A Dataset Exploration Case Study with Know Your Data
August 9, 2021
Posted by Mark Díaz and Emily Denton, Research Scientists, Google Research, Ethical AI Team
Quick links
Data underlies much of machine learning (ML) research and development, helping to structure what a machine learning algorithm learns and how models are evaluated and benchmarked. However, data collection and labeling can be complicated by unconscious biases, data access limitations and privacy concerns, among other challenges. As a result, machine learning datasets can reflect unfair social biases along dimensions of race, gender, age, and more.
Methods of examining datasets that can surface information about how different social groups are represented within are a key component of ensuring development of ML models and datasets is aligned with our AI Principles. Such methods can inform the responsible use of ML datasets and point toward potential mitigations of unfair outcomes. For example, prior research has demonstrated that some object recognition datasets are biased toward images sourced from North America and Western Europe, prompting Google’s Crowdsource effort to balance out image representations in other parts of the world.
Today, we demonstrate some of the functionality of a dataset exploration tool, Know Your Data (KYD), recently introduced at Google I/O, using the COCO Captions dataset as a case study. Using this tool, we find a range of gender and age biases in COCO Captions — biases that can be traced to both dataset collection and annotation practices. KYD is a dataset analysis tool that complements the growing suite of responsible AI tools being developed across Google and the broader research community. Currently, KYD only supports analysis of a small set of image datasets, but we’re working hard to make the tool accessible beyond this set.
Introducing Know Your Data
Know Your Data helps ML research, product and compliance teams understand datasets, with the goal of improving data quality, and thus helping to mitigate fairness and bias issues. KYD offers a range of features that allow users to explore and examine machine learning datasets — users can filter, group, and study correlations based on annotations already present in a given dataset. KYD also presents automatically computed labels from Google’s Cloud Vision API, providing users with a simple way to explore their data based on signals that weren’t originally present in the dataset.
A KYD Case Study
As a case study, we explore some of these features using the COCO Captions dataset, an image dataset that contains five human-generated captions for each of over 300k images. Given the rich annotations provided by free-form text, we focus our analysis on signals already present within the dataset.
Exploring Gender Bias
Previous research has demonstrated undesirable gender biases within computer vision datasets, including pornographic imagery of women and image label correlations that align with harmful gender stereotypes. We use KYD to explore gender biases within COCO Captions by examining gendered correlations within the image captions. We find a gender bias in the depiction of different activities across the images in the dataset, as well as biases relating to how people of different genders are described by annotators.
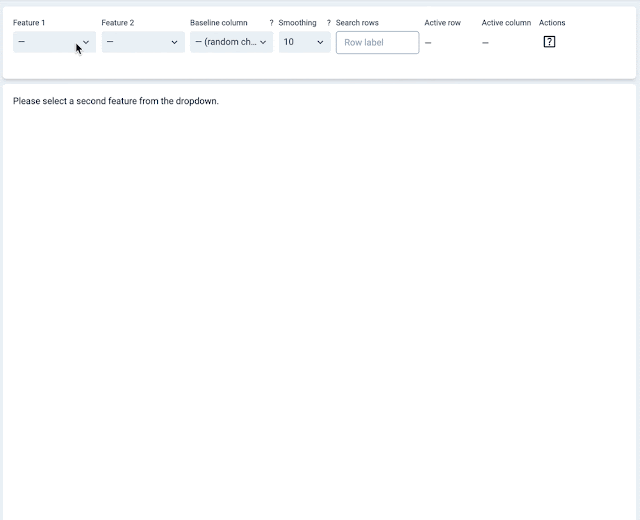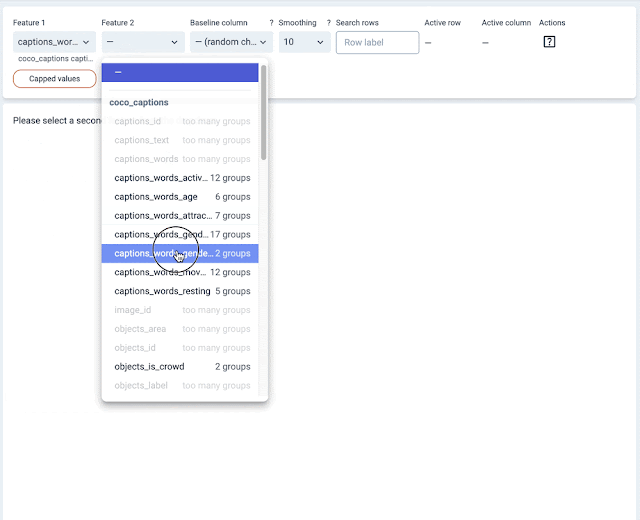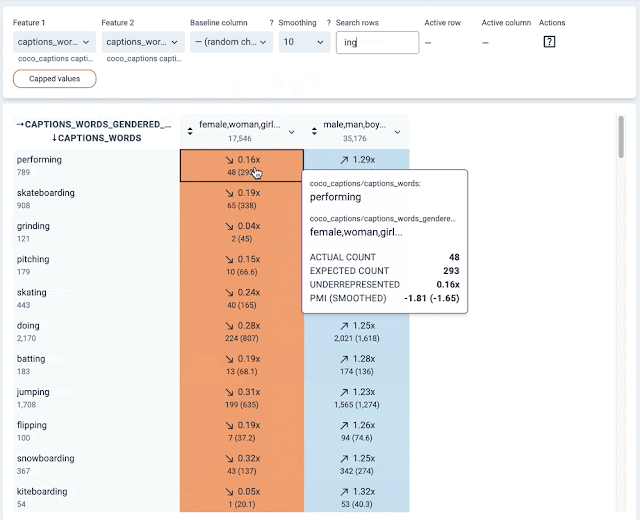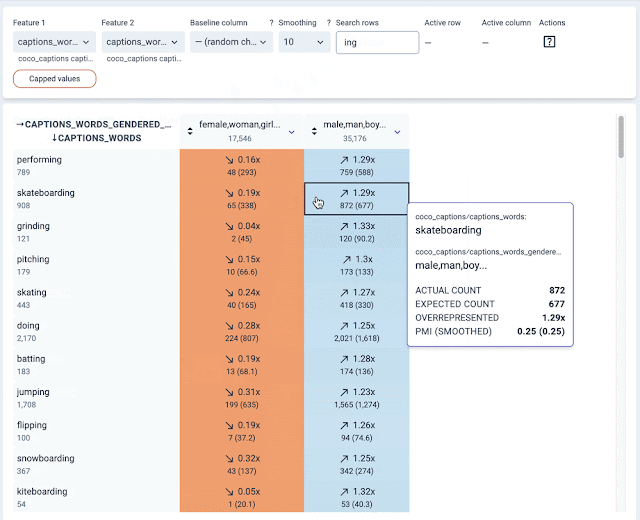
The first part of our analysis aimed to surface gender biases with respect to different activities depicted in the dataset. We examined images captioned with words describing different activities and analyzed their relation to gendered caption words, such as “man” or “woman”. Building upon recent work that leverages the PMI metric to measure associations learned by a model, the KYD relations tab makes it easy to examine associations between different signals in a dataset. This tab visualizes the extent to which two signals in the dataset co-occur more (or less) than would be expected by chance. Each cell indicates either a positive (blue color) or negative (orange color) correlation between two specific signal values along with the strength of that correlation.
KYD also allows users to filter rows of a relations table based on substring matching. Using this functionality, we initially probed for caption words containing “-ing”, as a simple way to filter by verbs. We immediately saw strong gendered correlations:
 |
| Using KYD to analyze the relationship between any word and gendered words. Each cell shows if the two respective words co-occur in the same caption more (up arrow) or less often (down arrow) than pure chance. |
Digging further into these correlations, we found that several activities stereotypically associated with women, such as “shopping” and “cooking”, co-occur with images captioned with “women” or “woman” at a higher rate than with images captioned with “men” or “man”. In contrast captions describing many physically intensive activities, such as “skateboarding”, “surfing”, and “snowboarding”, co-occur with images captioned with “man” or “men” at higher rates.
While individual image captions may not use stereotypical or derogatory language, such as with the example below, if certain gender groups are over (or under) represented within a particular activity across the whole dataset, models developed from the dataset risk learning stereotypical associations. KYD makes it easy to surface, quantify, and make plans to mitigate this risk.
 |
| An image with one of the captions: “Two women cooking in a beige and white kitchen.” Image licensed under CC-BY 2.0. |
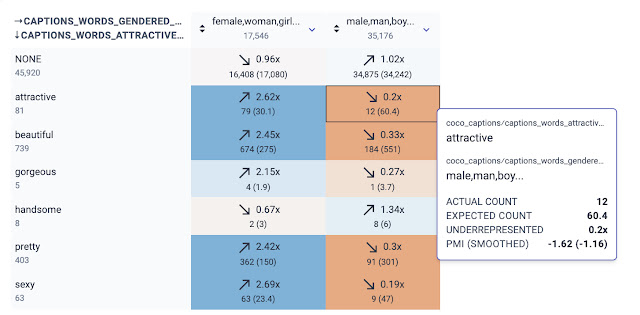
In addition to examining biases with respect to the social groups depicted with different activities, we also explored biases in how annotators described the appearance of people they perceived as male or female. Inspired by media scholars who have examined the “male gaze” embedded in other forms of visual media, we examined the frequency with which individuals perceived as women in COCO are described using adjectives that position them as an object of desire. KYD allowed us to easily examine co-occurrences between words associated with binary gender (e.g. "female/girl/woman" vs. "male/man/boy") and words associated with evaluating physical attractiveness. Importantly, these are captions written by human annotators, who are making subjective assessments about the gender of people in the image and choosing a descriptor for attractiveness. We see that the words "attractive", "beautiful", "pretty", and "sexy" are overrepresented in describing people perceived as women as compared to those perceived as men, confirming what prior work has said about how gender is viewed in visual media.
 |
| A screenshot from KYD showing the relationship between words that describe attractiveness and gendered words. For example, “attractive” and “male/man/boy” co-occur 12 times, but we expect ~60 times by chance (the ratio is 0.2x). On the other hand, “attractive” and “female/woman/girl” co-occur 2.62 times more than chance. |
KYD also allows us to manually inspect images for each relation by clicking on the relation in question. For example, we can see images whose captions include female terms (e.g. “woman”) and the word “beautiful”.
Exploring Age Bias
Adults older than 65 have been shown to be underrepresented in datasets relative to their presence in the general population — a first step toward improving age representation is to allow developers to assess it in their datasets. By looking at caption words describing different activities and analyzing their relation to caption words describing age, KYD helped us to assess the range of example captions depicting older adults. Having example captions of adults in a range of environments and activities is important for a variety of tasks, such as image captioning or pedestrian detection.
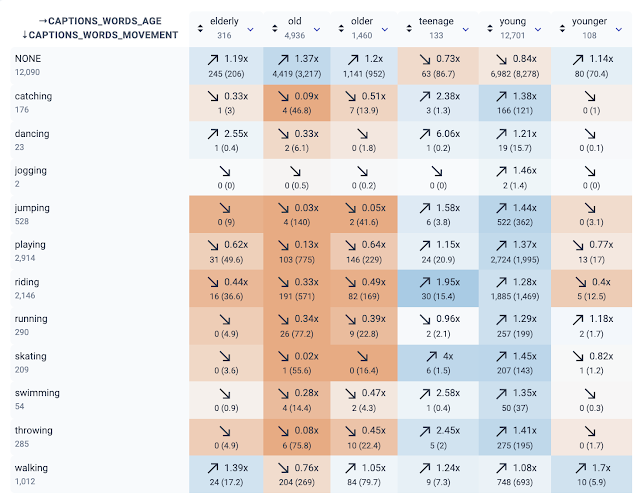
The first trend that KYD made clear is how rarely annotators described people as older adults in captions detailing different activities. The relations tab also shows a trend wherein “elderly”, “old”, and “older” tend not to occur with verbs that describe a variety of physical activities that might be important for a system to be able to detect. Important to note is that, relative to “young”, “old” is more often used to describe things other than people, such as belongings or clothing, so these relations are also capturing some uses that don’t describe people.
 |
| The relationship between words associated with age and movement from a screenshot of KYD. |
The underrepresentation of captions containing the references to older adults that we examined here could be rooted in a relative lack of images depicting older adults as well as in a tendency for annotators to omit older age-related terms when describing people in images. While manual inspection of the intersection of “old” and “running” shows a negative relation, we notice that it shows no older people and a number of locomotives. KYD makes it easy to quantitatively and qualitatively inspect relations to identify dataset strengths and areas for improvement.
Conclusion
Understanding the contents of ML datasets is a critical first step to developing suitable strategies to mitigate the downstream impact of unfair dataset bias. The above analysis points towards several potential mitigations. For example, correlations between certain activities and social groups, which can lead trained models to reproduce social stereotypes, can be potentially mitigated by “dataset balancing” — increasing the representation of under-represented group/activity combinations. However, mitigations focused exclusively on dataset balancing are not sufficient, as our analysis of how different genders are described by annotators demonstrated. We found annotators’ subjective judgements of people portrayed in images were reflected within the final dataset, suggesting a deeper look at methods of image annotations are needed. One solution for data practitioners who are developing image captioning datasets is to consider integrating guidelines that have been developed for writing image descriptions that are sensitive to race, gender, and other identity categories.
The above case studies highlight only some of the KYD features. For example, Cloud Vision API signals are also integrated into KYD and can be used to infer signals that annotators haven't labeled directly. We encourage the broader ML community to perform their own KYD case studies and share their findings.
KYD complements other dataset analysis tools being developed across the ML community, including Google's growing Responsible AI toolkit. We look forward to ML practitioners using KYD to better understand their datasets and mitigate potential bias and fairness concerns. If you have feedback on KYD, please write to knowyourdata-feedback@google.com.
Acknowledgements
The analysis and write-up in this post were conducted with equal contribution by Emily Denton, Mark Díaz, and Alex Hanna. We thank Marie Pellat, Ludovic Peran, Daniel Smilkov, Nikhil Thorat and Tsung-Yi for their contributions to and reviews of this post. We also thank the researchers and teams that have developed the signals and metrics used in KYD and particularly the team that has helped us implement nPMI.
Quick links