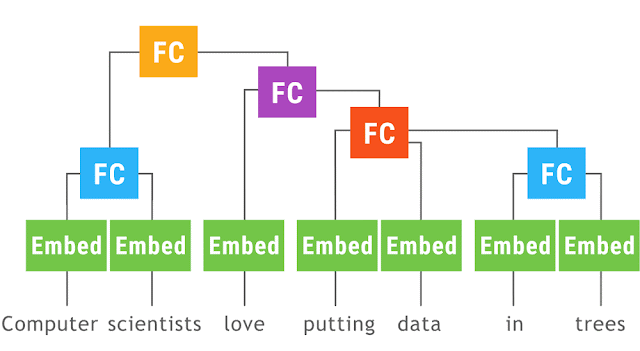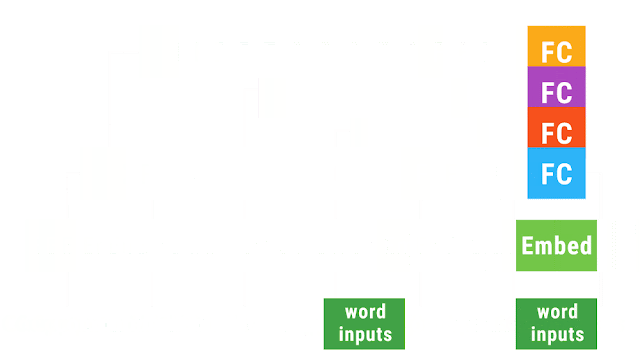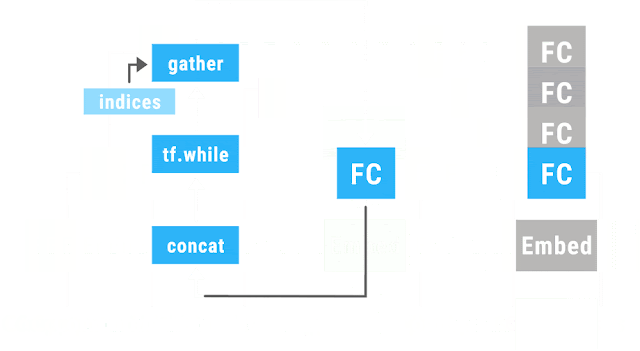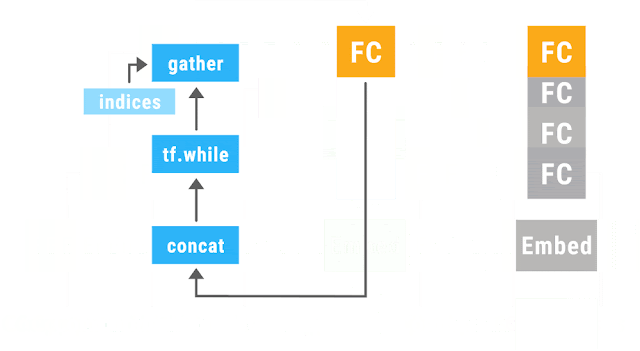
| This animation shows a recursive neural network run with dynamic batching. Operations with the same color are batched together, which lets TensorFlow run them faster. The Embed operation converts words to vector representations. The fully connected (FC) operation combines word vectors to form vector representations of phrases. The output of the network is a vector representation of an entire sentence. Although only a single parse tree of a sentence is shown, the same network can run, and batch together operations, over multiple parse trees of arbitrary shapes and sizes. |
Because the individual inputs may have different sizes and structures, the computation graphs may as well. Dynamic batching then automatically combines these graphs to take advantage of opportunities for batching, both within and across inputs, and inserts additional instructions to move data between the batched operations (see our paper for technical details).
To learn more, head over to our github site. We hope that TensorFlow Fold will be useful for researchers and practitioners implementing neural networks with dynamic computation graphs in TensorFlow.
Acknowledgements
This work was done under the supervision of Peter Norvig.
Quick links
Other posts of interest
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
Where wild things roam: Identifying wildlife with SpeciesNet- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 4, 2026
Teaching LLMs to reason like Bayesians- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
×
❮
❯