Advances in Semantic Textual Similarity
May 17, 2018
Posted by Yinfei Yang, Software Engineer and Chris Tar, Engineering Manager, Google AI
Quick links
The recent rapid progress of neural network-based natural language understanding research, especially on learning semantic text representations, can enable truly novel products such as Smart Compose and Talk to Books. It can also help improve performance on a variety of natural language tasks which have limited amounts of training data, such as building strong text classifiers from as few as 100 labeled examples.
Below, we discuss two papers reporting recent progress on semantic representation research at Google, as well as two new models available for download on TensorFlow Hub that we hope developers will use to build new and exciting applications.
Semantic Textual Similarity
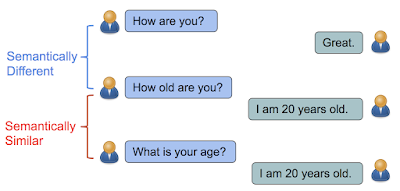
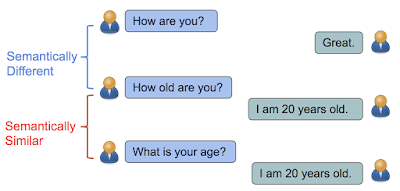
In “Learning Semantic Textual Similarity from Conversations”, we introduce a new way to learn sentence representations for semantic textual similarity. The intuition is that sentences are semantically similar if they have a similar distribution of responses. For example, “How old are you?” and “What is your age?” are both questions about age, which can be answered by similar responses such as “I am 20 years old”. In contrast, while “How are you?” and “How old are you?” contain almost identical words, they have very different meanings and lead to different responses.
 |
| Sentences are semantically similar if they can be answered by the same responses. Otherwise, they are semantically different. |
 |
| For a given input, classification is considered a ranking problem against potential candidates. |
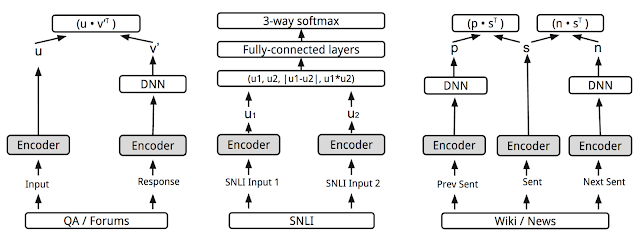
In “Universal Sentence Encoder”, we introduce a model that extends the multitask training described above by adding more tasks, jointly training them with a skip-thought-like model that predicts sentences surrounding a given selection of text. However, instead of the encoder-decoder architecture in the original skip-thought model, we make use of an encode-only architecture by way of a shared encoder to drive the prediction tasks. In this way, training time is greatly reduced while preserving the performance on a variety of transfer tasks including sentiment and semantic similarity classification. The aim is to provide a single encoder that can support as wide a variety of applications as possible, including paraphrase detection, relatedness, clustering and custom text classification.
 |
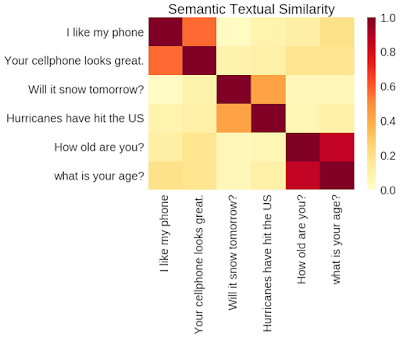
| Pairwise semantic similarity comparison via outputs from TensorFlow Hub Universal Sentence Encoder. |
 |
| Multi-task training as described in “Universal Sentence Encoder”. A variety of tasks and task structures are joined by shared encoder layers/parameters (grey boxes). |
New Models
In addition to the Universal Sentence Encoder model described above, we are also sharing two new models on TensorFlow Hub: the Universal Sentence Encoder - Large and Universal Sentence Encoder - Lite. These are pretrained Tensorflow models that return a semantic encoding for variable-length text inputs. The encodings can be used for semantic similarity measurement, relatedness, classification, or clustering of natural language text.
- The Large model is trained with the Transformer encoder described in our second paper. It targets scenarios requiring high precision semantic representations and the best model performance at the cost of speed & size.
- The Lite model is trained on a Sentence Piece vocabulary instead of words in order to significantly reduce the vocabulary size, which is a major contributor of model size. It targets scenarios where resources like memory and CPU are limited, such as on-device or browser based implementations.
Acknowledgements
Daniel Cer, Mario Guajardo-Cespedes, Sheng-Yi Kong, Noah Constant for training the models, Nan Hua, Nicole Limtiaco, Rhomni St. John for transferring tasks, Steve Yuan, Yunhsuan Sung, Brian Strope, Ray Kurzweil for discussion of the model architecture. Special thanks to Sheng-Yi Kong and Noah Constant for training the Lite model.
Quick links
Other posts of interest
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯