AfriMed-QA: Benchmarking large language models for global health
September 24, 2025
Mercy Asiedu, Senior Research Scientist, Google Research
We present Afrimed-QA, a collection of contextually relevant datasets for evaluation of LLMs on African health question answering tasks, developed in partnership with organizations across Africa.
Quick links
Large language models (LLMs) have shown potential for medical and health question answering across various health-related tests spanning different formats and sources, such as multiple choice and short answer exam questions (e.g., USMLE MedQA), summarization, and clinical note taking, among others. Especially in low-resource settings, LLMs can potentially serve as valuable decision-support tools, enhancing clinical diagnostic accuracy and accessibility, and providing multilingual clinical decision support and health training, all of which are especially valuable at the community level.
Despite their success on existing medical benchmarks, there is uncertainty about whether these models generalize to tasks involving distribution shifts in disease types, contextual differences across symptoms, or variations in language and linguistics, even within English. Further, localized cultural contexts and region-specific medical knowledge is important for models deployed outside of traditional Western settings. Yet without diverse benchmark datasets that reflect the breadth of real-world contexts, it’s impossible to train or evaluate models in these settings, highlighting the need for more diverse benchmark datasets.
To address this gap, we present AfriMed-QA, a benchmark question–answer dataset that brings together consumer-style questions and medical school–type exams from 60 medical schools, across 16 countries in Africa. We developed the dataset in collaboration with numerous partners, including Intron health, Sisonkebiotik, University of Cape Coast, the Federation of African Medical Students Association, and BioRAMP, which collectively form the AfriMed-QA consortium, and with support from PATH/The Gates Foundation. We evaluated LLM responses on these datasets, comparing them to answers provided by human experts and rating their responses according to human preference. The methods used in this project can be scaled to other locales where digitized benchmarks may not currently be available.
AfriMed-QA was published at ACL 2025 where it won the Best Social Impact Paper Award. The dataset was recently leveraged to assist in training of MedGemma, our latest open model for multimodal medical text and image comprehension. The AfriMed-QA benchmark datasets and LLM evaluation code are open-sourced and available for use by the community.
AfriMed-QA dataset
The AfriMed-QA dataset is the first large-scale pan-African multi-specialty medical question–answer dataset designed to evaluate and develop equitable and effective LLMs for African healthcare. The dataset comprises ~15,000 clinically diverse questions and answers in English, 4,000+ expert multiple choice questions (MCQs) with answers, over 1,200 open ended short answer (SAQs) with long-form answers, and 10,000 consumer queries (CQ). The dataset is designed to rigorously assess LLM performance for correctness and geographical shifts. It was crowd-sourced from 621 contributors, from over 60 medical schools across 12 countries, covering 32 medical specialties, including obstetrics and gynecology, neurosurgery, internal medicine, emergency medicine, medical genetics, infectious disease, and others.
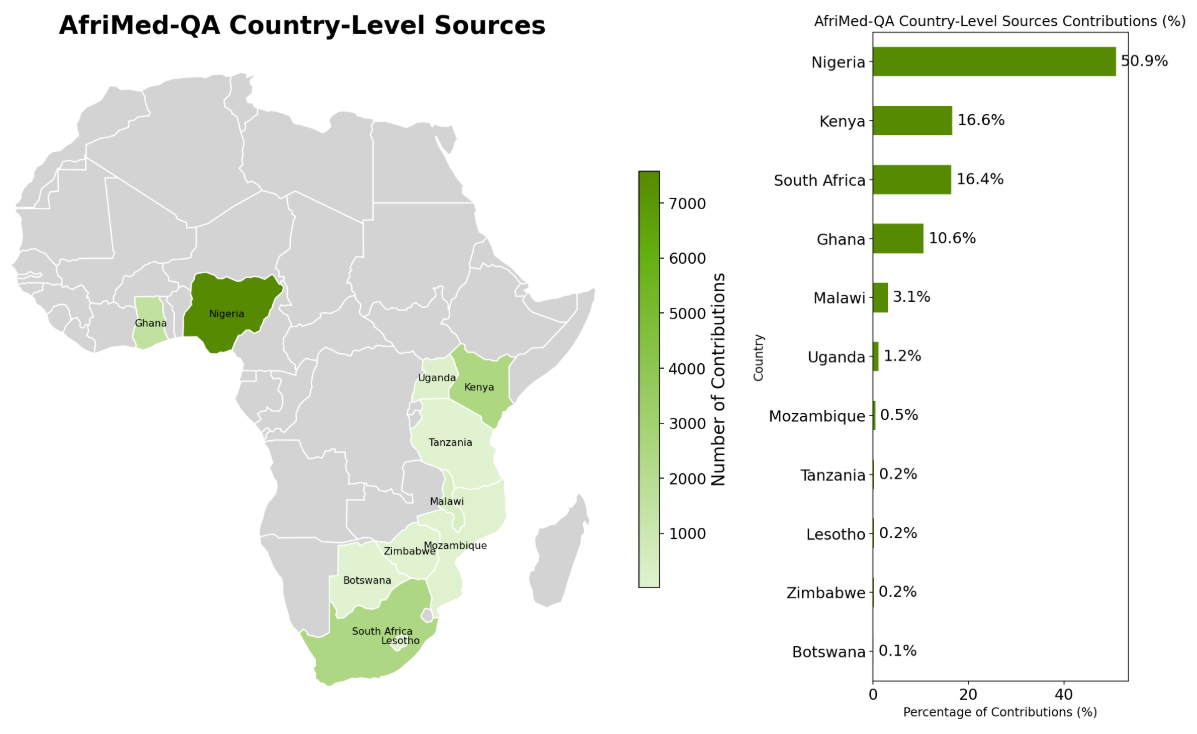
Countries where AfriMed-QA questions and answers were sourced.
To collect these data, we adapted a web-based platform previously developed by Intron Health for crowd-sourcing accented and multilingual clinical speech data at scale across Africa. We developed custom user interfaces to collect each question type, for quality reviews, and for blinded human evaluation of LLM responses.

AfriMed-QA dataset curation and LLM evaluation overview. MCQs and SAQs from medical schools had accompanying human labels. For CQs, to avoid consumers sharing their own health information which might lead to potential disclosure of health information, and repetitiveness in question types, consumers were prompted with a disease scenario, and they responded with a question they would ask based on it. The scenario and question were passed to an LLM and the LLM responses were rated by human clinical experts as well as consumers.

Medical specialties represented in AfriMed-QA.
Evaluation of LLM responses
Using quantitative and qualitative approaches, we evaluated 30 general and biomedical LLMs, ranging in size from small to large. Some were open and others were closed. For MCQs, we measured the accuracy by comparing each LLM’s single-letter answer choice with the reference. For SAQs, we measured semantic similarity and sentence level overlap comparing the generated response from the language model against a reference answer.
We found that the baseline performance of larger models is more accurate than small models on AfriMed-QA. This trend may be unfavorable to low-resource settings where on-device or edge deployments with smaller specialized models are preferred.

Performance of LLM models on the AfriMed-QA dataset (experiments as of May 2025).
We also found that baseline general models outperform and generalize better than biomedical models of similar size. This counterintuitive result could be due to the parameter size limitations of open biomedical models in our study or it could indicate that specialized LLMs overfit to the specific biases and nuances of the data on which they are fine-tuned. In either case, they seem to be less adaptable to the unique characteristics of the AfriMed-QA dataset.
Human rating of LLM responses
LLM responses to a fixed subset of questions (n=3000; randomly sampled) were sent out for human evaluation on the Intron Health crowd-sourcing platform. Adapting the evaluation axes described in our MedLM paper, which included measures for inaccuracy, omission of information, evidence of demographic bias, and extent of harm, we collected human evaluations in two categories:
- Clinicians provided ratings to the LLM’s MCQ, SAQ, and CQ responses, evaluating whether answers were correct and localized, if omissions or hallucinations were present, and if potential for harm existed.
- Non-clinicians/consumers rated CQ LLM responses to determine if answers were relevant, helpful, and localized.
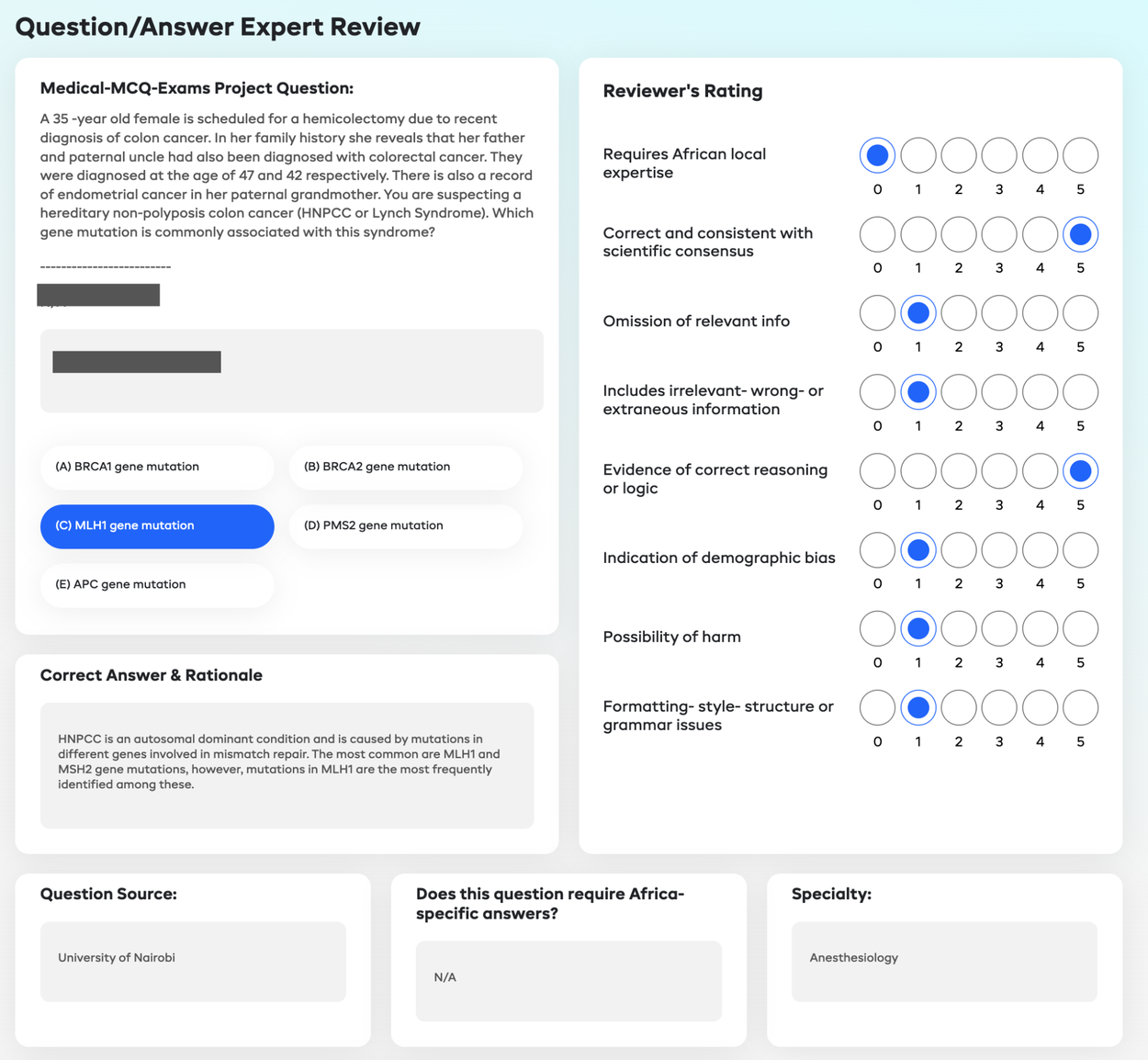
Interface used for expert review of LLM responses to AfriMed-QA.
Ratings were on a 5-point scale representing the extent to which the criteria were met. “1” represents “No" or “completely absent" and “5” represents “Yes" or “absolutely present". Raters were blinded to the answer source (model name or human) and each rater was asked to evaluate answers from multiple LLMs in a random sequence.
Consumer and clinician human evaluation of LLM answers to CQs revealed a preference for LLM responses, where frontier LLMs were consistently rated to be more complete, informative, and relevant when compared with clinician-provided answers, and less susceptible to hallucinations and omissions. Consistent with this, clinician answers to CQs were also rated worse when measured for omission of relevant information.

Consumer blinded evaluations of human clinical experts and LLM answers. Plots show mean ratings and confidence intervals across various axes.
Building an open Leaderboard for easy comparison of data versions and LLM versions
We have developed a leaderboard for easy visualization and comparison of LLM performance. Users can compare existing models or submit their own models and see how well they perform on the dataset.

AfriMed-QA leaderboard enables comparison of different models across different benchmark metrics.
Towards a multilingual, multimodal dataset
We recognize that medicine is inherently multilingual and multimodal and are currently working with the AfriMed-QA consortium led by Prof. Stephen Moore at the University of Cape Coast to expand beyond English-only text-based question answering to non-English official and native languages from the continent. We are also working to incorporate multimodal (e.g., visual and audio) question answering datasets.
Limitations
Although this is the first large-scale, multi-specialty, indigenously sourced pan-African dataset of its kind, it is by no means complete. Over 50% of the expert MCQ questions came from Nigeria. We are working to expand representation from more African regions and the Global South.
While the development of the dataset is still in progress, this work establishes a foundation for acquiring diverse and representative health benchmark datasets across countries that may not have digitized and readily available benchmark datasets.
LLMs for geographically diverse health QAs
Given the sensitivity of health-related outcomes, it is essential that LLMs are evaluated for accurate, contextual, and culturally relevant performance. Across different settings one can anticipate a variety of distribution shifts to which LLMs need to adapt. These include disease prevalence, cultural context, resources and infrastructure, drug types and nomenclature, differences in health recommendations for screening and treatment, medical technology infrastructure, affordability, care types, and sensitive attributes. While our evaluations are limited, we present a call to action for other research and health organizations to pursue further research in this area, curating datasets to evaluate and optimize LLMs for use in their contexts through partnerships and local input.
Acknowledgements
We would like to acknowledge the incredible AfriMed-QA consortium and co-authors. Tobi Olatunji, Charles Nimo, Abraham Owodunni, Tassallah Abdullahi, Emmanuel Ayodele, Mardhiyah Sanni, Chinemelu Aka, Folafunmi Omofoye, Foutse Yuehgoh, Timothy Faniran, Bonaventure F. P. Dossou, Moshood Yekini, Jonas Kemp, Katherine Heller, Jude Chidubem Omeke, Chidi Asuzu, Naome A. Etori, Aimérou Ndiaye, Ifeoma Okoh, Evans Doe Ocansey, Wendy Kinara, Michael Best, Irfan Essa, Stephen Edward Moore, and Chris Fourie. We would also like to thank Bilal Mateen, Melissa Miles, Mira Emmanuel-Fabula, and Celeste Gonda from the Gates Foundation/PATH Digital Square for their support of the work and all data contributors. Finally, we thank Marian Croak for her leadership and support.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence






