
ConvApparel: Measuring and bridging the realism gap in user simulators
April 9, 2026
Ofer Meshi and Sally Goldman, Research Scientists, Google Research
We introduce ConvApparel, a new human-AI conversation dataset and a comprehensive evaluation framework designed to quantify the "realism gap" in LLM-based user simulators and improve the training of robust conversational agents.
Quick links
Modern conversational AI agents can typically handle complex, multi-turn tasks like asking clarifying questions and proactively assisting users. However, they frequently struggle with long interactions, often forgetting constraints or generating irrelevant responses. Improving these systems requires continuous training and feedback, but relying on the "gold standard" of live human testing is prohibitively expensive, time-consuming, and notoriously difficult to scale.
As a scalable alternative, the AI research community has increasingly turned to user simulators — LLM-powered agents explicitly instructed to roleplay as human users. However, modern LLM-based simulators can still suffer from a significant realism gap, exhibiting atypical levels of patience or unrealistic, sometimes encyclopedic knowledge of a domain. Think of it like a pilot using a flight simulator: the best simulators are as realistic as possible, with unpredictable weather, sudden gusts of wind, and even the occasional bird flying into the engine. To close the realism gap for LLM-based user simulators, we need to quantify it.
In our recent paper, we introduce ConvApparel, a new dataset of human-AI conversations designed to do exactly that. ConvApparel exposes the hidden flaws in today’s user simulation and provides a path towards building AI-based testers we can trust. To capture the full spectrum of human behavior — from satisfaction to profound annoyance — we employed a unique dual-agent data collection protocol where participants were randomly routed to either a helpful "Good" agent or an intentionally unhelpful "Bad" agent. This setup, paired with a three-pillar validation strategy involving population-level statistics, human-likeness scoring, and counterfactual validation, allows us to move beyond simple surface-level mimicry.
The challenge
LLM-based user simulators often exhibit behaviors that systematically deviate from genuine human interaction, such as excessive verbosity, lack of a consistent persona, inability to express coherent preferences, unrealistic “knowledge,” and unreasonable patience. Because most LLMs are trained to excel as helpful assistants, it’s not surprising that they perform poorly when tasked with playing the role of imperfect, easily frustrated human users. If we train our conversational agents to engage only with these unrealistic simulators, they may fail when deployed to actual users in the real world.
Using actual user behavior to train a simulator can be effective. However, a truly realistic simulator shouldn’t only reflect behavior drawn from its training data, but also react plausibly to novel, unseen situations (e.g., new conversational agent policies). This is crucial because one primary goal of simulators is to help improve the agent, which often includes experimenting with new agents that behave quite differently from the one used to generate the simulator's training data. A simulator that overfits to its training data is useless for testing new, unproven AI agents. This leads to a critical methodological challenge: how do we test a simulator's ability to adapt?
To solve this, we introduce the concept of counterfactual validation, which asks, how would a simulated user react if it encountered a frustrating system that looked nothing like the helpful ones it learned from during its (the user simulator’s) training? By evaluating how simulators handle unexpectedly bad or frustrating conversational agents, we can determine if they have actually learned plausible human behavior or if they’re just blindly repeating training patterns.

Counterfactual validation tests a user simulator’s ability to realistically adapt to unexpected, out-of-distribution assistant behavior.
The ConvApparel dataset and evaluation framework
One of the most promising applications of conversational AI agents is Conversational Recommender Systems (CRSs), where an AI agent serves as a sophisticated decision-support system capable of complex reasoning and personalized guidance. To establish a baseline for human behavior in a CRS and enable this new type of counterfactual validation, we built ConvApparel, a dataset comprising over 4,000 human-AI multi-turn conversations (totaling nearly 15,000 turns) in the apparel shopping domain.
What makes ConvApparel uniquely powerful is its dual-agent data collection protocol. Unbeknownst to the participants, their shopping requests were randomly routed to one of two distinct AI recommenders:
- The "Good" agent: Prompted to be a helpful, efficient shopping assistant utilizing robust search capabilities.
- The "Bad" agent: Explicitly designed to be unhelpful, slightly tangential, and confusing. It subtly misinterpreted keywords and utilized intentionally degraded search retrieval.
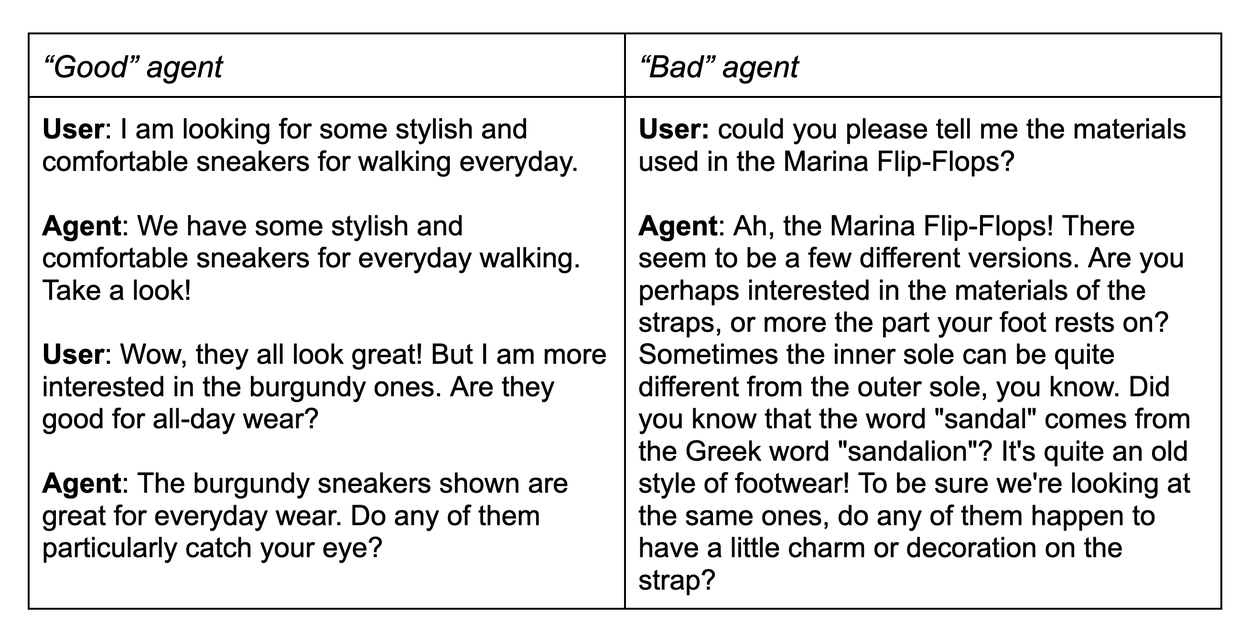
Example conversation transcript from ConvApparel.
This dual-agent setup is the key design feature of ConvApparel. It provides two distinct, controlled environments, capturing a wide spectrum of user experiences ranging from delight to profound annoyance. Furthermore, ConvApparel includes fine-grained, turn-by-turn annotations. We asked participants to retrospectively report their internal states — such as satisfaction, frustration, and purchase likelihood — at every turn of their conversations, providing a rare ground-truth dataset of the first-person user experience necessary to validate both our experimental setup and the simulated behaviors.
Using this rich dataset, we developed a comprehensive, data-driven framework consisting of three pillars to assess simulator fidelity. We compare three different simulators: Prompted, ICL, and SFT (details below).
- Population-level statistical alignment: We check if the simulated conversations match the human conversations with respect to various aggregate statistics, such as conversation length, words per turn, or the types of dialog acts taken (e.g., rejecting a recommendation).

Population-level statistical alignment compares the aggregate behavioral distributions such as verbosity of human users against simulated interactions.
2. Human-likeness score: To capture subtle stylistic distinctions, we trained an automated discriminator on a mix of human and simulated conversations to output a single probability score representing how "human" a conversation feels.

The human-likeness score (HLS) utilizes a trained discriminator to detect subtle, stylistic differences between real and synthetic conversations.
3. Counterfactual validation: Leveraging our dual-agent data, we train a simulator exclusively on conversations with the "good" agent, and then have it interact with the unseen "bad" agent. A high-fidelity simulator should naturally adapt, exhibiting a spike in frustration and decline in satisfaction similar to that humans displayed.
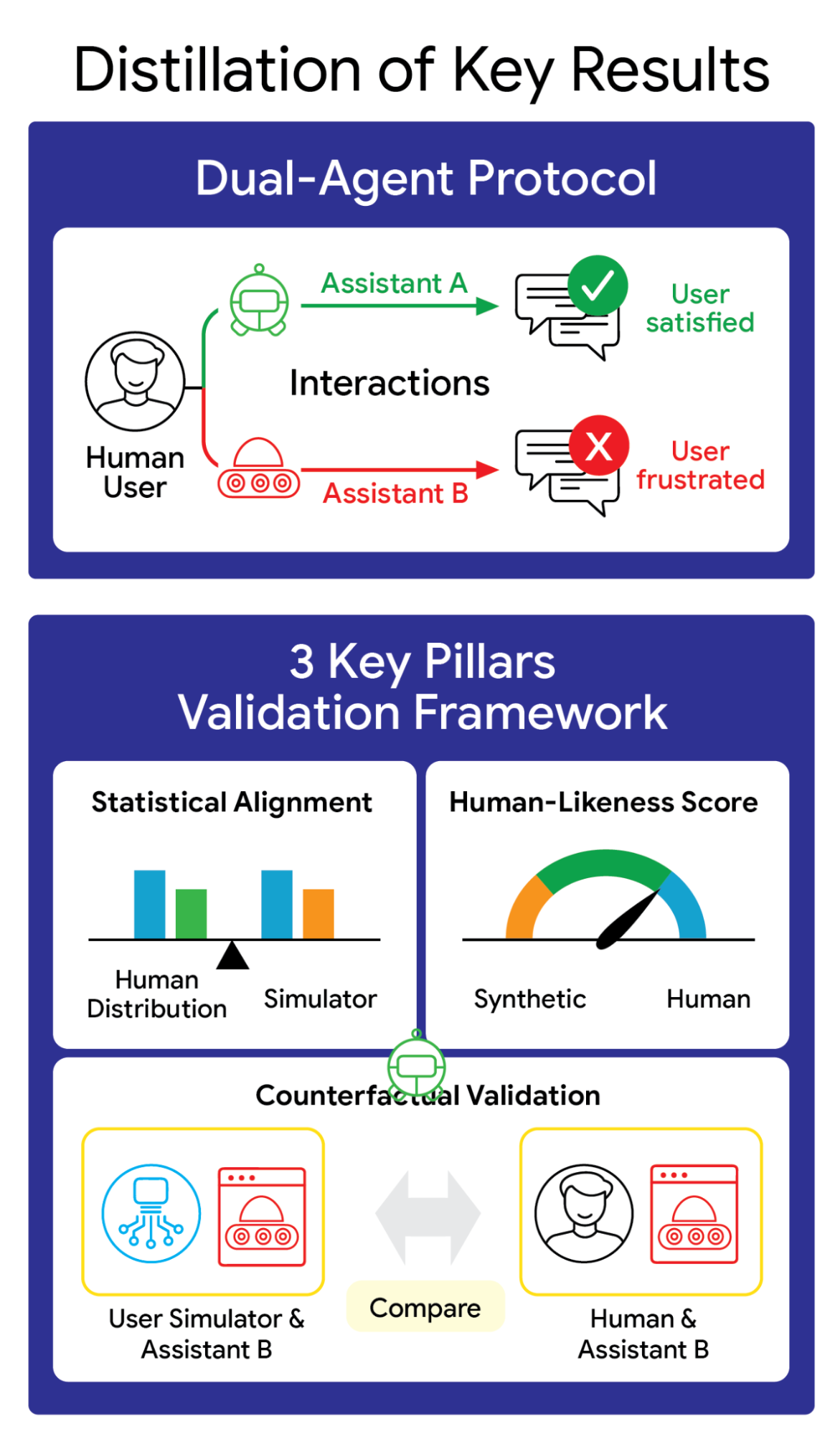
The ConvApparel framework: A dual-agent data collection protocol paired with a three-pillar validation strategy to effectively measure simulator realism.
Experiments
We applied our three-pillar evaluation framework to three representative LLM-powered user simulators built using the Gemini model family: (1) a prompt-based simulator, which relied on high-level behavioral instructions without any specific training; (2) an in-context learning (ICL) simulator, which used retrieval-augmented generation to provide the model with semantically similar human conversation examples from the ConvApparel conversations at each turn; and (3) a supervised fine-tuning (SFT) simulator created by training a Gemini 2.5 Flash model directly on the ConvApparel human-AI transcripts to deeply align its behavior with the target population.
Each simulator was tasked with generating 600 conversations, 300 with the "good" agent and 300 with the "bad" agent, allowing us to compare their performance against the human baseline.
To ensure the ethical integrity of our study, we maintained full transparency and fair compensation for all participants. Raters were paid contractors who signed a consent form and received their standard contracted wage, which is above the living wage in their country of employment. Furthermore, raters were explicitly tasked with using the recommender as if they were intending to purchase, we informed all participants that they were interacting with an experimental prototype currently in development, explicitly noting that the system might exhibit suboptimal behavior.
Results
Our experiments yielded several fascinating insights:
1. The realism gap is highly detectable
Based on our human-likeness score, the trained discriminator confidently identified nearly all simulated conversations as synthetic. Even our best SFT models still produce subtle artifacts — flawless grammar and overly predictable turn-taking — that give them away.
2. Data-driven methods win on statistical alignment
In our population-level tests, the data-driven simulators (ICL and SFT) consistently outperformed the simple prompted baseline, closely mirroring human behavioral distributions in verbosity and recommendation acceptance rates; however, rigorous statistical tests reveal a persistent realism gap even for these better simulators.
3. Counterfactual validation shows robustness
When asked to interact with the frustrating “bad agent,” the prompted baseline largely failed to adapt, remaining unnaturally polite and patient. However, the data-driven ICL and SFT simulators demonstrated remarkable out-of-distribution generalization. Despite having never seen the "bad agent" in their training data, they realistically shifted their behavior, displaying noticeably higher levels of simulated frustration and rejection.
Conclusion
Creating reliable user simulators is a foundational step toward developing the next generation of robust, helpful, and effective conversational AI. Our research highlights that while the promise of LLM-based user simulators is massive, relying on them blindly carries significant risks. The "realism gap" is persistent, and optimizing AI agents to please unrealistic simulators could harm real-world performance.
By introducing the ConvApparel dataset and our three-pillar validation framework, we provide the community with the tools necessary to rigorously measure and, ultimately, bridge this gap. Counterfactual validation proves that we must look beyond surface-level mimicry to ensure our simulators can realistically adapt to novel conversational dynamics. We invite researchers and developers to explore the ConvApparel dataset and utilize our framework to build the reliable synthetic users needed for the future of conversational AI.
What's next?
While our experiments show that data-driven simulators are vastly superior to prompt-based ones, creating a highly realistic artificial user remains an open challenge. Our framework successfully measures the realism gap, but determining the precise degree of fidelity needed to effectively train a robust conversational agent remains an open question.
Future work should focus on using these high-fidelity simulators to train and refine CRS agents from scratch, and measuring the resulting real-world performance. Closing this loop will finally allow us to quantify the degree of “human-likeness” needed to build effective, user-ready AI systems.
Acknowledgements
This research was conducted in collaboration with our co-authors: Krisztian Balog, Avi Caciularu, Guy Tennenholtz, Jihwan Jeong, Amir Globerson, and Craig Boutilier.
Quick links
Other posts of interest
-

May 19, 2026
Empirical Research Assistance (ERA): From Nature publication to catalyzing Computational Discovery- General Science ·
- Machine Intelligence ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

April 29, 2026
Four ways Google Research scientists have been using Empirical Research Assistance- Data Mining & Modeling ·
- General Science ·
- Generative AI ·
- Machine Intelligence
-

April 22, 2026
It's all about the angle: Your photos, re-composed- Generative AI ·
- Photography




