A return to hand-written notes by learning to read & write
October 28, 2024
Blagoj Mitrevski, Software Engineer, and Andrii Maksai, Staff Software Engineer, Google Research
We present a model to convert photos of handwriting into a digital format that reproduces component pen strokes, without the need for specialized equipment.
Quick links
Digital note-taking is gaining popularity, offering a durable, editable, and easily indexable way of storing notes in a vectorized form. However, a substantial gap remains between digital note-taking and traditional pen-and-paper note-taking, a practice still favored by a majority of people.
Bridging this gap by converting a note taker’s physical writing into a digital form is a process called derendering. The result is a sequence of strokes, or trajectories of a writing instrument like a pen or finger, recorded as points and stored digitally. This is also known as an “online” representation of writing, or “digital ink”.
The conversion to digital ink offers users who still prefer traditional handwritten notes access to their notes in a digital form. Instead of simply using optical character recognition (OCR), which would allow the writing to be transcribed to a text document, by capturing the handwritten documents as a collection of strokes, it's possible to reproduce them in a form that can be edited freely by hand in a way that is more natural. It allows the user to create documents with a realistic look that captures their handwriting style, rather than simply a collection of text. This representation allows the user to later inspect, modify or complete their handwritten notes, which gives their notes enhanced durability, seamless organization and integration with other digital content (images, text, links) or digital assistance.
For these reasons, this field has gained significant interest in both academia and industry, with software solutions that digitize handwriting and hardware solutions that leverage smart pens or special paper for capture. The need for additional hardware and accompanying software stack is, however, an obstacle for wider adoption, as it creates both onboarding friction and carries additional expense for the user.
With this in mind, in “InkSight: Offline-to-Online Handwriting Conversion by Learning to Read and Write”, we propose an approach to derendering that can take a picture of a handwritten note and extract the strokes that generated the writing without the need for specialized equipment. We also remove the reliance on typical geometric constructs, where gradients, contours, and shapes in an image are utilized to extract writing strokes. Instead, we train the model to build an understanding of “reading”, so it can recognize written words, and “writing”, so it can output strokes that resemble handwriting. This results in a more robust model that performs well across diverse scenarios and appearances, including challenging lighting conditions, occlusions, etc. You can access the model and the inference code on our GitHub repo.
Overview
The key goal of this approach is to capture the stroke-level trajectory details of handwriting. The user can then store the resulting strokes in the note taking app of their choice.

Left: Offline handwriting. Right: Output digital ink (online handwriting). In every word, character colors transition from red to purple, following the rainbow sequence, ROYGBIV. Within each stroke, the shade progresses from darker to lighter.
Challenges
While the fundamental concept of derendering appears straightforward — training a model that generates digital ink representations from input images — the practical implementation for arbitrary input images presents two significant challenges:
- Limited Supervised Data: Acquiring paired data with corresponding images and ground truth digital ink for supervised training can be expensive and time-consuming. To our knowledge, no datasets with sufficient variety exist for this task.
- Scalability to large images: The model must effectively handle arbitrarily large input images with varying resolutions and amount of content.
Method
Learning to read and write
To address the first problem while avoiding onerous data collection, we propose a multi-task training setup that combines recognition and derendering tasks. This enables the model to generalize on derendering tasks with various styles of images as input, and injects the model with both semantic understanding and knowledge of the mechanics of writing handwritten text.
This approach thus differs from methods that rely on geometric constructs, where gradients, contours, and shapes in an image are utilized to extract writing strokes. Learning to read enhances the model's capability in precisely locating and extracting textual elements from the images. Learning to write ensures that the resulting vector representation, the digital ink, closely aligns with the typical human approach of writing in terms of physical dynamics and the order of strokes. Combined, these allow us to train a model in the absence of large amounts of paired samples, which are difficult to obtain.
System workflow
One solution to the problem of scalability is to train a model with very high-resolution input images and very long output sequences. However, this is computationally prohibitive. Instead, we break down the derendering of a page of notes into three steps: (1) OCR to extract word-level bounding boxes, (2) derendering each of the words separately, and (3) replacing the offline (pixel) representation of the words with the derendered strokes using the color coding described above to improve visualization.
To narrow the domain gap between the synthetic images of rendered inks and the real photos, we augment the data in tasks that take rendered ink as input. Data augmentation is done by randomizing the ink angle, color, stroke width, and by adding Gaussian noise and cluttered backgrounds.
Vision-language model for digital ink
We create a training mixture that comprises five different task types. The first two tasks are derendering tasks (i.e., they generate a digital ink output). One uses only an image as input and the other uses both an image and the accompanying text that has been recognized by the OCR model. The following two tasks are recognition tasks that produce text output, the first of which leverages real images and the latter, synthetic ones. Finally, a fifth task is a combination of recognition and derendering, hence a mixed task with text-and-ink output.
Each type of task utilizes a task-specific input text, enabling the model to distinguish between tasks during both training and inference. Below you will find a recognition and a derendering task.
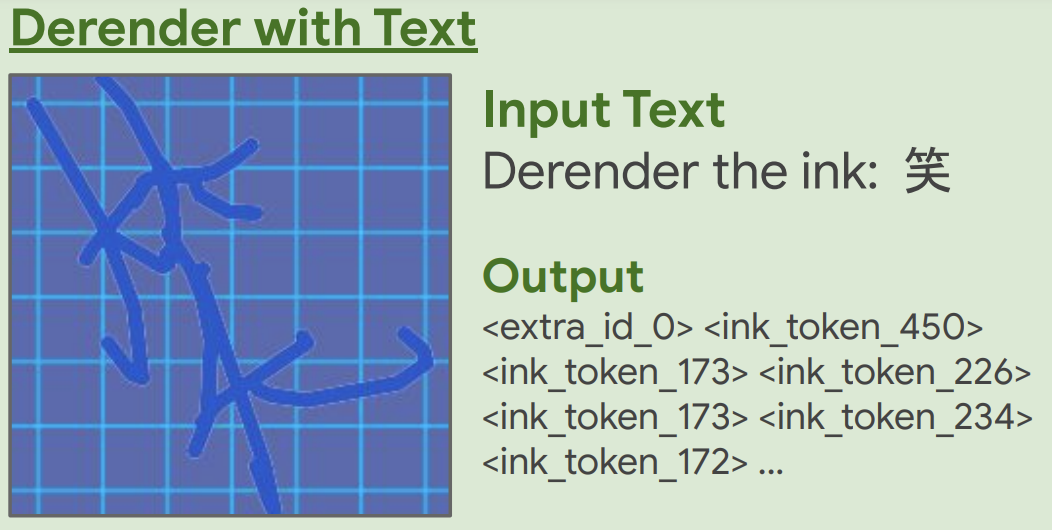
Derendering with text: Takes an image and a text input and outputs the ink that would generate that text in the style of the image.

Recognition of synthetic images: Takes an image and recognizes what is written within.
To train the system, we pair images of text and corresponding digital ink. The digital ink is sampled from real-time writing trajectories and subsequently represented as a sequence of strokes. Each stroke is represented by a sequence of points, obtained by sampling from the writing or drawing trajectory at a constant rate (e.g., 50 points per second). The corresponding image is created by rendering the ink - creating a bitmap at a prespecified resolution. This creates a pixel-stroke correspondence, that is a precursor for the model input-output pairs.
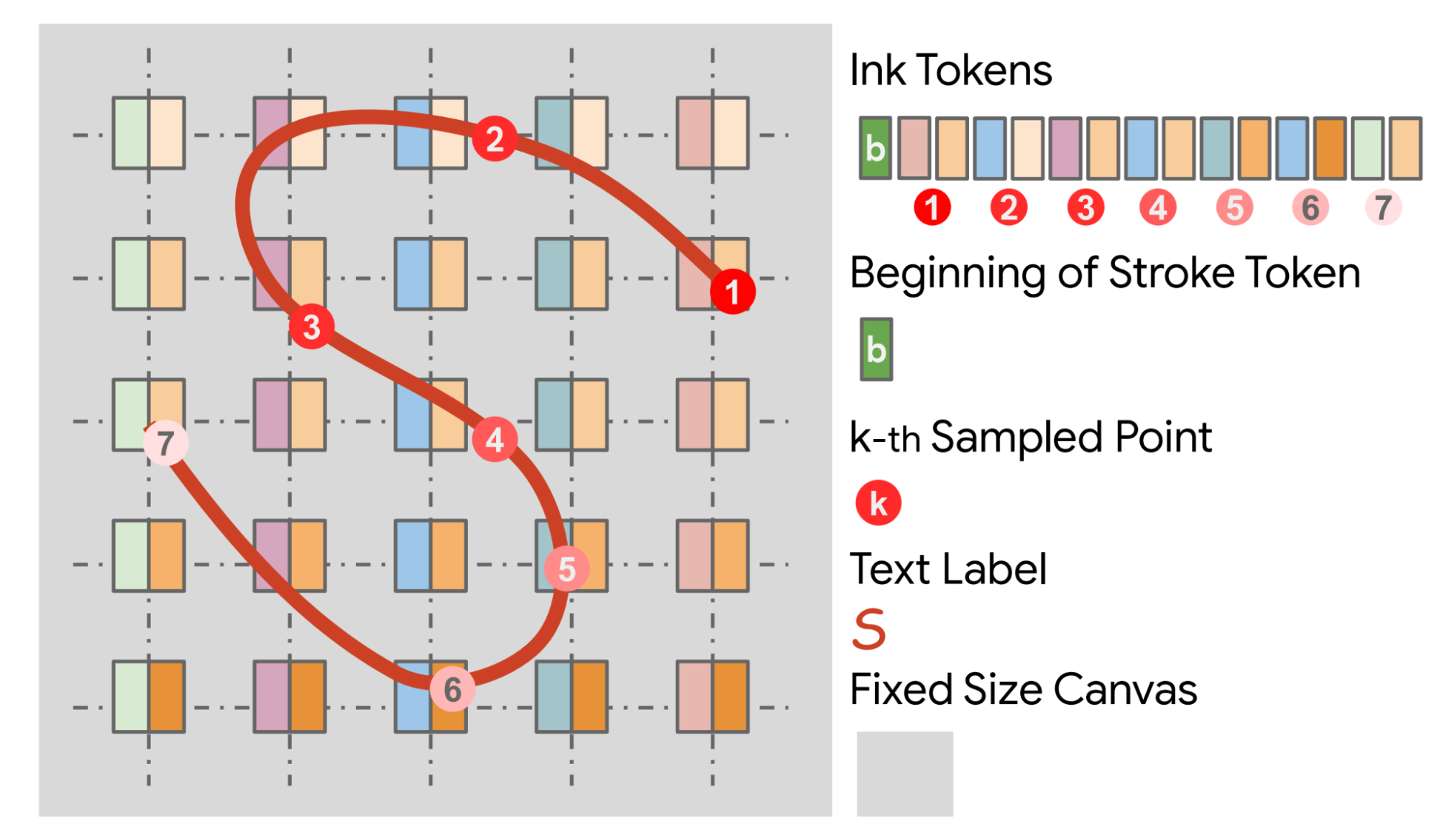
A further necessary step, and a unique one for this modality, is the ink tokenizer, which represents the points in a format that is friendly to a large language model (LLM). Each point is converted into two tokens, one each encoding its x and y coordinates. The token sequence for this ink begins with b, signifying the beginning of the stroke, followed by the tokens for the coordinates of the sampled points.
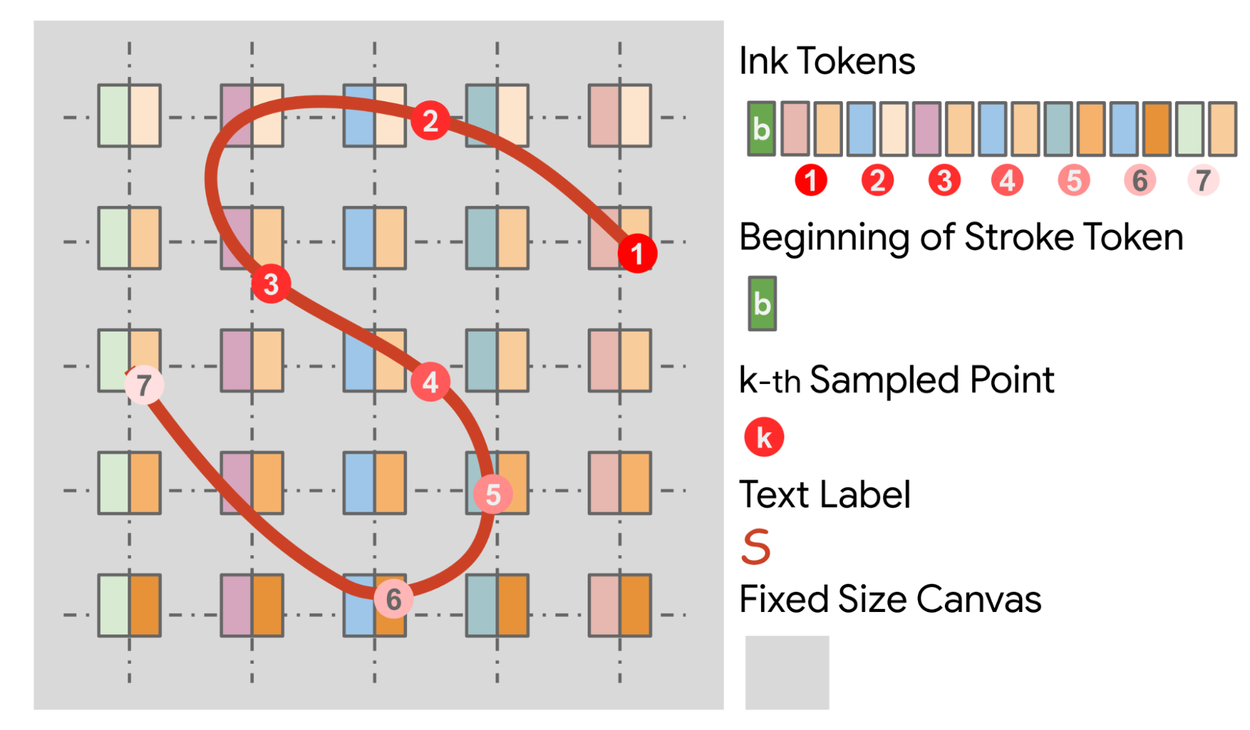
Illustration of the ink tokenization for a single-stroke ink. The dark red ink depicts the ink stroke, with numbered circles marking sampled points after time resampling. The color gradient of the sampled points (1–7) indicates the point order. Each point is represented with two tokens encoding its coordinates x (left half of the shaded box) and y (right half). The token sequence for this ink begins with b, signifying the beginning of the stroke, followed by the tokens for coordinates of sampled points.
Results
To evaluate the performance of our approach, we first collected an evaluation dataset. We started with OCR data, and then added paired samples that we collected manually by asking people to trace text images they were shown (human-generated traces).
We then trained three variants of the model: Small-p (∼340M parameters, “-p” for “public” setup), Small-i (“-i” for “in-house”), and Large-i (∼1B parameters). We compared our approach to a General Virtual Sketching (GVS) baseline.
We show that the vector representations produced by our system are both semantically and geometrically similar to the input images, and are similar to human-generated digital ink data, as measured by both automatic and human evaluations.
Qualitative evaluation
We show the performance of our models and GVS compared to two public evaluation datasets, IAM and IMGUR5K, and an out of domain dataset of sketches. Our models mostly produce results that accurately reflect the text content, disregarding semantically irrelevant background. They can also handle occlusions, highlighting the benefit of the learned reading prior. In contrast, GVS produces multiple duplicate strokes and has difficulty distinguishing between background and foreground. Our Large-i model is further able to retain more details and accommodate more diverse image styles. See the paper for more examples.

Comparison between performance of GVS, Small-i, Small-p, and Large-i on two public evaluation datasets (Rows 1–3, IAM; rows 4–6, IMGUR5K).

Out-of-domain behavior: Sketch derendering for Small-p, Small-i, Large-i and GVS. Our models are mostly able to derender simple sketches, however they do still exhibit significant artifacts like extraneous or misaligned strokes.
Quantitative evaluation
At present, the field has not established metrics or benchmarks for quantitative evaluation of this task. So, we conduct both human and automated evaluation to compare the similarity of our model output to the original image and to human-generated digital inks.
Here we present the human evaluation results, with numerous other results derived from automated evaluations and an ablation study in our paper. We performed a human evaluation of the quality of the derendered inks produced by the three model variants. We used the “golden” human traced data from the HierText dataset as the control group and the output of our model on these samples as the experimental group.

Comparison of the performance of our models (Small-p, Small-i and Large-i) and manual tracing on two samples of text of varying difficulty from the HierText dataset.
In the figure above, notice the error in the quote for all models on the top row (the double-quote mark), which the human tracing got correct. On the bottom row the situation is reversed, with the human tracing focusing solely on the main word, missing most other elements. The human tracing is also not perfectly aligned with the underlying image, emphasizing the complexity and tracing difficulty of the handwritten parts of the HierText dataset.
Evaluators were shown the original image alongside a rendered digital ink sample, which was either model-generated or human-traced (unknown to the evaluators). They were asked to answer two questions: (1) Is the digital ink output a reasonable tracing of the input image? (Answers: “Yes, it’s a good tracing,” “It’s an okay tracing, but has some small errors,” “It’s a bad tracing, has some major artifacts.”) (2) Could this digital ink output have been produced by a human? (Answers: “Yes” or “No”.) The evaluation included 16 individuals familiar with digital ink, but not involved in this research. Each sample was evaluated by three raters and aggregated with majority voting.
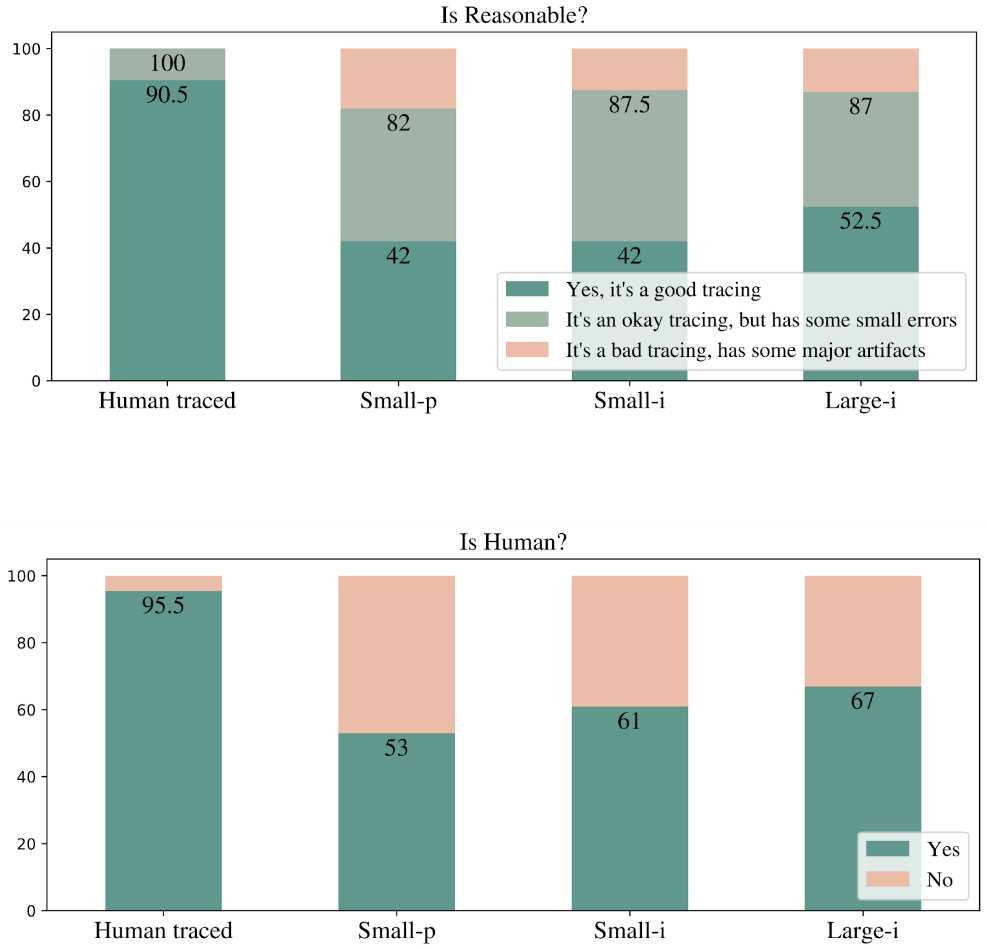
The results show that a majority of derendered inks, generated with the Large-i model perform about as well as human-generated ones. Moreover 87% of the Large-i outputs are marked as good or having only small errors.
Conclusion
In this work we present a first-of-its-kind approach to convert photos of handwriting into digital ink. We propose a training setup that works without paired training data. We show that our method is robust to a variety of inputs, can work on full handwritten notes, and generalizes to out-of-domain sketches to some extent. Furthermore, our approach does not require complex modeling and can be constructed from standard building blocks.
Acknowledgements
We want to thank all the authors of this work, Arina Rak, Julian Schnitzler, and Chengkun Li, who formed a student team working with Google Research for the duration of the project, as well as Claudiu Musat, Henry Rowley and Jesse Berent. All authors, with the exception of the student team, are now part of Google Deepmind.
Quick links
Other posts of interest
-

June 12, 2026
Research into how AI can help users understand skin conditions- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

June 4, 2026
Towards passive heart health monitoring via smartphone camera- Health & Bioscience ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

June 3, 2026
The next chapter in flood resilience: Open sourcing Google’s hydrology framework- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets






