A differentially private framework for gaining insights into AI chatbot use
December 10, 2025
Alexander Knop, Research Scientist, and Daogao Liu, Post Doc Researcher, Google Research
Introducing a novel framework that generates high-level insights into AI chatbot usage through a pipeline of DP clustering, DP keyword extraction, and LLM summarization. This approach provides rigorous, end-to-end DP guarantees, ensuring user conversation privacy while offering utility for platform improvement.
Quick links
Large language model (LLM) chatbots are used by hundreds of millions of people daily for tasks ranging from drafting emails and writing code to planning vacations and creating menus for cafes. Understanding these high-level use cases is incredibly valuable for platform providers looking to improve services or enforce safety policies. It also offers the public insights into how AI is shaping our world.
But this raises a critical question: How can we gain valuable insights when the conversations themselves might contain private or sensitive information?
Existing approaches, like the CLIO framework, attempt to solve this by using an LLM to summarize conversations while prompting it to strip out personally identifiable information (PII). While a good first step, this method relies on heuristic privacy protections. The resulting privacy guarantee is difficult to formalize and may not hold up as models evolve, making these systems difficult to maintain and audit. This limitation led us to ask if it is possible to achieve similar utility with formal, end-to-end privacy guarantees.
In our paper, "Urania: Differentially Private Insights into AI Use," presented at COLM 2025, we introduce a new framework that generates insights from LLM chatbot interactions with rigorous differential privacy (DP) guarantees. This framework uses a DP clustering algorithm and keyword extraction method to ensure that no single conversation overly influences the result (i.e., the output summaries do not reveal information about any single individual's conversation). Here we explain the algorithm and demonstrate that this framework is indeed providing better privacy guarantees than prior solutions.
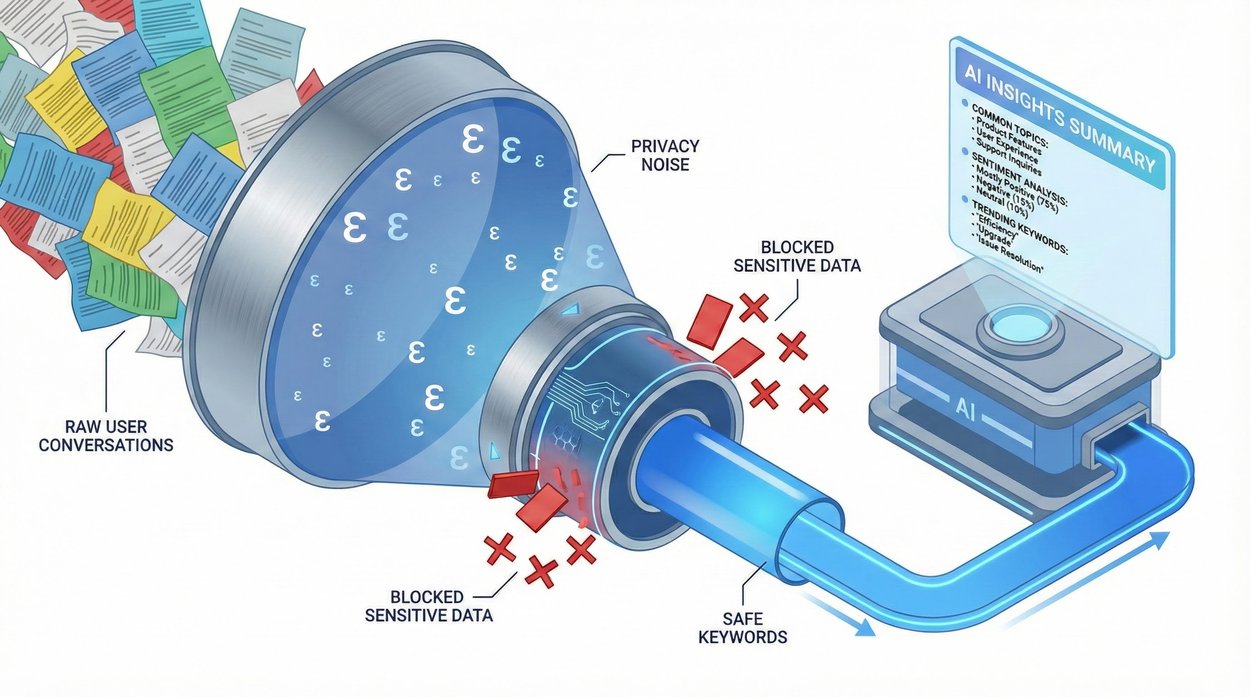
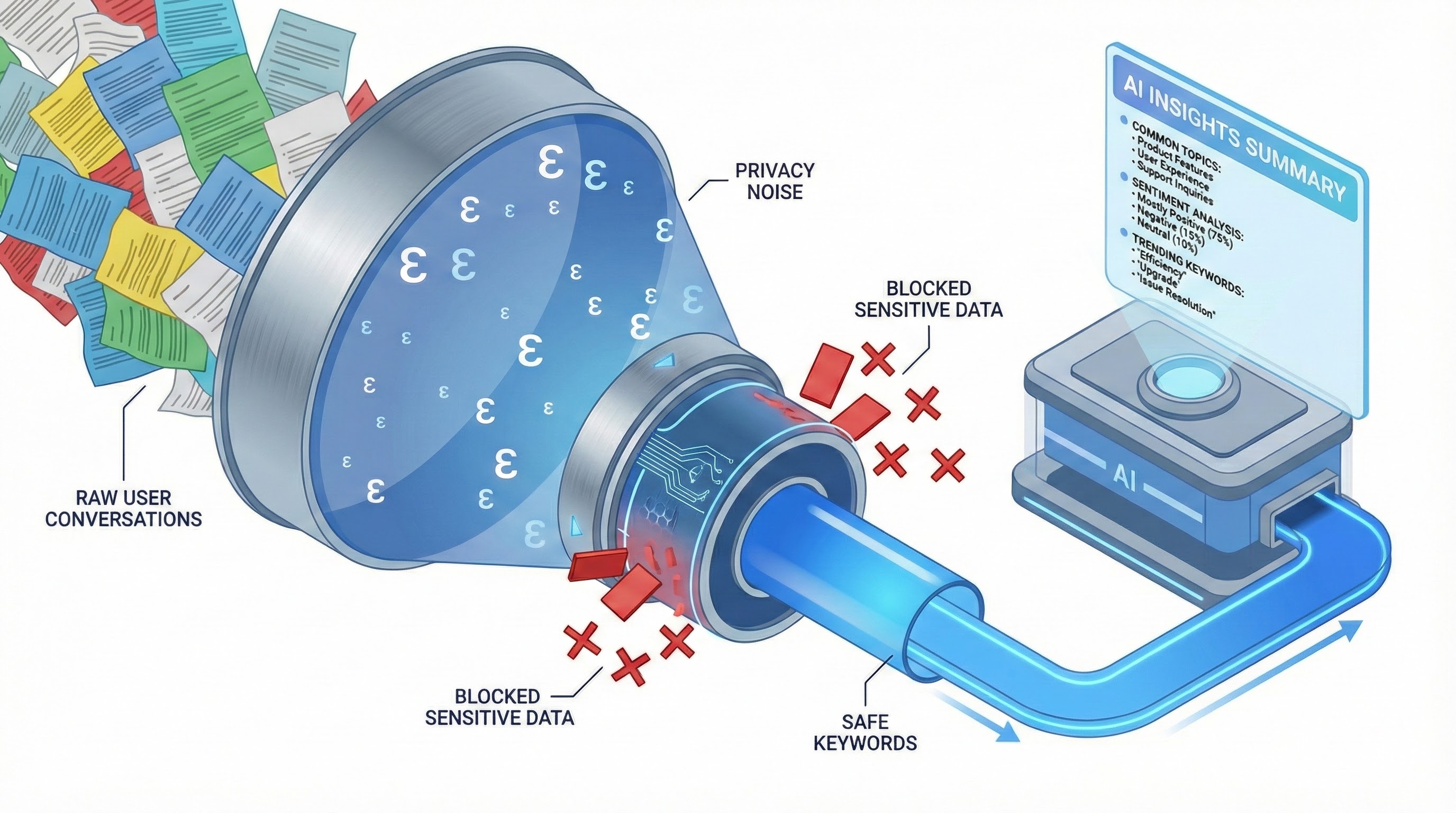
Gemini-generated image showing schematically how the algorithm works for one cluster of conversations.
Privacy-preserving framework for insights mining
DP uses a privacy budget parameter, ε, to measure the maximum allowed influence of any single user's contributions to the final output of a model. Our framework is designed to rely on two key properties of DP:
- Post-processing: If B is an ε-DP algorithm and A is any non-DP algorithm, then running A on the output of B keeps things private at a ε-DP level.
- Composition: If A and B are two separate ε-DP algorithms, running A on the dataset and the output of B still keeps the entire process private at a 2ε-DP level.
This differentially private pipeline is designed to ensure end-to-end user data protection through the following stages:
- DP clustering: Conversations are first converted into numerical representations (embeddings). The framework then groups representations that are close to each other using a DP clustering algorithm. This ensures that no single conversation overly influences the cluster centers.
- DP keyword extraction: Keywords are extracted from each conversation. For every cluster, our approach computes a histogram of keywords, i.e., it counts the number of times each keyword appears in the cluster, using a DP histogram mechanism (e.g., [1, 2]). We add noise to the histogram in order to mask the influence of individual conversations, ensuring that only keywords common to multiple users are selected, preventing unique or sensitive terms from being exposed. We explore three methods for creation of keywords for each conversation:
- LLM guided selection: We provide an LLM the conversation and ask it to create the top five most relevant keywords;
- DP version of TF-IDF: We get all the words in the conversation and weight them proportionally to the number of times they appear in the text and inversely proportional to the number of times they appear in the corpus; and
- LLM guided approach where there is an initial list of keywords obtained from public data: Instead of asking the LLM to generate keywords for each conversation independently, we create a list of potential keywords and ask LLM to choose the top 5 most relevant keywords from the list.
- LLM summarization from keywords: Finally, an LLM generates a high-level summary for each cluster using only the privately selected keywords. The LLM never sees the original conversations in the cluster, only the anonymized keywords. This post-processing property ensures the end-to-end privacy of the entire framework.
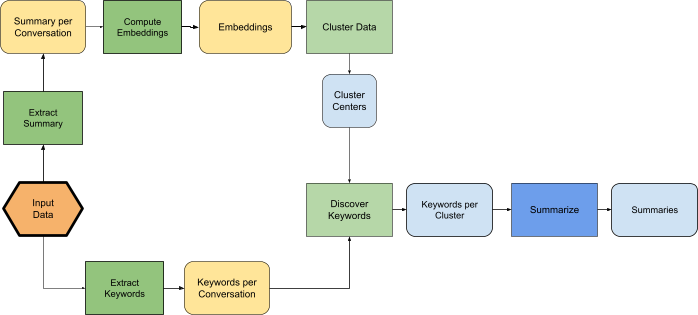
The framework’s data flow. Yellow nodes denote non-DP data, green nodes represent operations that are either DP or per conversation, light blue nodes denote private data, and dark blue nodes represent non-private operations.
By integrating DP at its core, this framework’s privacy guarantees are mathematical, not heuristic. They don't depend on an LLM's ability to perfectly redact private data: in other words, even if keywords contain PII or some other sensitive data, the generated summaries are not going to contain this data. In more practical terms, this guarantee makes it impossible for the LLM to reveal sensitive data (e.g., due to prompt injection attacks).
Putting this framework to the test
To evaluate our framework’s utility (summary quality) and privacy (protection strength), we compared its performance against Simple-CLIO, a non-private baseline we created inspired by CLIO. The baseline follows a two-step process:
- Conversations are converted into embeddings and clustered non-privately.
- For each cluster, a sample of conversations is fed to an LLM to generate a summary of those samples.
The privacy-utility trade-off
As expected, we observed a trade-off: stronger privacy settings (lower values of the privacy parameter ϵ) led to a decrease in the granularity of the summaries. For instance, topic coverage dropped as the privacy budget tightened, because the DP clustering algorithm produced fewer and less precise clusters.
However, the results also held a surprise. In head-to-head comparisons, LLM evaluators often preferred the private summaries generated by our framework. In one evaluation, the DP-generated summaries were favored up to 70% of the time. This suggests that the constraints imposed by this DP pipeline — forcing summaries to be based on general, frequent keywords — can lead to outputs that are more concise and focused than those from an unconstrained, non-private approach.
Empirical privacy evaluation
To test the framework’s robustness, we ran a membership inference-style attack designed to identify whether a specific sensitive conversation was included in the dataset. The results were clear: the attack on the DP pipeline performed about as well as random guessing, achieving an area under the curve (AUC) score of 0.53 (i.e., the integral of the ROC curve). In contrast, the attack was more successful against the non-private pipeline, which had a higher AUC of 0.58, indicating greater information leakage. This experiment provides empirical evidence that our privacy framework offers significantly stronger protection against privacy leakage.
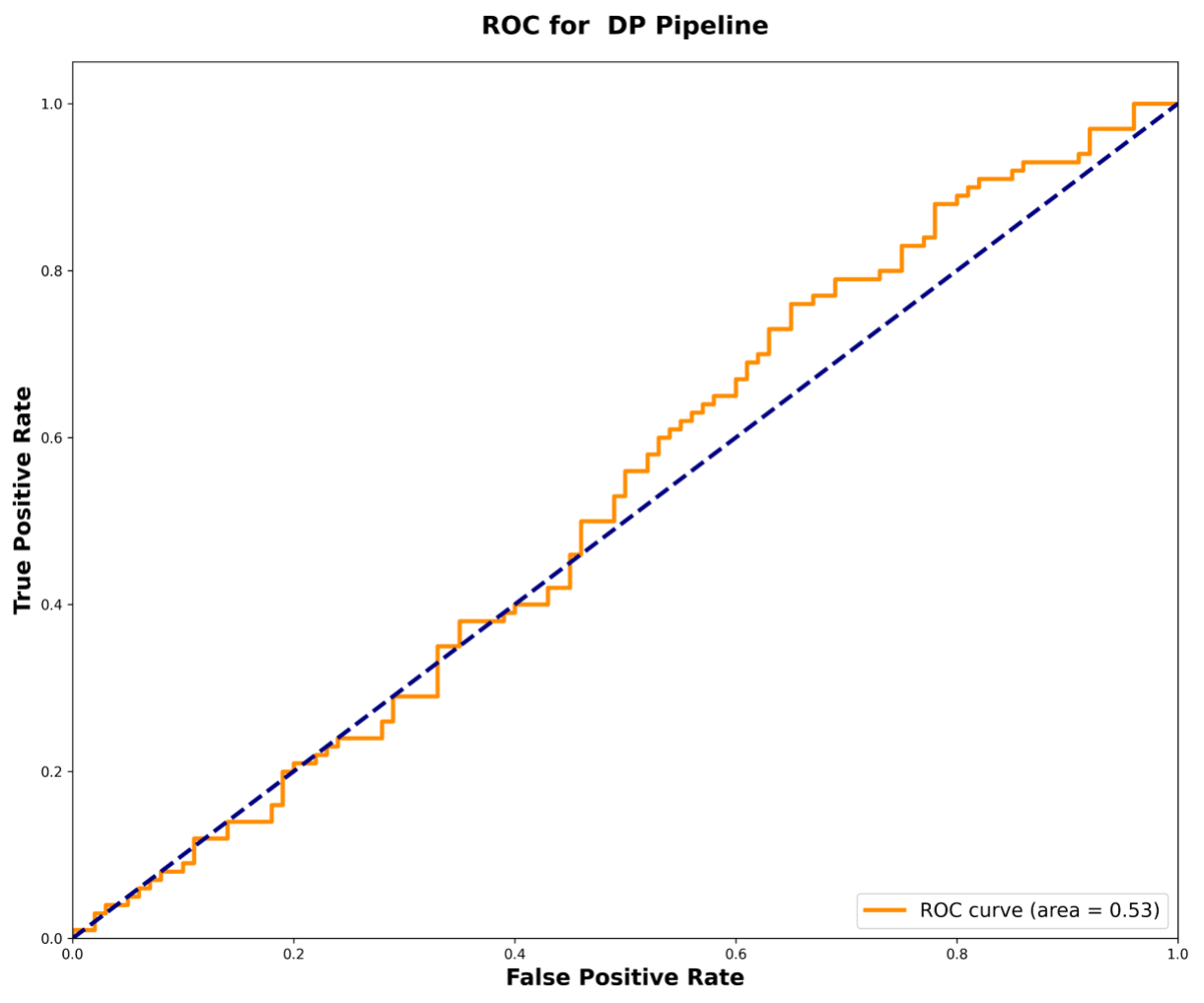
The ROC curve for DP pipeline shows performance close to random guessing (AUC = 0.53), demonstrating its robustness.
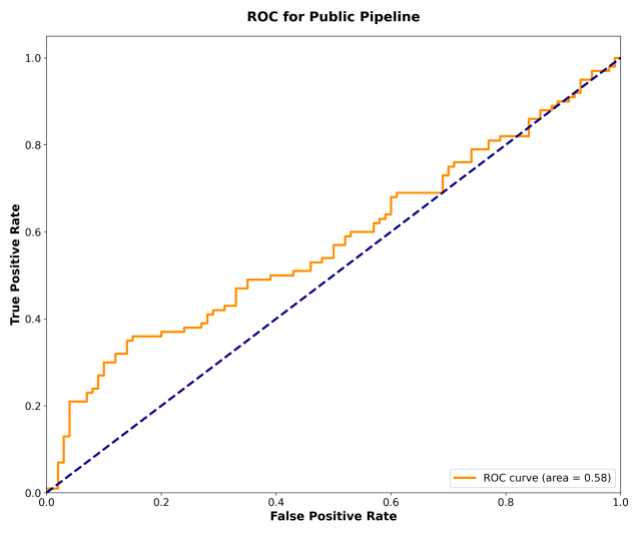
The ROC curve for the non-private pipeline is more vulnerable (AUC = 0.58).
Looking ahead
Our work is a first step toward building systems that can analyze large-scale text corpora with formal privacy guarantees. We've shown that it's possible to balance the need for meaningful insights with stringent user privacy.
Looking forward, we see several exciting avenues for future research. These include adapting the framework for online settings where new conversations are constantly added, exploring alternative DP mechanisms to further improve the utility-privacy trade-off, and adding support for multi-modal conversations (i.e., conversations involving images, videos, and audio).
As AI becomes more integrated into our daily lives, developing privacy-preserving methods for understanding its use is not just a technical challenge — it's a fundamental requirement for building trustworthy and responsible AI.
Acknowledgments
Thanks to all project contributors, whose essential efforts were pivotal to its success. Special thanks to our colleagues: Yaniv Carmel, Edith Cohen, Rudrajit Das, Chris Dibak, Vadym Doroshenko, Alessandro Epasto, Prem Eruvbetine, Dem Gerolemou, Badih Ghazi, Miguel Guevara, Steve He, Peter Kairouz, Pritish Kamath, Nir Kerem, Ravi Kumar, Ethan Leeman, Pasin Manurangsi, Shlomi Pasternak, Mikhail Pravilov, Adam Sealfon, Yurii Sushko, Da Yu, Chiyuan Zhang.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence