Announcing TensorFlow 0.8 – now with distributed computing support!
April 13, 2016
Posted by Derek Murray, Software Engineer
Quick links
Google uses machine learning across a wide range of its products. In order to continually improve our models, it's crucial that the training process be as fast as possible. One way to do this is to run TensorFlow across hundreds of machines, which shortens the training process for some models from weeks to hours, and allows us to experiment with models of increasing size and sophistication. Ever since we released TensorFlow as an open-source project, distributed training support has been one of the most requested features. Now the wait is over.
Today, we're excited to release TensorFlow 0.8 with distributed computing support, including everything you need to train distributed models on your own infrastructure. Distributed TensorFlow is powered by the high-performance gRPC library, which supports training on hundreds of machines in parallel. It complements our recent announcement of Google Cloud Machine Learning, which enables you to train and serve your TensorFlow models using the power of the Google Cloud Platform.
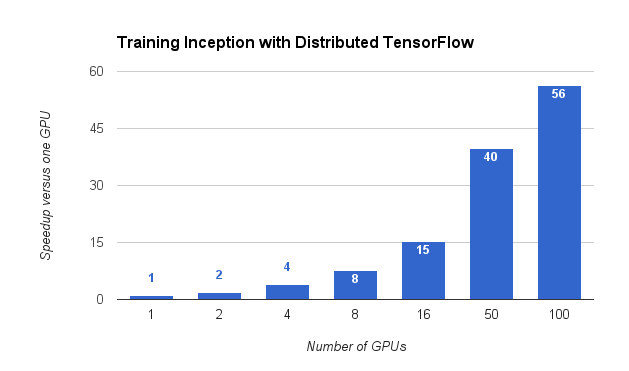
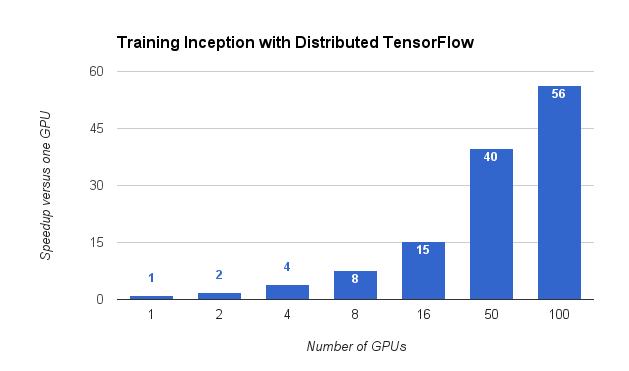
To coincide with the TensorFlow 0.8 release, we have published a distributed trainer for the Inception image classification neural network in the TensorFlow models repository. Using the distributed trainer, we trained the Inception network to 78% accuracy in less than 65 hours using 100 GPUs. Even small clusters—or a couple of machines under your desk—can benefit from distributed TensorFlow, since adding more GPUs improves the overall throughput, and produces accurate results sooner.
 |
| TensorFlow can speed up Inception training by a factor of 56, using 100 GPUs. |
Beyond distributed Inception, the 0.8 release includes new libraries for defining your own distributed models. TensorFlow's distributed architecture permits a great deal of flexibility in defining your model, because every process in the cluster can perform general-purpose computation. Our previous system DistBelief (like many systems that have followed it) used special "parameter servers" to manage the shared model parameters, where the parameter servers had a simple read/write interface for fetching and updating shared parameters. In TensorFlow, all computation—including parameter management—is represented in the dataflow graph, and the system maps the graph onto heterogeneous devices (like multi-core CPUs, general-purpose GPUs, and mobile processors) in the available processes. To make TensorFlow easier to use, we have included Python libraries that make it easy to write a model that runs on a single process and scales to use multiple replicas for training.
This architecture makes it easier to scale a single-process job up to use a cluster, and also to experiment with novel architectures for distributed training. As an example, my colleagues have recently shown that synchronous SGD with backup workers, implemented in the TensorFlow graph, achieves improved time-to-accuracy for image model training.
The current version of distributed computing support in TensorFlow is just the start. We are continuing to research ways of improving the performance of distributed training—both through engineering and algorithmic improvements—and will share these improvements with the community on GitHub. However, getting to this point would not have been possible without help from the following people:
- TensorFlow training libraries - Jianmin Chen, Matthieu Devin, Sherry Moore and Sergio Guadarrama
- TensorFlow core - Zhifeng Chen, Manjunath Kudlur and Vijay Vasudevan
- Testing - Shanqing Cai
- Inception model architecture - Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Jonathon Shlens and Zbigniew Wojna
- Project management - Amy McDonald Sandjideh
- Engineering leadership - Jeff Dean and Rajat Monga
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯