An improved flood forecasting AI model, trained and evaluated globally
November 11, 2024
Deborah Cohen, Staff Research Scientist and Team Lead, Google Research
We present our most recent flood forecasting model, which we are now making available to researchers and partners with additional data intended for use by experts and researchers. This model provides a 7-day lead time reliability comparable to the current best available nowcasts, and it expands coverage to 100 countries with verified data and up to 150 countries with data based on virtual gauges.
Floods are among the most common and widespread natural disasters, affecting more people than any other. The rate of flood events has been on the rise, more than doubling since 2000. In an effort to improve forewarning systems, over the past few years we have been using AI-based technologies to advance research towards global flood forecasting. Our previous operational model could reliably predict flooding events in ungauged watersheds (i.e., locations where no data are available) at a 7-day lead time.
Today we describe our most recent model, which builds upon the prior version to provide more reliable flood prediction globally. The new model has the same accuracy at a 7-day lead time as the previous model had at five days, which was itself shown to be consistent with state-of-the-art global flooding nowcasts (i.e., models with a 0-day lead time). This increase in lead time reliability is crucial for anticipatory action. To facilitate access, we’ll be making our model forecasts available to researchers and partners via (1) an upcoming API that provides real-time forecasts with 7-day lead time and (2) our Google Runoff Reanalysis & Reforecast dataset (GRRR), which contains an historical re-forecast for 2016–2023 and reanalysis for 1980–2023.
The improved model quality and our new evaluation approach for ungauged watersheds has expanded our coverage, but the expansion is still limited by a lack of data available to validate the model everywhere. To encourage additional research in these regions of ungauged watersheds, we are also sharing a new expert data layer on Flood Hub our model forecasts for locations where the model quality has not been validated. These forecasts are intended for use by researchers and experts, with forecasts available seven days in advance for over 150 countries.
As part of this expansion, we’re now also reaching Google users in over 100 countries via our Flood Hub, up from 80. This increase enables us to provide critical flood information to 700 million people worldwide, a significant leap from our previous reach of 460 million.
Expanded coverage for expert users
While our hydrologic model is able to provide discharge predictions at any point on Earth, the quality of the forecasts can only be validated on historical data in a fraction of them, because much of the world doesn't have reliable sensors to measure streamflow. Nevertheless, even if the forecast quality is not validated in a certain location, making this data available to expert users and researchers can still help advance their understanding of how floods impact people around the world. This data can also be useful to governments and NGOs in situations where there is no other data available. To this end, we have added to the Flood Hub close to 250k forecast points of our Flood Forecasting model, spread over 150 countries. These forecasts include “virtual gauges” whose forecast was not verified, either as their quality assessment was not possible due to lack of data or where the evaluation did not produce sufficiently high quality. We are also offering a waitlist for limited API access to expert users in the disaster management and hydrology domains.
ML hydrologic model
We train a single ML model on all available streamflow data and use it to infer the streamflow in locations where no data are available (ungauged watersheds). This is critical for providing forecasts to communities most vulnerable to flood risks, which typically correlate with countries where streamflow measurements are scarce. As demonstrated in our recent Nature publication, applying AI models to forecasts in data-scarce regions like Africa and Asia can improve the reliability of flood forecasting to be similar to the forecasts currently available in Europe.
Our prior ML hydrologic model takes as input meteorological time-series data from various weather products (NASA IMERG, NOAA CPC, and the ECMWF ERA5-land reanalysis), including precipitation and air temperature, combined with static catchment attributes from the HydroSheds dataset, such as topographic characteristics, soil properties, climate indices, and more. The training data includes daily streamflow values from the Global Runoff Data Center (GRDC). The model is built on an LSTM network, which is well-suited for applications to time-series data, and is tasked to provide a 7-day lead time streamflow forecast.
We recently introduced several enhancements to this model: (1) adding an AI-based medium-range global weather forecasting model released by Google DeepMind, as input to the model; (2) increasing the training data from 5,680 gauges to close to 16,000 gauges, mostly by adding gauges from Caravan, a global open community hydrologic dataset; and (3) improving the LSTM-based architecture to better combine the different weather products used as input and to increase the model robustness to missing weather data in the operational setting. In addition, we have upgraded our model evaluation approach in ungauged locations, thus allowing us to validate and make available the model forecasts in many more locations.
Improved flood prediction with an improved weather forecasting model
Past experiments showed that LSTM models learn to combine and leverage multiple weather products. Thus, by adding more sources of weather data we expected to improve the skill of the flood forecasting model. So, we incorporated Google DeepMind’s medium-range global weather forecasting model as input to the existing hydrologic model.
This model is able to make medium-range weather forecasts with higher accuracy than the traditional deterministic gold standard in weather forecasting. It predicts five Earth-surface variables and six atmospheric variables. We integrate two of these surface variables, precipitation and temperature, into the flood forecasting hydrologic model.
To measure the impact of this global forecasting weather model on the reliability of our global hydrologic model, we compare our model performance with and without the addition of the weather forecasting model as input. As shown in the graphs below, the impact grows as lead time increases.
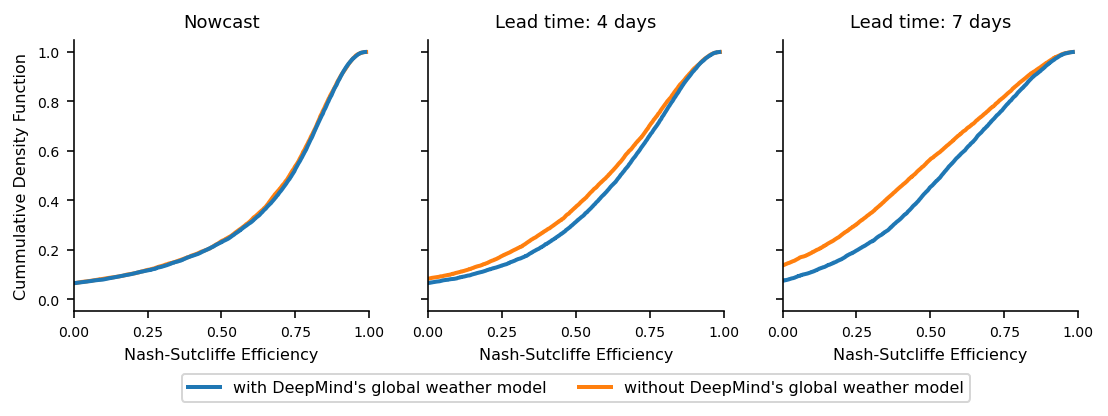
Cumulative distribution function of the Nash-Sutcliffe efficiency metric for the new model with Google DeepMind’s medium-range global weather forecasting model (blue) and without (orange), evaluated on 3,079 basins. The Nash-Sutcliffe Efficiency measures how well a model's predictions match up with real-world observations. An efficiency of 1.0 corresponds to a perfect match, whereas a score of 0.0 means that simply using the average of the observed data would give a better prediction than the model. Left: A 0-day lead time or nowcast. Middle: 4-day lead time. Right: 7-day lead time.
More labeled data from an open community dataset
We also improved the reliability of our model globally by adding more labeled data, tripling the number of gauges used for training from 5,680 gauges to 15,980. The additional data spanning locations in Europe, North America and South America came from various sources, but mainly from the Caravan project. Caravan is an open community dataset, supported by researchers at Google and several other institutions, that aggregates and standardizes existing datasets consisting of meteorological data, catchment attributes, and discharge data for catchments around the world.
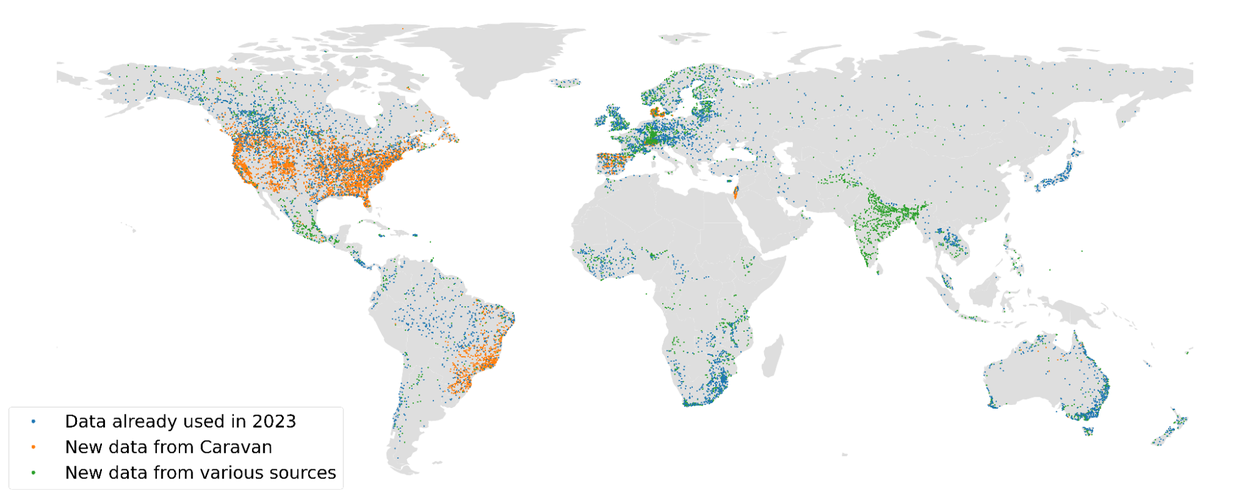
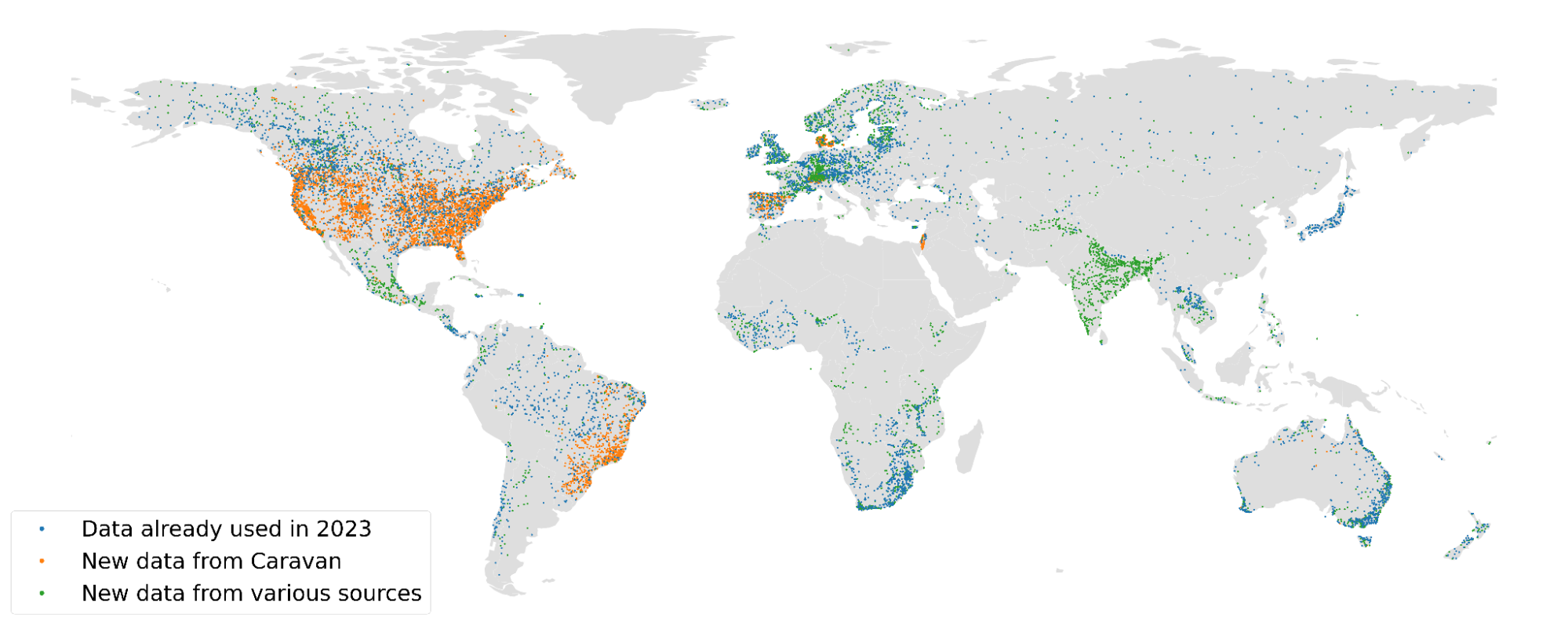
Map of the locations of the gauges used as training data: 5,680 gauges from GRDC used to train our previous model (blue), new data from Caravan (orange) and new gauges from other various sources (green).
New embedding-based LSTM architecture
The new model architecture uses different embedding networks for different weather products. Before all data is fed into the LSTM network, the outputs of the different embedding networks are combined given the data availability, which makes the model robust to individual weather products that might be missing in the operational setting. The output of the LSTM is used to derive the discharge forecasts using a mixture of density networks. We use a countable mixture of asymmetric Laplacians (CMAL) distribution, which represents a probabilistic prediction of the streamflow in a particular river at a particular time.
The new LSTM-based streamflow forecast architecture. Each weather product is embedded by a different network. The outputs are combined and fed into an LSTM network, which generates the parameters of a probability distribution over streamflow. “GC” refers to Google DeepMind’s medium-range global weather forecasting model.
The performance of the new model at a 7-day lead time is similar to the 5-day lead time performance of our previous model, effectively realizing a gain of two days lead time.
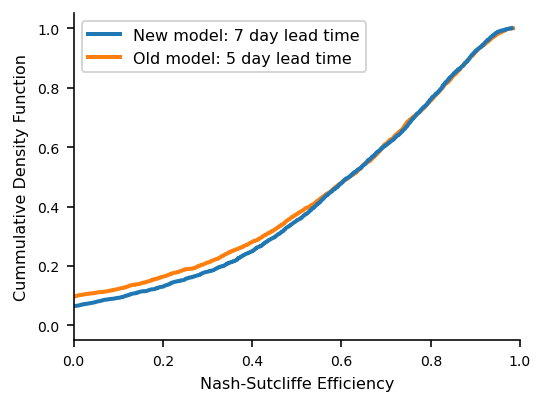
Cumulative distribution function of the Nash-Sutcliffe efficiency metric for the new model at a 7-day lead time (blue) and the previous model at a 5-day lead time (orange), as evaluated on 3,079 basins.
Model evaluation in ungauged watersheds
While our hydrologic model is able to provide discharge predictions at any point on Earth, we only make available forecasts whose quality has been validated. Hence, one critical limitation to expanding our forecasts to new locations is the ability to evaluate their quality in a given location. In gauged locations, namely where historical discharge measurements are available, we can easily evaluate the model using standard cross-validation techniques. However, gauged locations are limited and not uniformly distributed over the globe, and there are many regions where there are no ground truth gauge levels.
In such ungauged regions, we leverage historical satellite images that depict floods to evaluate the reliability of the hydrologic model in a direct manner. We check whether inundation events as spotted in images from synthetic-aperture radar (SAR) coincide with hydrological events, which we define as the occurrence of discharge higher than that expected to be reached in a 10 year return period. Inundation events are detected using a flood classifier. The SAR image is first segmented into wet and dry pixels by a Gaussian mixture model (GMM) classifier. Then, a random forest classifier determines whether the image is that of an inundation event or not. For a given location, if hydrological events forecast by the hydrologic model and inundation events detected in the SAR images occur simultaneously, the model is considered as validated.
Given that the revisit time of Sentinel 1, our source for SAR images, is 12 days, the inundation ground truth dataset is quite sparse. Hence, there are many locations in which we cannot validate the model, as there are no historical images showing inundation events there. To mitigate this issue, we also consider a location to be validated if another nearby and hydrologically similar location has been validated with either a gauge measurement or SAR images. This validation extrapolation strategy allows us to validate 30% more locations for which otherwise we would not have been able to show forecasts.
Advancing flood forecasting research
By making our forecasts available globally on FloodHub, even in locations with only virtual gauges, we hope to contribute to the research community. These data can be used by expert users and researchers to inform more studies and analysis into how floods impact communities around the world.
However, our journey is not yet complete. More work is needed to increase our coverage of riverine floods to yet more locations globally and to extend our AI-based flood forecasting to other types of flood-related events, including flash floods, urban floods and coastal floods.
Acknowledgements
We would like to thank everyone across the many teams who contributed to this project: Adi Gerzi Rosenthal, Adi Mano, Alon Harris, Alvaro Sanchez, Asher Metzger, Aviel Niego, Avinatan Hassidim, Ayelet Benjamini, Ben Feinstein, Dafi Voloshin, Dana Cohen, Elad Hanania, Frederik Kratzert, Grey Nearing, Guy Shalev, Hadas Fester, Juliet Rothenberg, Lauren Huang, Martin Gauch, Moriah Royz, Oleg Zlydenko, Oren Gilon, Peter Battaglia, Rotem Green, Ronit Levavi-Morad, Rotem Mayo, Shahar Timnat, Shai Ziv, Shlomo Shenzis, Shruti Verma, Tadele Yednkachw Tekalign, Tal Ikan, Vusumuzi Dube, Yoli Spigland, Yossi Matias, Yuval Carny.



