A scalable framework for evaluating health language models
August 26, 2025
Ahmed A. Metwally and Daniel McDuff, Staff Research Scientists, Google Research
Evaluation of language models in complex domains (such as health) can be expensive and labor intensive. We present a new adaptive and precise rubric methodology that saves time and increases inter-rater reliability compared to existing protocols.
Quick links
Large language models can be used to analyze and interpret complex data. Our previous work has shown how they can be used to generate useful, personalized responses when provided with user-specific health information that encompasses lifestyle, biomarkers, and context. Rigorous and efficient evaluation methodologies are crucial to ensure the accuracy, precision, relevance, and safety of responses. However, current evaluation practices heavily rely on human experts, meaning they are cost-prohibitive, labor-intensive, and not scalable. Furthermore, tasks involving human judgement often require careful design to avoid biases and low inter-rater consistency.
With the above in mind, in “A Scalable Framework for Evaluating Health Language Models”, published in njp Digital Medicine, we introduce an evaluation framework that aims to streamline human and automated evaluation of open questions. Our method helps identify critical gaps in model responses using a minimal set of targeted rubric questions that break complex, multi-faceted evaluation questions into granular evaluation targets that can be answered via simple boolean responses. Specifically, we introduce Adaptive Precise Boolean rubrics as a paradigm for scalable health evaluations. We hypothesized that a small set of granular, boolean (Yes/No) criteria would enhance consistency and efficiency in complex query evaluation. Existing work has demonstrated that "granularizing" complex evaluation criteria into a larger set of focused, boolean rubrics improves rater reliability for general-domain tasks like summarization and dialogue. Our work extends these frameworks by applying them to the health domain, accounting for user personalization with health data in both the LLM responses and the evaluations. We validate this approach in metabolic health, a domain encompassing diabetes, cardiovascular disease, and obesity.
A set of representative health queries and wearable data are used to construct inputs to the language model, these are then evaluated using our proposed evaluation rubric framework.
Designing Adaptive Precise Boolean rubrics
We first used an iterative process to transform rubric criteria characterized by high-complexity response options (e.g., open-ended text or multi-point Likert scales) into a more granular set of rubric criteria employing binary response options (i.e., boolean “Yes” or “No”) — an approach we call Precise Boolean rubrics. The primary objective in developing the Precise Boolean rubrics was to enhance inter-rater reliability in annotation tasks and to generate a more robust and actionable evaluation signal, thereby facilitating programmatic interpretation and response refinement. The increased granularity afforded by the simple Yes/No format mitigates subjective interpretation and fosters more consistent evaluations, even with a larger number of total questions.
Due to the granular nature of our rubric design, the resulting Precise Boolean rubrics consisted of a substantially larger number of evaluation criteria compared to the starting Likert-scale rubrics. While auto-eval techniques are well equipped to handle the increased volume of evaluation criteria, the completion of the proposed Precise Boolean rubrics by human annotators was prohibitively resource intensive. To mitigate such burden, we refined the Precise Boolean approach to dynamically filter the extensive set of rubric questions, retaining only the most pertinent criteria, conditioned on the specific data being evaluated. This data-driven adaptation, referred to as the Adaptive Precise Boolean rubric, enabled a reduction in the number of evaluations required for each LLM response. This is because user queries and corresponding LLM outputs often exhibit a focused topicality, thus requiring evaluation against only the subset of rubric criteria relevant to those themes.
To convert the Precise Boolean rubrics to Adaptive Precise Boolean ones, we leveraged Gemini as a zero-shot rubric question classifier. Input to the LLM includes the user query, the corresponding LLM response under evaluation, and a specific rubric criterion. The LLM then outputs whether the criterion is relevant or not. To validate this adaptive approach, we established a ground-truth dataset through rubric question classification annotations provided by three medical experts, with majority voting employed to determine the consensus annotation. Rubrics obtained based on using this ground-truth dataset in order to do adaptation are referred to as Human-Adaptive Precise Boolean rubrics.

An example of a query and response highlighting references to specific relevant parts of the response, alongside examples of responses to evaluation rubric questions (Likert, Precise Boolean, and Adaptive Precise Boolean).
Key results
Enhanced inter-rater agreement and reduced evaluation time
Current evaluation of LLMs in health often uses Likert scales. We compared this baseline to our data-driven Precise Boolean rubrics. Our results showed significantly higher inter-rater reliability using Precise Boolean rubrics, measured by intra-class correlation coefficients (ICC), compared to traditional Likert rubrics.
A key advantage of our approach is its efficiency. The Adaptive Precise Boolean rubrics resulted in high inter-rater agreement of the full Precise Boolean rubric while reducing evaluation time by over 50%. This efficiency gain makes our method faster than even Likert scale evaluations, enhancing the scalability of LLM assessment. The fact that this also provides higher inter-rater reliability supports the argument that this simpler scoring also provides a higher quality signal.

Left: Inter-rater correlation, as measured by intra-class correlation coefficient (ICC), between different subgroups — human evaluators (expert and non-expert) and automated evaluation. Right: Adaptive Precise Boolean rubrics take about half the time compared to likert scale questions.
Improved sensitivity to response quality
To test the efficacy of our rubrics, we investigated their sensitivity to variations in response quality. We systematically augmented user queries with increasing levels of contextual health data, hypothesizing that richer queries would elicit higher-quality LLM responses, the results to support this will be discussed in detail below.
Average ratings from Likert scales showed limited sensitivity to these improvements in input context, particularly in automated evaluations. This suggests a lack of granularity in Likert scales for capturing subtle variations in response quality. In contrast, the average scores from our boolean rubrics showed a clear, positive correlation with the amount of user data provided, indicating a superior ability to measure incremental improvements in response quality.
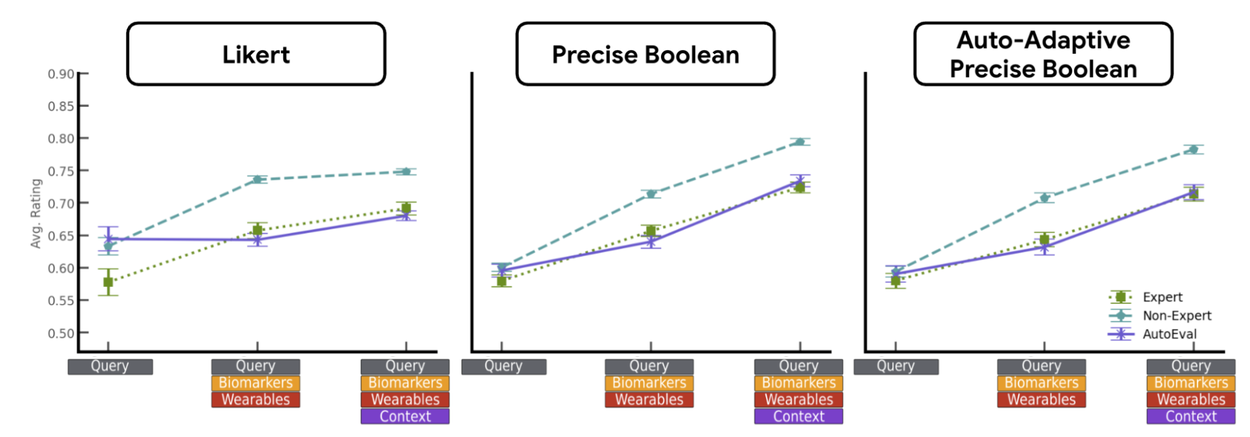
Implications on Average Ratings: Ratings obtained from auto-evals using the boolean rubrics are more consistent/correlated with human ratings. In addition, replacing all questions with an adaptive set has little impact on the signal.
Auto-Adaptive Precise Boolean rubrics
The Precise Boolean rubric framework is comprehensive, but for any given query, only a subset of its questions are relevant. We automated this filtering process by using Gemini as a zero-shot classifier to predict the relevance of individual rubric questions based on the input query and the LLM response. The classifier achieved an average accuracy of 0.77 and an F1 score of 0.83 in identifying relevant questions. We found that the Auto-Adaptive Boolean rubrics, using this automated filter, maintained an equivalent improvement in ICC and showed similar scoring trends as the Human-Adaptive Boolean rubrics. This suggests that an imperfect but effective automated classifier is sufficient to capture the essential evaluation signal. This finding is critical for building fully automated and scalable evaluation pipelines.

(A) Adaptation of Precise Boolean rubrics using Gemini 1.5 Pro as a zero-shot rubric question classifier does not degrade ICC compared to using human driven adaptation. (B) Auto-Adaptive rubrics shows a similar average rating trend to Human-Adaptive rubrics, indicating that the Auto-Adaptive evaluation criteria are sufficient to capture the evaluation signals present based on human adaptation.
Superior identification of response quality gaps
To demonstrate robustness, we evaluated our framework's ability to detect flaws in LLM responses generated from real research participants’ data. We used de-identified data from the Wearables for Metabolic Health (WEAR-ME) study, a large-scale (n≈1500) research project that collected wearable, biomarker, and questionnaire data conducted with approval from an Institutional Review Board (IRB). All participants provided electronic informed consent and a specific HIPAA Authorization via the Google Health Studies app before enrollment, acknowledging that their de-identified data would be used for research purposes.
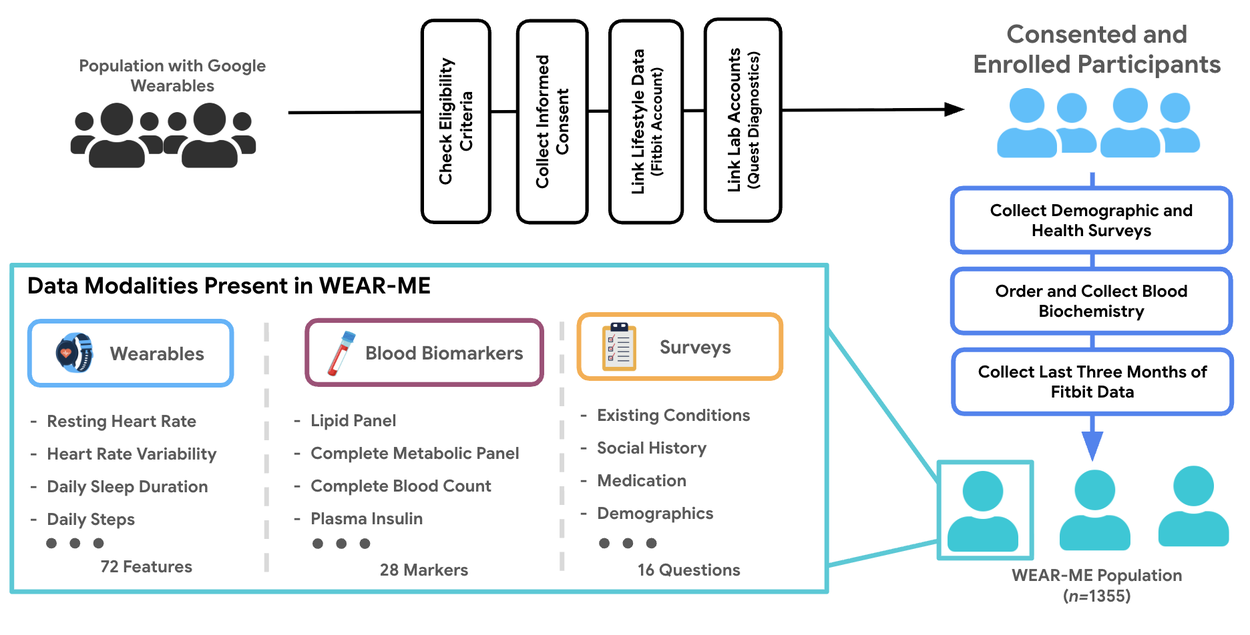
Application of proposed approach on a real health study (WEAR-ME).
For this specific analysis, we selected 141 participants with confirmed metabolic conditions (e.g., Class III obesity, diabetes, hypercholesterolemia) to test the frameworks’ sensitivity. For each participant, we prompted an LLM to answer health queries under two conditions:
- Unaltered: The prompt included the participant's complete, real health data.
- Altered: The prompt deliberately omitted key biomarkers relevant to the participant's condition and instructed the LLM not to use personal health data.

Illustration of our prompt ablation scheme.
We then used an automated evaluation system to score both the responses using both Likert and Precise Boolean rubrics. A higher positive discrepancy score (score of unaltered response minus score of altered response) indicates that the evaluation framework successfully detected the drop in quality.
As shown below, the Precise Boolean framework consistently produced a large, positive discrepancy score, indicating it reliably detected that the altered responses were of lower quality. In contrast, the Likert scale's discrepancy score was inconsistent and smaller in magnitude, failing to reliably flag the lower-quality responses. These results demonstrate that the Precise Boolean framework is significantly more sensitive to the inclusion of personal data, making it a more robust tool for automated evaluation pipelines.

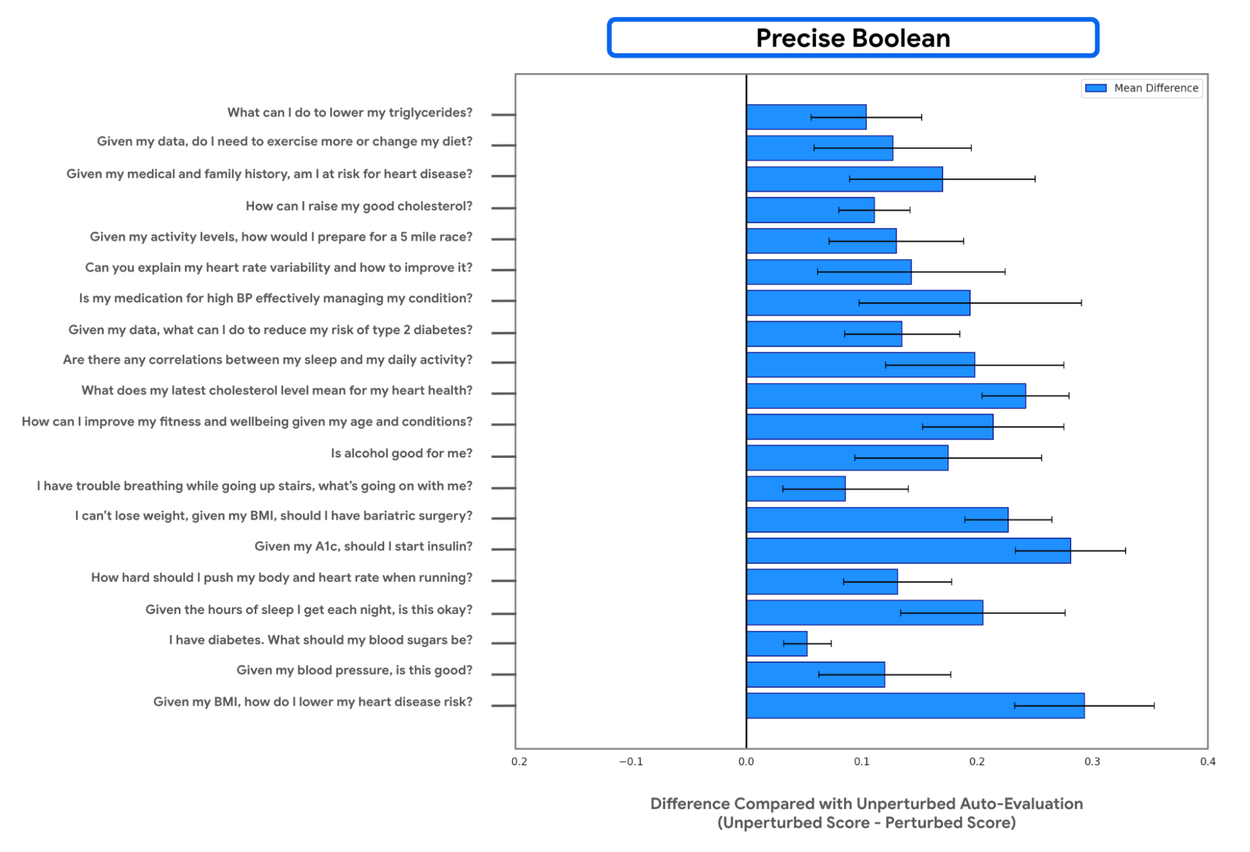
Measuring the sensitivity of an auto-rater to prompt alterations using Likert rubrics and the proposed Precise Boolean rubrics.
Conclusion and future directions
Our findings show that using Adaptive Precise Boolean rubrics:
- Substantially reduces inter-rater variability compared to Likert scales.
- Halves evaluation time for both expert and non-expert evaluators.
- Achieves automated evaluation parity with expert human judgment.
- More sensitively detects quality discrepancies when integrated with real-world wearable, biomarker, and contextual data.
This approach offers a significant advancement in scaling and streamlining LLM evaluation in specialized domains. While LLMs hold promise for health applications, this paper focuses on the critical need for robust evaluation methodologies and does not present the models as approved medical devices.
Our framework is domain-agnostic and could be applied beyond health and personalized evaluation. The use of a health and wellness context for validation is for illustrative and research purposes only. This research is not tied to any specific product or service. The LLMs discussed are used in a controlled research setting and any real-world health application would be subject to its own validation and potential regulatory review. There are some limitations to this approach, in some situations the nuanced rating provided by Likert scale can be useful. Future work can expand on our results by incorporating a wider variety of user personas and health domains. Additionally, the process of creating the initial boolean questions from Likert criteria could be further automated by incorporating LLMs, enhancing the framework's scalability from its inception.
Acknowledgements
The following researchers contributed to this work: Neil Mallinar, A. Ali Heydari, Xin Liu, Anthony Z. Faranesh, Brent Winslow, Nova Hammerquist, Benjamin Graef, Cathy Speed*, Mark Malhotra, Shwetak Patel, Javier L. Prieto*, Daniel McDuff, and Ahmed A. Metwally.
* Work done while at Google.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence







