A Billion Words: Because today's language modeling standard should be higher
April 30, 2014
Posted by Dave Orr, Product Manager, and Ciprian Chelba, Research Scientist
Quick links
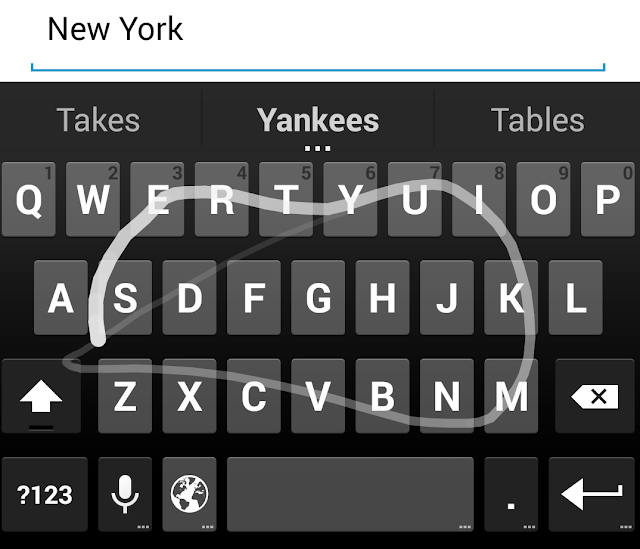
Language is chock full of ambiguity, and it can turn up in surprising places. Many words are hard to tell apart without context: most Americans pronounce “ladder” and “latter” identically, for instance. Keyboard inputs on mobile devices have a similar problem, especially for IME keyboards. For example, the input patterns for “Yankees” and “takes” look very similar:
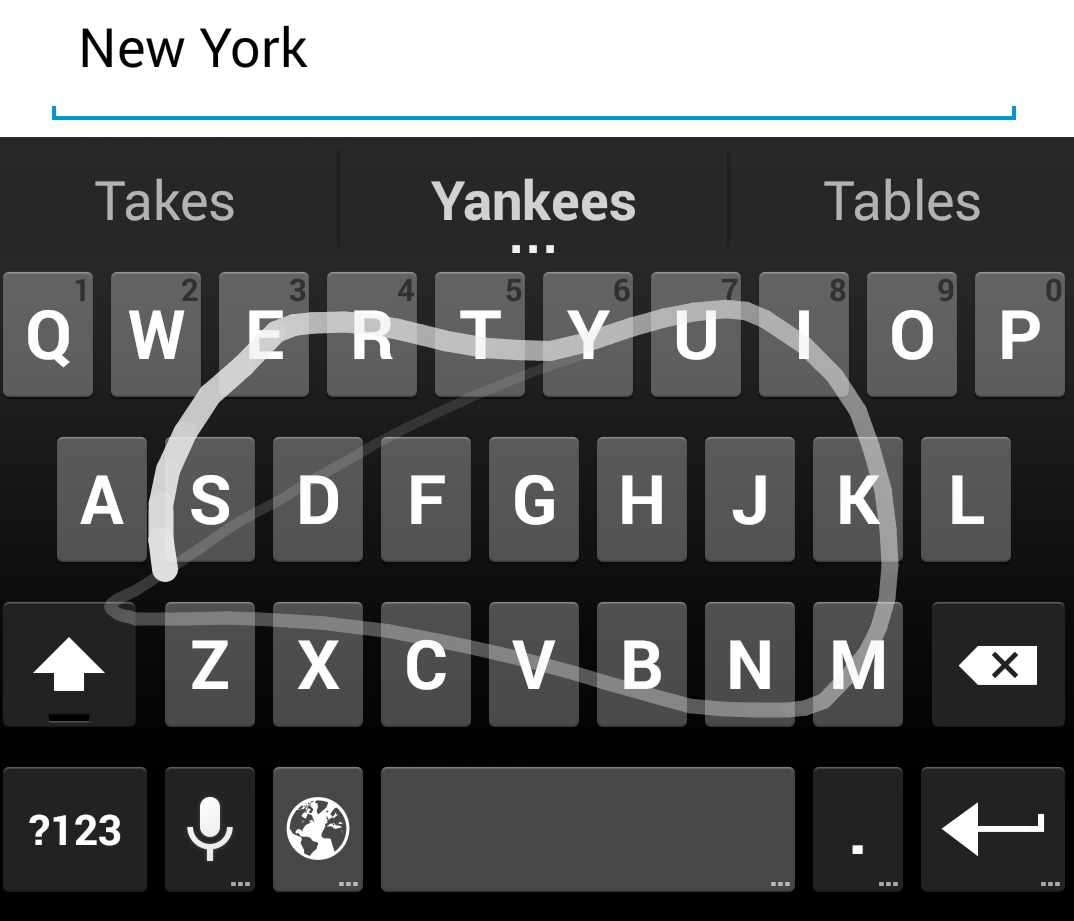 |
| Photo credit: Kurt Partridge |
But in this context -- the previous two words, “New York” -- “Yankees” is much more likely.
One key way computers use context is with language models. These are used for predictive keyboards, but also speech recognition, machine translation, spelling correction, query suggestions, and so on. Often those are specialized: word order for queries versus web pages can be very different. Either way, having an accurate language model with wide coverage drives the quality of all these applications.
Due to interactions between components, one thing that can be tricky when evaluating the quality of such complex systems is error attribution. Good engineering practice is to evaluate the quality of each module separately, including the language model. We believe that the field could benefit from a large, standard set with benchmarks for easy comparison and experiments with new modeling techniques.
To that end, we are releasing scripts that convert a set of public data into a language model consisting of over a billion words, with standardized training and test splits, described in an arXiv paper. Along with the scripts, we’re releasing the processed data in one convenient location, along with the training and test data. This will make it much easier for the research community to quickly reproduce results, and we hope will speed up progress on these tasks.
The benchmark scripts and data are freely available, and can be found here: http://www.statmt.org/lm-benchmark/
The field needs a new and better standard benchmark. Currently, researchers report from a set of their choice, and results are very hard to reproduce because of a lack of a standard in preprocessing. We hope that this will solve both those problems, and become the standard benchmark for language modeling experiments. As more researchers use the new benchmark, comparisons will be easier and more accurate, and progress will be faster.
For all the researchers out there, try out this model, run your experiments, and let us know how it goes -- or publish, and we’ll enjoy finding your results at conferences and in journals.
Quick links
Other posts of interest
-

June 26, 2026
Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction- Machine Intelligence ·
- Mobile Systems ·
- Natural Language Processing
-

June 24, 2026
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

June 5, 2026
Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG- Data Management ·
- Machine Intelligence ·
- Natural Language Processing ·
- Product