AlphaGo: Mastering the ancient game of Go with Machine Learning
January 27, 2016
Posted by David Silver and Demis Hassabis, Google DeepMind
Quick links
Games are a great testing ground for developing smarter, more flexible algorithms that have the ability to tackle problems in ways similar to humans. Creating programs that are able to play games better than the best humans has a long history - the first classic game mastered by a computer was noughts and crosses (also known as tic-tac-toe) in 1952 as a PhD candidate’s project. Then fell checkers in 1994. Chess was tackled by Deep Blue in 1997. The success isn’t limited to board games, either - IBM's Watson won first place on Jeopardy in 2011, and in 2014 our own algorithms learned to play dozens of Atari games just from the raw pixel inputs.
But one game has thwarted A.I. research thus far: the ancient game of Go. Invented in China over 2500 years ago, Go is played by more than 40 million people worldwide. The rules are simple: players take turns to place black or white stones on a board, trying to capture the opponent's stones or surround empty space to make points of territory. Confucius wrote about the game, and its aesthetic beauty elevated it to one of the four essential arts required of any true Chinese scholar. The game is played primarily through intuition and feel, and because of its subtlety and intellectual depth it has captured the human imagination for centuries.
But as simple as the rules are, Go is a game of profound complexity. The search space in Go is vast -- more than a googol times larger than chess (a number greater than there are atoms in the universe!). As a result, traditional “brute force” AI methods -- which construct a search tree over all possible sequences of moves -- don’t have a chance in Go. To date, computers have played Go only as well as amateurs. Experts predicted it would be at least another 10 years until a computer could beat one of the world’s elite group of Go professionals.
We saw this as an irresistible challenge! We started building a system, AlphaGo, described in a paper in Nature this week, that would overcome these barriers. The key to AlphaGo is reducing the enormous search space to something more manageable. To do this, it combines a state-of-the-art tree search with two deep neural networks, each of which contains many layers with millions of neuron-like connections. One neural network, the “policy network”, predicts the next move, and is used to narrow the search to consider only the moves most likely to lead to a win. The other neural network, the “value network”, is then used to reduce the depth of the search tree -- estimating the winner in each position in place of searching all the way to the end of the game.
AlphaGo’s search algorithm is much more human-like than previous approaches. For example, when Deep Blue played chess, it searched by brute force over thousands of times more positions than AlphaGo. Instead, AlphaGo looks ahead by playing out the remainder of the game in its imagination, many times over - a technique known as Monte-Carlo tree search. But unlike previous Monte-Carlo programs, AlphaGo uses deep neural networks to guide its search. During each simulated game, the policy network suggests intelligent moves to play, while the value network astutely evaluates the position that is reached. Finally, AlphaGo chooses the move that is most successful in simulation.
We first trained the policy network on 30 million moves from games played by human experts, until it could predict the human move 57% of the time (the previous record before AlphaGo was 44%). But our goal is to beat the best human players, not just mimic them. To do this, AlphaGo learned to discover new strategies for itself, by playing thousands of games between its neural networks, and gradually improving them using a trial-and-error process known as reinforcement learning. This approach led to much better policy networks, so strong in fact that the raw neural network (immediately, without any tree search at all) can defeat state-of-the-art Go programs that build enormous search trees.
These policy networks were in turn used to train the value networks, again by reinforcement learning from games of self-play. These value networks can evaluate any Go position and estimate the eventual winner - a problem so hard it was believed to be impossible.
Of course, all of this requires a huge amount of compute power, so we made extensive use of Google Cloud Platform, which enables researchers working on AI and Machine Learning to access elastic compute, storage and networking capacity on demand. In addition, new open source libraries for numerical computation using data flow graphs, such as TensorFlow, allow researchers to efficiently deploy the computation needed for deep learning algorithms across multiple CPUs or GPUs.
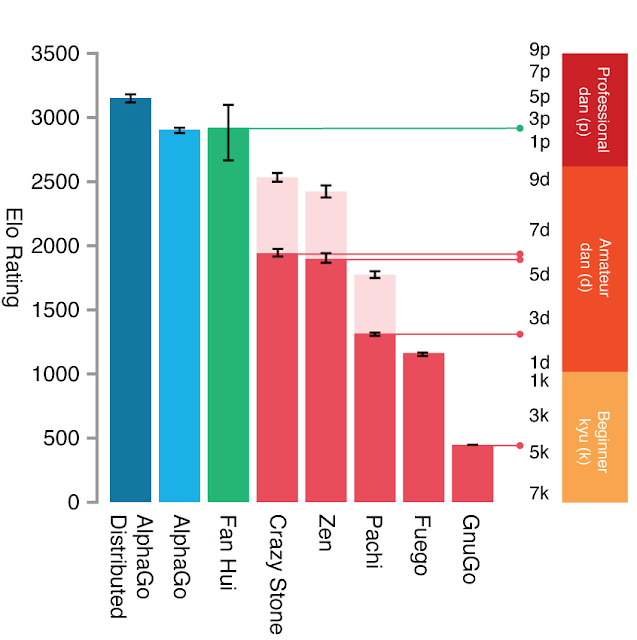
So how strong is AlphaGo? To answer this question, we played a tournament between AlphaGo and the best of the rest - the top Go programs at the forefront of A.I. research. Using a single machine, AlphaGo won all but one of its 500 games against these programs. In fact, AlphaGo even beat those programs after giving them 4 free moves headstart at the beginning of each game. A high-performance version of AlphaGo, distributed across many machines, was even stronger.
 |
| This figure from the Nature article shows the Elo rating and approximate rank of AlphaGo (both single machine and distributed versions), the European champion Fan Hui (a professional 2-dan), and the strongest other Go programs, evaluated over thousands of games. Pale pink bars show the performance of other programs when given a four move headstart. |
AlphaGo’s next challenge will be to play the top Go player in the world over the last decade, Lee Sedol. The match will take place this March in Seoul, South Korea. Lee Sedol is excited to take on the challenge saying, "I am privileged to be the one to play, but I am confident that I can win." It should prove to be a fascinating contest!
We are thrilled to have mastered Go and thus achieved one of the grand challenges of AI. However, the most significant aspect of all this for us is that AlphaGo isn’t just an ‘expert’ system built with hand-crafted rules, but instead uses general machine learning techniques to allow it to improve itself, just by watching and playing games. While games are the perfect platform for developing and testing AI algorithms quickly and efficiently, ultimately we want to apply these techniques to important real-world problems. Because the methods we have used are general purpose, our hope is that one day they could be extended to help us address some of society’s toughest and most pressing problems, from climate modelling to complex disease analysis.
-
Labels:
- Machine Intelligence
Quick links
Other posts of interest
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
×
❮
❯
