
A picture is worth a thousand (coherent) words: building a natural description of images
November 17, 2014
Posted by Google Research Scientists Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan
Quick links
“Two pizzas sitting on top of a stove top oven”
“A group of people shopping at an outdoor market”
“Best seats in the house”
People can summarize a complex scene in a few words without thinking twice. It’s much more difficult for computers. But we’ve just gotten a bit closer -- we’ve developed a machine-learning system that can automatically produce captions (like the three above) to accurately describe images the first time it sees them. This kind of system could eventually help visually impaired people understand pictures, provide alternate text for images in parts of the world where mobile connections are slow, and make it easier for everyone to search on Google for images.
Recent research has greatly improved object detection, classification, and labeling. But accurately describing a complex scene requires a deeper representation of what’s going on in the scene, capturing how the various objects relate to one another and translating it all into natural-sounding language.
 |
| Automatically captioned: “Two pizzas sitting on top of a stove top oven” |
This idea comes from recent advances in machine translation between languages, where a Recurrent Neural Network (RNN) transforms, say, a French sentence into a vector representation, and a second RNN uses that vector representation to generate a target sentence in German.
Now, what if we replaced that first RNN and its input words with a deep Convolutional Neural Network (CNN) trained to classify objects in images? Normally, the CNN’s last layer is used in a final Softmax among known classes of objects, assigning a probability that each object might be in the image. But if we remove that final layer, we can instead feed the CNN’s rich encoding of the image into a RNN designed to produce phrases. We can then train the whole system directly on images and their captions, so it maximizes the likelihood that descriptions it produces best match the training descriptions for each image.
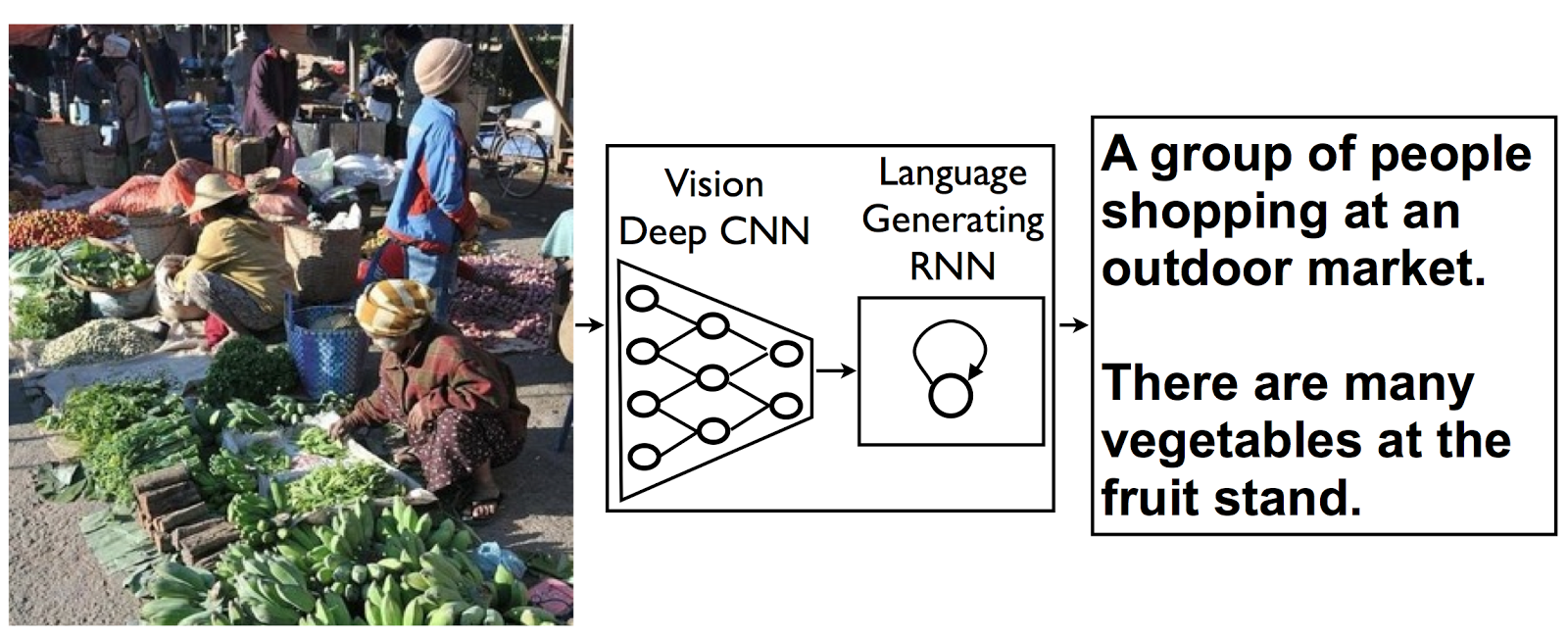 |
| The model combines a vision CNN with a language-generating RNN so it can take in an image and generate a fitting natural-language caption. |
 |
| A selection of evaluation results, grouped by human rating. |
Quick links
Other posts of interest
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯


