An open-source gymnasium for machine learning assisted computer architecture design
July 11, 2023
Posted by Amir Yazdanbakhsh, Research Scientist, and Vijay Janapa Reddi, Visiting Researcher, Google Research
Quick links
Computer Architecture research has a long history of developing simulators and tools to evaluate and shape the design of computer systems. For example, the SimpleScalar simulator was introduced in the late 1990s and allowed researchers to explore various microarchitectural ideas. Computer architecture simulators and tools, such as gem5, DRAMSys, and many more have played a significant role in advancing computer architecture research. Since then, these shared resources and infrastructure have benefited industry and academia and have enabled researchers to systematically build on each other's work, leading to significant advances in the field.
Nonetheless, computer architecture research is evolving, with industry and academia turning towards machine learning (ML) optimization to meet stringent domain-specific requirements, such as ML for computer architecture, ML for TinyML acceleration, DNN accelerator datapath optimization, memory controllers, power consumption, security, and privacy. Although prior work has demonstrated the benefits of ML in design optimization, the lack of strong, reproducible baselines hinders fair and objective comparison across different methods and poses several challenges to their deployment. To ensure steady progress, it is imperative to understand and tackle these challenges collectively.
To alleviate these challenges, in “ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design”, accepted at ISCA 2023, we introduced ArchGym, which includes a variety of computer architecture simulators and ML algorithms. Enabled by ArchGym, our results indicate that with a sufficiently large number of samples, any of a diverse collection of ML algorithms are capable of finding the optimal set of architecture design parameters for each target problem; no one solution is necessarily better than another. These results further indicate that selecting the optimal hyperparameters for a given ML algorithm is essential for finding the optimal architecture design, but choosing them is non-trivial. We release the code and dataset across multiple computer architecture simulations and ML algorithms.
Challenges in ML-assisted architecture research
ML-assisted architecture research poses several challenges, including:
- For a specific ML-assisted computer architecture problem (e.g., finding an optimal solution for a DRAM controller) there is no systematic way to identify optimal ML algorithms or hyperparameters (e.g., learning rate, warm-up steps, etc.). There is a wider range of ML and heuristic methods, from random walk to reinforcement learning (RL), that can be employed for design space exploration (DSE). While these methods have shown noticeable performance improvement over their choice of baselines, it is not evident whether the improvements are because of the choice of optimization algorithms or hyperparameters.
Thus, to ensure reproducibility and facilitate widespread adoption of ML-aided architecture DSE, it is necessary to outline a systematic benchmarking methodology.
- While computer architecture simulators have been the backbone of architectural innovations, there is an emerging need to address the trade-offs between accuracy, speed, and cost in architecture exploration. The accuracy and speed of performance estimation widely varies from one simulator to another, depending on the underlying modeling details (e.g., cycle-accurate vs. ML-based proxy models). While analytical or ML-based proxy models are nimble by virtue of discarding low-level details, they generally suffer from high prediction error. Also, due to commercial licensing, there can be strict limits on the number of runs collected from a simulator. Overall, these constraints exhibit distinct performance vs. sample efficiency trade-offs, affecting the choice of optimization algorithm for architecture exploration.
It is challenging to delineate how to systematically compare the effectiveness of various ML algorithms under these constraints.
- Finally, the landscape of ML algorithms is rapidly evolving and some ML algorithms need data to be useful. Additionally, rendering the outcome of DSE into meaningful artifacts such as datasets is critical for drawing insights about the design space.
In this rapidly evolving ecosystem, it is consequential to ensure how to amortize the overhead of search algorithms for architecture exploration. It is not apparent, nor systematically studied how to leverage exploration data while being agnostic to the underlying search algorithm.
ArchGym design
ArchGym addresses these challenges by providing a unified framework for evaluating different ML-based search algorithms fairly. It comprises two main components: 1) the ArchGym environment and 2) the ArchGym agent. The environment is an encapsulation of the architecture cost model — which includes latency, throughput, area, energy, etc., to determine the computational cost of running the workload, given a set of architectural parameters — paired with the target workload(s). The agent is an encapsulation of the ML algorithm used for the search and consists of hyperparameters and a guiding policy. The hyperparameters are intrinsic to the algorithm for which the model is to be optimized and can significantly influence performance. The policy, on the other hand, determines how the agent selects a parameter iteratively to optimize the target objective.
Notably, ArchGym also includes a standardized interface that connects these two components, while also saving the exploration data as the ArchGym Dataset. At its core, the interface entails three main signals: hardware state, hardware parameters, and metrics. These signals are the bare minimum to establish a meaningful communication channel between the environment and the agent. Using these signals, the agent observes the state of the hardware and suggests a set of hardware parameters to iteratively optimize a (user-defined) reward. The reward is a function of hardware performance metrics, such as performance, energy consumption, etc.
 |
| ArchGym comprises two main components: the ArchGym environment and the ArchGym agent. The ArchGym environment encapsulates the cost model and the agent is an abstraction of a policy and hyperparameters. With a standardized interface that connects these two components, ArchGym provides a unified framework for evaluating different ML-based search algorithms fairly while also saving the exploration data as the ArchGym Dataset. |
ML algorithms could be equally favorable to meet user-defined target specifications
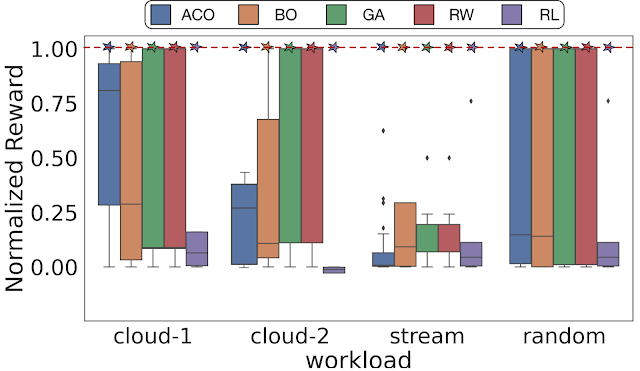
Using ArchGym, we empirically demonstrate that across different optimization objectives and DSE problems, at least one set of hyperparameters exists that results in the same hardware performance as other ML algorithms. A poorly selected (random selection) hyperparameter for the ML algorithm or its baseline can lead to a misleading conclusion that a particular family of ML algorithms is better than another. We show that with sufficient hyperparameter tuning, different search algorithms, even random walk (RW), are able to identify the best possible reward. However, note that finding the right set of hyperparameters may require exhaustive search or even luck to make it competitive.
 |
| With a sufficient number of samples, there exists at least one set of hyperparameters that results in the same performance across a range of search algorithms. Here the dashed line represents the maximum normalized reward. Cloud-1, cloud-2, stream, and random indicate four different memory traces for DRAMSys (DRAM subsystem design space exploration framework). |
Dataset construction and high-fidelity proxy model training
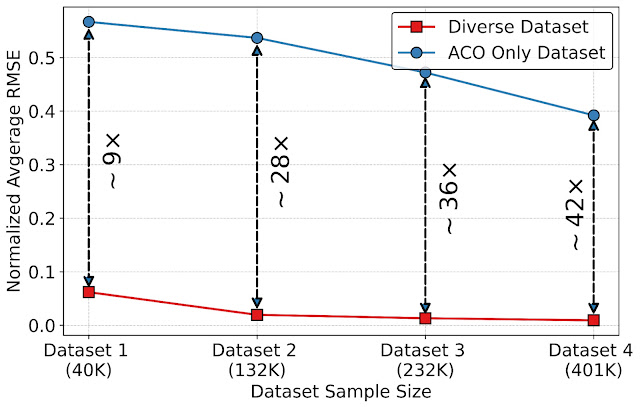
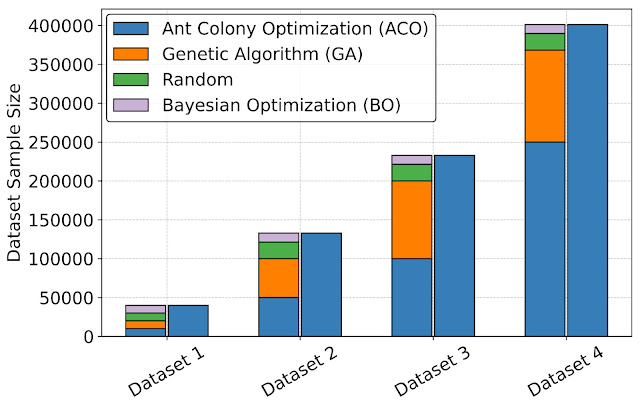
Creating a unified interface using ArchGym also enables the creation of datasets that can be used to design better data-driven ML-based proxy architecture cost models to improve the speed of architecture simulation. To evaluate the benefits of datasets in building an ML model to approximate architecture cost, we leverage ArchGym’s ability to log the data from each run from DRAMSys to create four dataset variants, each with a different number of data points. For each variant, we create two categories: (a) Diverse Dataset, which represents the data collected from different agents (ACO, GA, RW, and BO), and (b) ACO only, which shows the data collected exclusively from the ACO agent, both of which are released along with ArchGym. We train a proxy model on each dataset using random forest regression with the objective to predict the latency of designs for a DRAM simulator. Our results show that:
- As we increase the dataset size, the average normalized root mean squared error (RMSE) slightly decreases.
- However, as we introduce diversity in the dataset (e.g., collecting data from different agents), we observe 9× to 42× lower RMSE across different dataset sizes.
 |
| Diverse dataset collection across different agents using ArchGym interface. |
 |
| The impact of a diverse dataset and dataset size on the normalized RMSE. |
The need for a community-driven ecosystem for ML-assisted architecture research
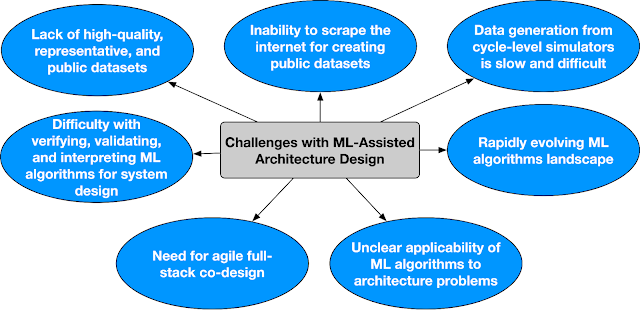
While, ArchGym is an initial effort towards creating an open-source ecosystem that (1) connects a broad range of search algorithms to computer architecture simulators in an unified and easy-to-extend manner, (2) facilitates research in ML-assisted computer architecture, and (3) forms the scaffold to develop reproducible baselines, there are a lot of open challenges that need community-wide support. Below we outline some of the open challenges in ML-assisted architecture design. Addressing these challenges requires a well coordinated effort and a community driven ecosystem.
 |
| Key challenges in ML-assisted architecture design. |
We call this ecosystem Architecture 2.0. We outline the key challenges and a vision for building an inclusive ecosystem of interdisciplinary researchers to tackle the long-standing open problems in applying ML for computer architecture research. If you are interested in helping shape this ecosystem, please fill out the interest survey.
Conclusion
ArchGym is an open source gymnasium for ML architecture DSE and enables an standardized interface that can be readily extended to suit different use cases. Additionally, ArchGym enables fair and reproducible comparison between different ML algorithms and helps to establish stronger baselines for computer architecture research problems.
We invite the computer architecture community as well as the ML community to actively participate in the development of ArchGym. We believe that the creation of a gymnasium-type environment for computer architecture research would be a significant step forward in the field and provide a platform for researchers to use ML to accelerate research and lead to new and innovative designs.
Acknowledgements
This blogpost is based on joint work with several co-authors at Google and Harvard University. We would like to acknowledge and highlight Srivatsan Krishnan (Harvard) who contributed several ideas to this project in collaboration with Shvetank Prakash (Harvard), Jason Jabbour (Harvard), Ikechukwu Uchendu (Harvard), Susobhan Ghosh (Harvard), Behzad Boroujerdian (Harvard), Daniel Richins (Harvard), Devashree Tripathy (Harvard), and Thierry Thambe (Harvard). In addition, we would also like to thank James Laudon, Douglas Eck, Cliff Young, and Aleksandra Faust for their support, feedback, and motivation for this work. We would also like to thank John Guilyard for the animated figure used in this post. Amir Yazdanbakhsh is now a Research Scientist at Google DeepMind and Vijay Janapa Reddi is an Associate Professor at Harvard.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence