
Pre-translation vs. direct inference in multilingual LLM applications
June 14, 2024
Roman Goldenberg, Research Scientist, Verily AI, and Natalie Aizenberg, Research Software Engineer, Google Research & Verily AI
Quick links
Large language models (LLMs) are becoming omnipresent tools for solving a wide range of problems. However, their effectiveness in handling diverse languages has been hampered by inherent limitations in training data, which are often skewed towards English. To address this, pre-translation, where inputs are translated to English before feeding them to the LLM, has become a standard practice.
Previous research has demonstrated the effectiveness of pre-translation for optimal LLM performance for GPT-3/3.5/4, ChatGPT, PaLM and other models. While pre-translation helps address the language bias issue, it introduces complexities and inefficiencies, and it may lead to information loss. With the introduction of new powerful LLMs trained on massive multilingual datasets, it is time to revisit the assumed necessity of pre-translation.
In our recent work “Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?”, to be presented at NAACL’24, we re-evaluate the need for pre-translation using PaLM2, which has been established as highly performant in multilingual tasks. Our findings challenge the pre-translation paradigm established in prior research and highlight the advantages of direct inference in PaLM2. Specifically, we demonstrate that PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages, offering a more efficient and effective application in multilingual settings while unlocking linguistic authenticity and alleviating the limitations of pre-translation.
Rethinking multilingual LLM evaluation
Prior research on evaluating the impact of pre-translation mainly focused on discriminative (close-ended) tasks, such as multiple choice question answering (QA), for which the language of the answer is mostly insignificant. For evaluating generative (open-ended) tasks, such as text summarization or attributed QA, the output needs to be in the source language to compare it to the ground truth (GT). This requires adding an extra post-inference translation step. While for source language inference evaluation (a in the figure below), inference is directly compared to GT in the source language, for pre-translation evaluation (b), LLM inference is translated back to source language (c.1).
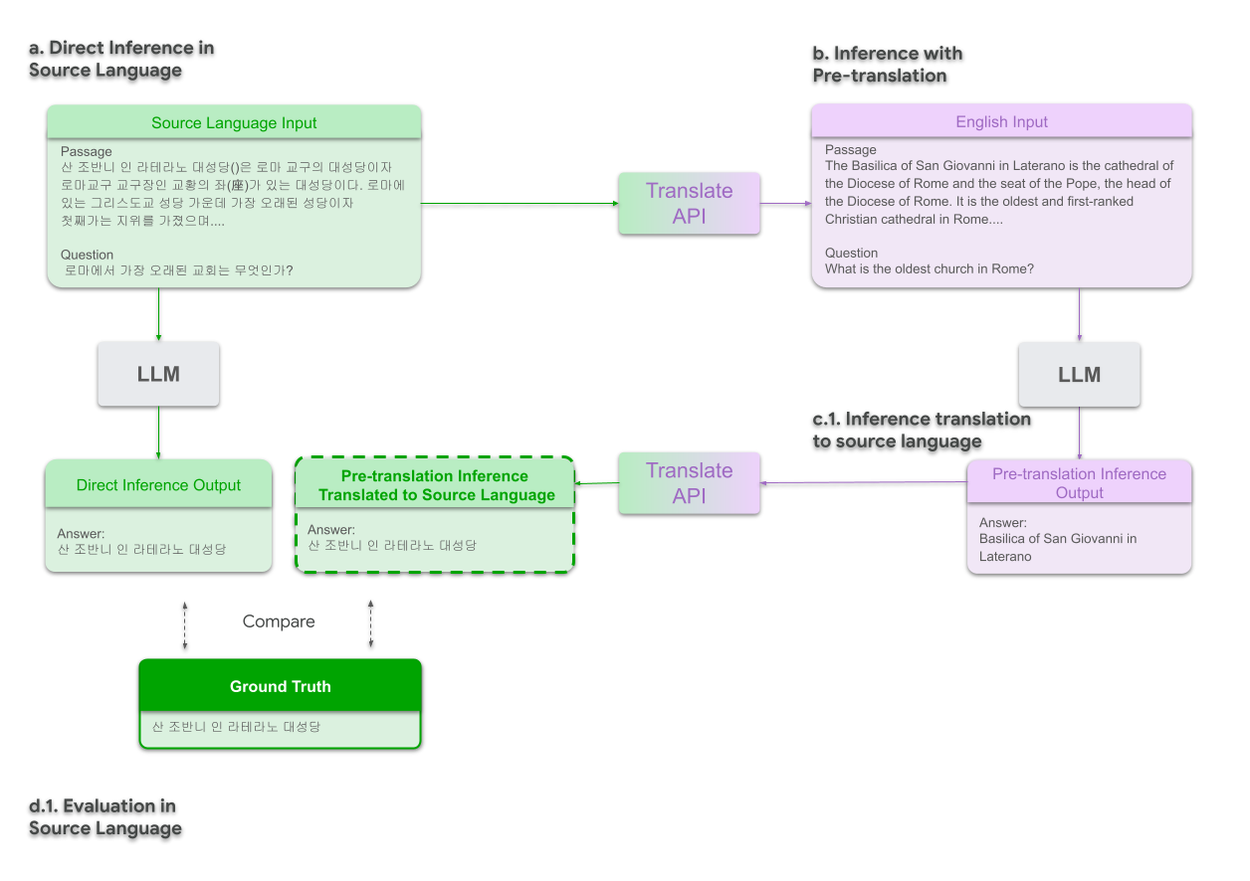
Comparative evaluation of direct inference vs. pre-translation in source language.
One of the drawbacks of this evaluation scheme is that comparing model output to GT in different languages using standard lexical metrics, such as ROUGE and F1, is language dependent and introduces inconsistencies. Another problem with this approach is that GT answers in open-ended tasks rely primarily on information present within the provided context. Specifically, in reading comprehension Q&A benchmarks, it is common to have the GT be a substring of the original context. This presents a potential disadvantage for pre-translation, which lacks access to the original context from which the GT was extracted.
To address both these caveats, we perform a complimentary evaluation in English by translating the GT and direct inference results to English. Here, instead of translating the pre-translated inference back to source language, we translate the direct inference output and GT to English (as illustrated below in panels c.2 and c.3, respectively). Then the evaluation against GT is performed in English.
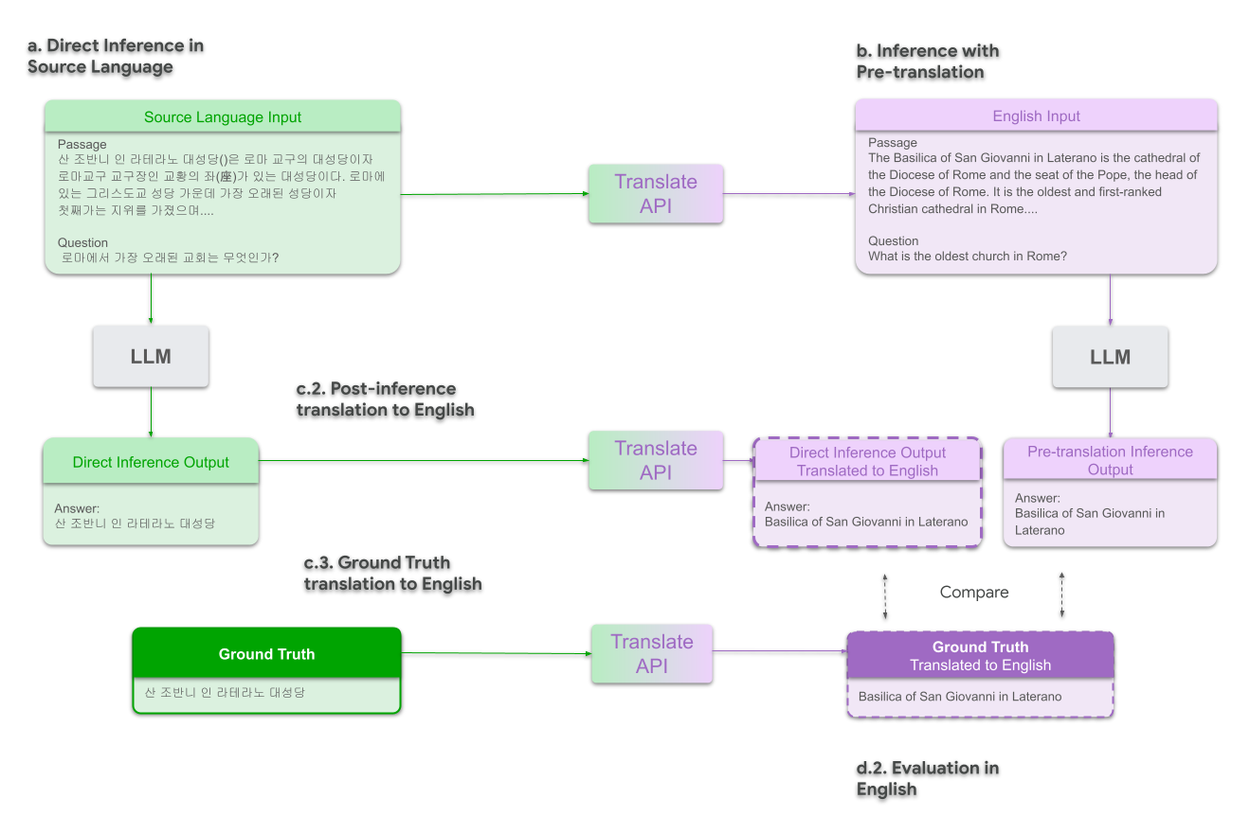
Comparative evaluation of direct inference vs. pre-translation in English.
In addition, we found that averaging LLM accuracy metrics across languages, as done in the prior approaches, can be misleading, masking crucial details. To gain a more nuanced understanding, we introduced the Language Ratio metric as an alternative aggregation over commonly used lexical metrics. It is defined as the percentage of languages for which direct inference yields better results than pre-translation.
The Language Ratio can be computed for any accuracy score of choice (such as F1 or Rouge) over a single inference mode (direct and pre-translation) and language. By inspecting the proportion of languages where one method outperforms the other, rather than averaging language bias scores, a fairer overall comparison and more detailed understanding of relative strengths and weaknesses across languages is possible.
Direct inference takes the lead
Our analysis encompassed a variety of tasks and languages. We employed six publicly available benchmarks to evaluate PaLM2's performance in both discriminative (XCOPA, XStoryCLoze and BeleBele benchmarks) and generative tasks (XLSum, TyDiQA-GP and XQuAD) across 108 languages. Two variants of PaLM2 were evaluated: PaLM2-S (Small - Bison) and PaLM2-L (Large - Unicorn), while using Google Translation API for pre- and post-translation.
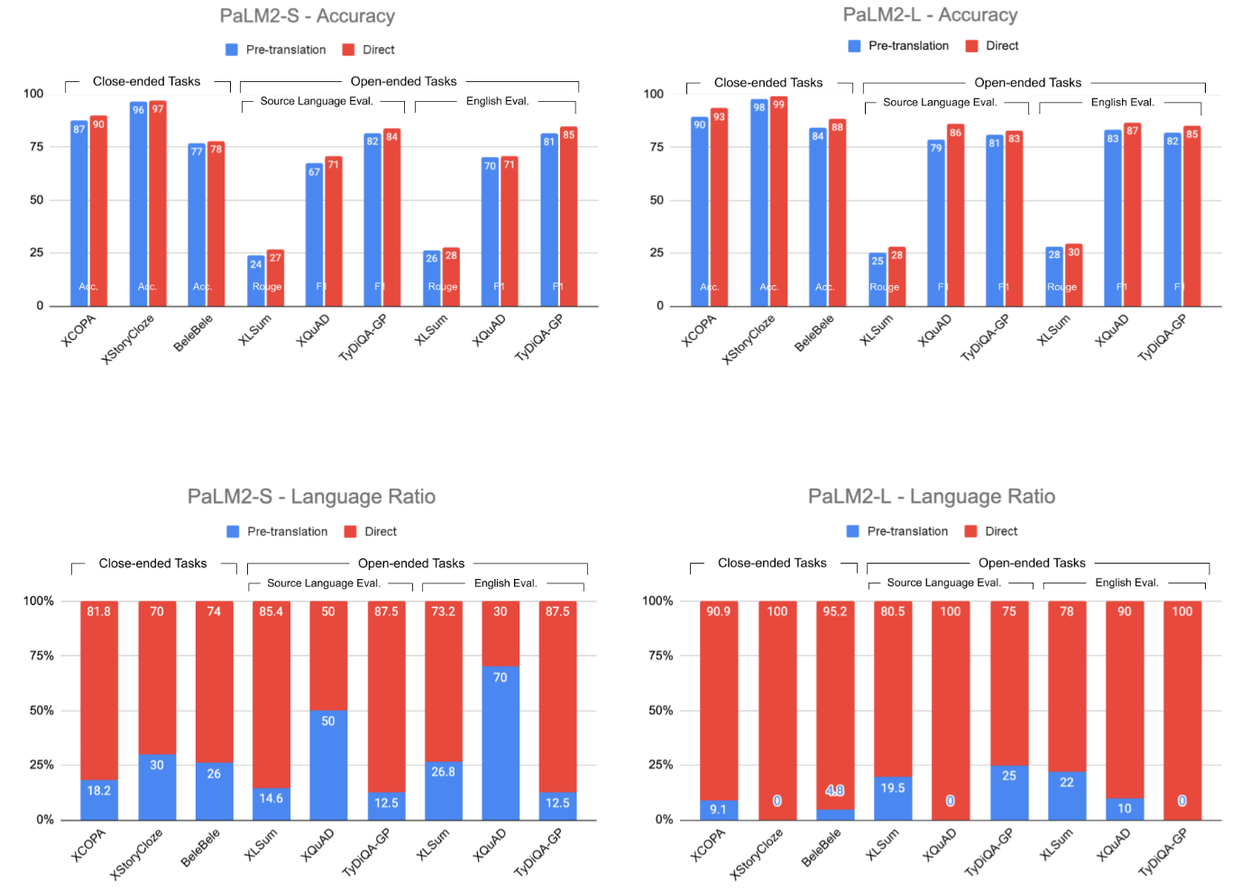
PaLM2-S (left) and PaLM2-L (right) evaluation results, comparing pre-translation (blue) and direct inference (red). Model performance for generative (open-ended) tasks is evaluated both in the source language and in English. Top: Accuracy metrics (accuracy, Rouge-L, F1) measured on various benchmarks. Bottom: Language Ratio metric.
The results were strikingly different from those reported in prior literature for other models.
- PaLM2-L consistently achieved better performance with direct inference in 94 out of 108 languages evaluated. The advantage was observed for both close- and open-ended tasks, on all benchmarks. The results were consistent across all evaluations — in source language and in English, using standard metrics (Accuracy/F1/Rouge) and the Language Ratio.
- PaLM2-S also favors direct inference in all but the XQuAD benchmark, where the result is less conclusive. Better average F1 score is achieved using direct inference (due to significant improvements in Chinese and Thai), but the Language Ratio is better for pre-translation, which emphasizes the complimentary value of this metric.
- Direct inference yielded superior results even in low-resource languages (LRL). This is particularly significant for fostering communication and information access in under-represented languages.
Language-focused analysis
While PaLM2-L clearly performs better using direct inference for the majority of languages, pre-translation shows consistent superiority (across benchmarks) for 7 languages: Bambara, Cusco-Collao Quechua, Lingala, Oromo, Punjabi, Tigrinya, and Tsonga. All 7 are LRL, 4 out of 7 are African, with Lingala, the largest, spoken by over 40 million people. Interestingly, the majority (85%) of LRL benefit from direct inference with PaLM2.
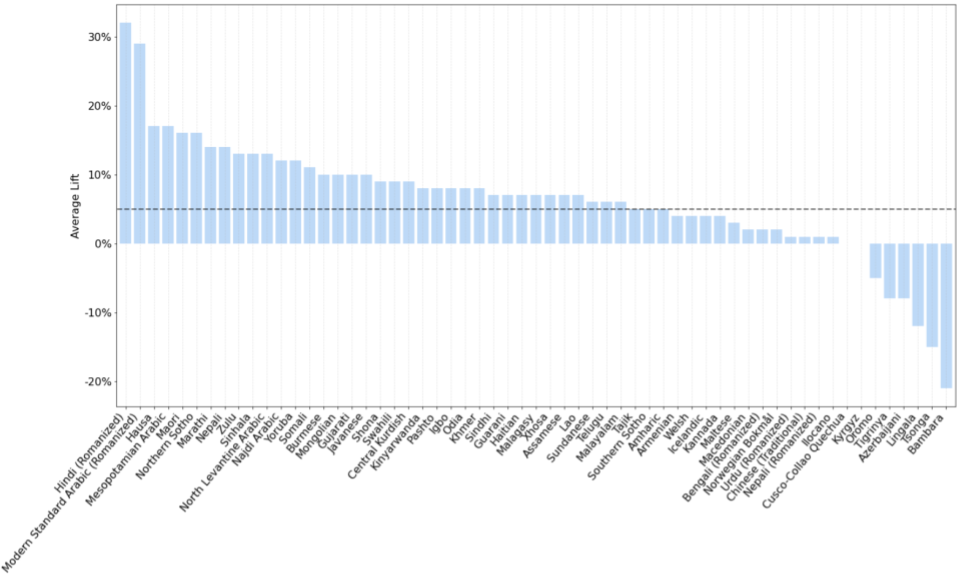
PaLM2-L average direct inference Lift over pre-translate inference on LRL. The majority of languages (over 85%) benefit from direct inference with PaLM2, with lifts exceeding 5% (dashed line) in 63% of languages.
The future of multilingual communication
The comprehensive comparative analysis we performed in this study suggests that the new generation of LLMs, trained on massive multilingual datasets, can better handle information and communication across languages, eliminating the need for pre-translation for certain languages.
We are committed to ongoing research in this area, focusing on improving LLM performance for all languages and fostering a more inclusive future for multilingual communication.
Acknowledgements
The research described here is a joint work of Verily AI and Google Research. We would like to thank all our paper co-authors: Yotam Intrator, Matan Halfon, Reut Tsarfaty, Matan Eyal, Ehud Rivlin, and Yossi Matias. We are grateful to Avi Caciularu for reviewing and providing comments on the manuscript.
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum

PaLM2-L average direct inference Lift over pre-translate inference on LRL. The majority of languages (over 85%) benefit from direct inference with PaLM2, with lifts exceeding 5% (dashed line) in 63% of languages.

Comparative evaluation of direct inference vs. pre-translation in source language.

PaLM2-S (left) and PaLM2-L (right) evaluation results, comparing pre-translation (blue) and direct inference (red). Model performance for generative (open-ended) tasks is evaluated both in the source language and in English. Top: Accuracy metrics (accuracy, Rouge-L, F1) measured on various benchmarks. Bottom: Language Ratio metric.
Comparative evaluation of direct inference vs. pre-translation in English.