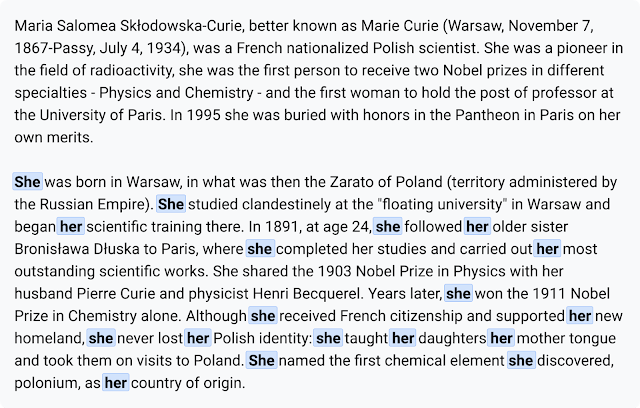A Dataset for Studying Gender Bias in Translation
June 24, 2021
Posted by Romina Stella, Product Manager, Google Translate
Quick links
Advances on neural machine translation (NMT) have enabled more natural and fluid translations, but they still can reflect the societal biases and stereotypes of the data on which they're trained. As such, it is an ongoing goal at Google to develop innovative techniques to reduce gender bias in machine translation, in alignment with our AI Principles.
One research area has been using context from surrounding sentences or passages to improve gender accuracy. This is a challenge because traditional NMT methods translate sentences individually, but gendered information is not always explicitly stated in each individual sentence. For example, in the following passage in Spanish (a language where subjects aren’t always explicitly mentioned), the first sentence refers explicitly to Marie Curie as the subject, but the second one doesn't explicitly mention the subject. In isolation, this second sentence could refer to a person of any gender. When translating to English, however, a pronoun needs to be picked, and the information needed for an accurate translation is in the first sentence.
| Spanish Text | Translation to English |
| Marie Curie nació en Varsovia. Fue la primera persona en recibir dos premios Nobel en distintas especialidades. | Marie Curie was born in Warsaw. She was the first person to receive two Nobel Prizes in different specialties. |
Advancing translation techniques beyond single sentences requires new metrics for measuring progress and new datasets with the most common context-related errors. Adding to this challenge is the fact that translation errors related to gender (such as picking the correct pronoun or having gender agreement) are particularly sensitive, because they may directly refer to people and how they self identify.
To help facilitate progress against the common challenges on contextual translation (e.g., pronoun drop, gender agreement and accurate possessives), we are releasing the Translated Wikipedia Biographies dataset, which can be used to evaluate the gender bias of translation models. Our intent with this release is to support long-term improvements on ML systems focused on pronouns and gender in translation by providing a benchmark in which translations’ accuracy can be measured pre- and post-model changes.
A Source of Common Translation Errors
Because they are well-written, geographically diverse, contain multiple sentences, and refer to subjects in the third person (and so contain plenty of pronouns), Wikipedia biographies offer a high potential for common translation errors associated with gender. These often occur when articles refer to a person explicitly in early sentences of a paragraph, but there is no explicit mention of the person in later sentences. Some examples:
| Translation Error | Text | Translation | ||
| Pro-drop in Spanish → English | Marie Curie nació en Varsovia. Recibió el Premio Nobel en 1903 y en 1911. | Marie Curie was born in Warsaw. He received the Nobel Prize in 1903 and in 1911. |
||
| Neutral possessives in Spanish → English | Marie Curie nació en Varsovia. Su carrera profesional fue desarrollada en Francia. | Marie Curie was born in Warsaw. His professional career was developed in France. |
||
| Gender agreement in English → German | Marie Curie was born in Warsaw. The distinguished scientist received the Nobel Prize in 1903 and in 1911. | Marie Curie wurde in Varsovia geboren. Der angesehene Wissenschaftler erhielt 1903 und 1911 den Nobelpreis. |
||
| Gender agreement in English → Spanish | Marie Curie was born in Warsaw. The distinguished scientist received the Nobel Prize in 1903 and in 1911. | Marie Curie nació en Varsovia. El distinguido científico recibió el Premio Nobel en 1903 y en 1911. | ||
Building the Dataset
The Translated Wikipedia Biographies dataset has been designed to analyze common gender errors in machine translation, such as those illustrated above. Each instance of the dataset represents a person (identified in the biographies as feminine or masculine), a rock band or a sports team (considered genderless). Each instance is represented by a long text translation of 8 to 15 connected sentences referring to that central subject (the person, rock band, or sports team). Articles are written in native English and have been professionally translated to Spanish and German. For Spanish, translations were optimized for pronoun-drop, so the same set could be used to analyze pro-drop (Spanish → English) and gender agreement (English → Spanish).
The dataset was built by selecting a group of instances that has equal representation across geographies and genders. To do this, we extracted biographies from Wikipedia according to occupation, profession, job and/or activity. To ensure an unbiased selection of occupations, we chose nine occupations that represented a range of stereotypical gender associations (either feminine, masculine, or neither) based on Wikipedia statistics. Then, to mitigate any geography-based bias, we divided all these instances based on geographical diversity. For each occupation category, we looked to have one candidate per region (using regions from census.gov as a proxy of geographical diversity). When an instance was associated with a region, we checked that the selected person had a relevant relationship with a country that belongs to a designated region (nationality, place of birth, lived for a big portion of their life, etc.). By using this criteria, the dataset contains entries about individuals from more than 90 countries and all regions of the world.
Although gender is non-binary, we focused on having equal representation of “feminine” and “masculine” entities. It's worth mentioning that because the entities are represented as such on Wikipedia, the set doesn't include individuals that identify as non-binary, as, unfortunately, there are not enough instances currently represented in Wikipedia to accurately reflect the non-binary community. To label each instance as "feminine" or "masculine" we relied on the biographical information from Wikipedia, which contained gender-specific references to the person (she, he, woman, son, father, etc.).
After applying all these filters, we randomly selected an instance for each occupation-region-gender triplet. For each occupation, there are two biographies (one masculine and one feminine), for each of the seven geographic regions.
Finally, we added 12 instances with no gender. We picked rock bands and sports teams because they are usually referred to by non-gendered third person pronouns (such as “it” or singular “they”). The purpose of including these instances is to study over triggering, i.e., when models learn that they are rewarded for producing gender-specific pronouns, leading them to produce these pronouns in cases where they shouldn't.
Results and Applications
This dataset enables a new method of evaluation for gender bias reduction in machine translations (introduced in a previous post). Because each instance refers to a subject with a known gender, we can compute the accuracy of the gender-specific translations that refer to this subject. This computation is easier when translating into English (cases of languages with pro-drop or neutral pronouns) since computation is mainly based on gender-specific pronouns in English. In these cases, the gender datasets have resulted in a 67% reduction in errors on context-aware models vs. previous models. As mentioned before, the neutral entities have allowed us to discover cases of over triggering like the usage of feminine or masculine pronouns to refer to genderless entities. This new dataset also enables new research directions into the performance of different models across types of occupations or geographic regions.
As an example, the dataset allowed us to discover the following improvements in an excerpt of the translated biography of Marie Curie from Spanish.
 |
| Translation result with the previous NMT model. |
 |
| Translation result with the new contextual model. |
Conclusion
This Translated Wikipedia Biographies dataset is the result of our own studies and work on identifying biases associated with gender and machine translation. This set focuses on a specific problem related to gender bias and doesn't aim to cover the whole problem. It's worth mentioning that by releasing this dataset, we don't aim to be prescriptive in determining what's the optimal approach to address gender bias. This contribution aims to foster progress on this challenge across the global research community.
Acknowledgements
The datasets were built with help from Anja Austermann, Melvin Johnson, Michelle Linch, Mengmeng Niu, Mahima Pushkarna, Apu Shah, Romina Stella, and Kellie Webster.
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets