ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
December 20, 2019
Posted by Radu Soricut and Zhenzhong Lan, Research Scientists, Google Research
Quick links
Ever since the advent of BERT a year ago, natural language research has embraced a new paradigm, leveraging large amounts of existing text to pretrain a model’s parameters using self-supervision, with no data annotation required. So, rather than needing to train a machine-learning model for natural language processing (NLP) from scratch, one can start from a model primed with knowledge of a language. But, in order to improve upon this new approach to NLP, one must develop an understanding of what, exactly, is contributing to language-understanding performance — the network’s height (i.e., number of layers), its width (size of the hidden layer representations), the learning criteria for self-supervision, or something else entirely?
In “ALBERT: A Lite BERT for Self-supervised Learning of Language Representations”, accepted at ICLR 2020, we present an upgrade to BERT that advances the state-of-the-art performance on 12 NLP tasks, including the competitive Stanford Question Answering Dataset (SQuAD v2.0) and the SAT-style reading comprehension RACE benchmark. ALBERT is being released as an open-source implementation on top of TensorFlow, and includes a number of ready-to-use ALBERT pre-trained language representation models.
What Contributes to NLP Performance?
Identifying the dominant driver of NLP performance is complex — some settings are more important than others, and, as our study reveals, a simple, one-at-a-time exploration of these settings would not yield the correct answers.
The key to optimizing performance, captured in the design of ALBERT, is to allocate the model’s capacity more efficiently. Input-level embeddings (words, sub-tokens, etc.) need to learn context-independent representations, a representation for the word “bank”, for example. In contrast, hidden-layer embeddings need to refine that into context-dependent representations, e.g., a representation for “bank” in the context of financial transactions, and a different representation for “bank” in the context of river-flow management.
This is achieved by factorization of the embedding parametrization — the embedding matrix is split between input-level embeddings with a relatively-low dimension (e.g., 128), while the hidden-layer embeddings use higher dimensionalities (768 as in the BERT case, or more). With this step alone, ALBERT achieves an 80% reduction in the parameters of the projection block, at the expense of only a minor drop in performance — 80.3 SQuAD2.0 score, down from 80.4; or 67.9 on RACE, down from 68.2 — with all other conditions the same as for BERT.
Another critical design decision for ALBERT stems from a different observation that examines redundancy. Transformer-based neural network architectures (such as BERT, XLNet, and RoBERTa) rely on independent layers stacked on top of each other. However, we observed that the network often learned to perform similar operations at various layers, using different parameters of the network. This possible redundancy is eliminated in ALBERT by parameter-sharing across the layers, i.e., the same layer is applied on top of each other. This approach slightly diminishes the accuracy, but the more compact size is well worth the tradeoff. Parameter sharing achieves a 90% parameter reduction for the attention-feedforward block (a 70% reduction overall), which, when applied in addition to the factorization of the embedding parameterization, incur a slight performance drop of -0.3 on SQuAD2.0 to 80.0, and a larger drop of -3.9 on RACE score to 64.0.
Implementing these two design changes together yields an ALBERT-base model that has only 12M parameters, an 89% parameter reduction compared to the BERT-base model, yet still achieves respectable performance across the benchmarks considered. But this parameter-size reduction provides the opportunity to scale up the model again. Assuming that memory size allows, one can scale up the size of the hidden-layer embeddings by 10-20x. With a hidden-size of 4096, the ALBERT-xxlarge configuration achieves both an overall 30% parameter reduction compared to the BERT-large model, and, more importantly, significant performance gains: +4.2 on SQuAD2.0 (88.1, up from 83.9), and +8.5 on RACE (82.3, up from 73.8).
These results indicate that accurate language understanding depends on developing robust, high-capacity contextual representations. The context, modeled in the hidden-layer embeddings, captures the meaning of the words, which in turn drives the overall understanding, as directly measured by model performance on standard benchmarks.
Optimized Model Performance with the RACE Dataset
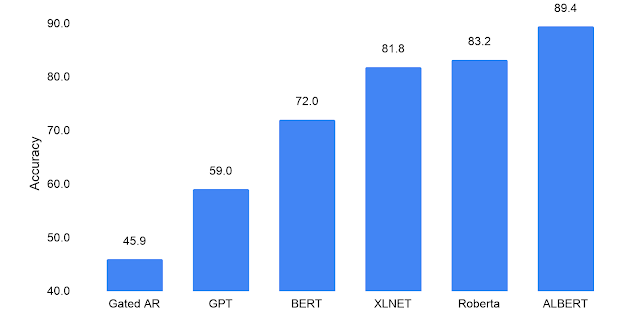
To evaluate the language understanding capability of a model, one can administer a reading comprehension test (e.g., similar to the SAT Reading Test). This can be done with the RACE dataset (2017), the largest publicly available resource for this purpose. Computer performance on this reading comprehension challenge mirrors well the language modeling advances of the last few years: a model pre-trained with only context-independent word representations scores poorly on this test (45.9; left-most bar), while BERT, with context-dependent language knowledge, scores relatively well with a 72.0. Refined BERT models, such as XLNet and RoBERTa, set the bar even higher, in the 82-83 score range. The ALBERT-xxlarge configuration mentioned above yields a RACE score in the same range (82.3), when trained on the base BERT dataset (Wikipedia and Books). However, when trained on the same larger dataset as XLNet and RoBERTa, it significantly outperforms all other approaches to date, and establishes a new state-of-the-art score at 89.4.
 |
| Machine performance on the RACE challenge (SAT-like reading comprehension). A random-guess baseline score is 25.0. The maximum possible score is 95.0. |
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯